

Parallel computing
Encyclopedia
Parallel computing is a form of computation
in which many calculations are carried out simultaneously, operating on the principle that large problems can often be divided into smaller ones, which are then solved concurrently
("in parallel"). There are several different forms of parallel computing: bit-level
, instruction level
, data
, and task parallelism
. Parallelism has been employed for many years, mainly in high-performance computing, but interest in it has grown lately due to the physical constraints preventing frequency scaling
. As power consumption (and consequently heat generation) by computers has become a concern in recent years, parallel computing has become the dominant paradigm in computer architecture
, mainly in the form of multicore processor
s.
Parallel computers can be roughly classified according to the level at which the hardware supports parallelism, with multi-core and multi-processor
computers having multiple processing elements within a single machine, while clusters, MPPs, and grids
use multiple computers to work on the same task. Specialized parallel computer architectures are sometimes used alongside traditional processors, for accelerating specific tasks.
Parallel computer programs
are more difficult to write than sequential ones, because concurrency introduces several new classes of potential software bug
s, of which race condition
s are the most common. Communication and synchronization
between the different subtasks are typically some of the greatest obstacles to getting good parallel program performance.
The maximum possible speed-up of a program as a result of
parallelization
is observed as Amdahl's law
.
is constructed and implemented as a serial stream of instructions. These instructions are executed on a central processing unit
on one computer. Only one instruction may execute at a time—after that instruction is finished, the next is executed.
Parallel computing, on the other hand, uses multiple processing elements simultaneously to solve a problem. This is accomplished by breaking the problem into independent parts so that each processing element can execute its part of the algorithm simultaneously with the others. The processing elements can be diverse and include resources such as a single computer with multiple processors, several networked computers, specialized hardware, or any combination of the above.
Frequency scaling
was the dominant reason for improvements in computer performance from the mid-1980s until 2004. The runtime of a program is equal to the number of instructions multiplied by the average time per instruction. Maintaining everything else constant, increasing the clock frequency decreases the average time it takes to execute an instruction. An increase in frequency thus decreases runtime for all computation-bounded
programs.
However, power consumption by a chip is given by the equation P = C × V2 × F, where P is power, C is the capacitance
being switched per clock cycle (proportional to the number of transistors whose inputs change), V is voltage
, and F is the processor frequency (cycles per second). Increases in frequency increase the amount of power used in a processor. Increasing processor power consumption led ultimately to Intel's May 2004 cancellation of its Tejas and Jayhawk
processors, which is generally cited as the end of frequency scaling as the dominant computer architecture paradigm.
Moore's Law
is the empirical observation that transistor density in a microprocessor doubles every 18 to 24 months. Despite power consumption issues, and repeated predictions of its end, Moore's law is still in effect. With the end of frequency scaling, these additional transistors (which are no longer used for frequency scaling) can be used to add extra hardware for parallel computing.
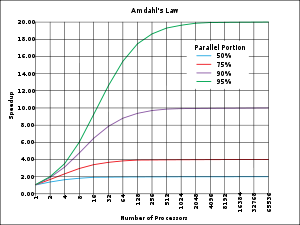 Optimally, the speed-up from parallelization would be linear—doubling the number of processing elements should halve the runtime, and doubling it a second time should again halve the runtime. However, very few parallel algorithms achieve optimal speed-up. Most of them have a near-linear speed-up for small numbers of processing elements, which flattens out into a constant value for large numbers of processing elements.
Optimally, the speed-up from parallelization would be linear—doubling the number of processing elements should halve the runtime, and doubling it a second time should again halve the runtime. However, very few parallel algorithms achieve optimal speed-up. Most of them have a near-linear speed-up for small numbers of processing elements, which flattens out into a constant value for large numbers of processing elements.
The potential speed-up of an algorithm on a parallel computing platform is given by Amdahl's law
, originally formulated by Gene Amdahl
in the 1960s. It states that a small portion of the program which cannot be parallelized will limit the overall speed-up available from parallelization. A program solving a large mathematical or engineering problem will typically consist of several parallelizable parts and several non-parallelizable (sequential) parts. If is the fraction of running time a sequential program spends on non-parallelizable parts, then
is the fraction of running time a sequential program spends on non-parallelizable parts, then
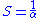
is the maximum speed-up with parallelization of the program. If the sequential portion of a program accounts for 10% of the runtime, we can get no more than a 10× speed-up, regardless of how many processors are added. This puts an upper limit on the usefulness of adding more parallel execution units. "When a task cannot be partitioned because of sequential constraints, the application of more effort has no effect on the schedule. The bearing of a child takes nine months, no matter how many women are assigned."
Gustafson's law
is another law in computing, closely related to Amdahl's law. It states that the speedup with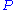 processors is
processors is

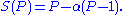
Amdahl's law assumes a fixed problem size and that the running time of the sequential section of the program is independent of the number of processors, whereas Gustafson's law does not make these assumptions.
is fundamental in implementing parallel algorithm
s. No program can run more quickly than the longest chain of dependent calculations (known as the critical path
), since calculations that depend upon prior calculations in the chain must be executed in order. However, most algorithms do not consist of just a long chain of dependent calculations; there are usually opportunities to execute independent calculations in parallel.
Let Pi and Pj be two program fragments. Bernstein's conditions describe when the two are independent and can be executed in parallel. For Pi, let Ii be all of the input variables and Oi the output variables, and likewise for Pj. P i and Pj are independent if they satisfy
Violation of the first condition introduces a flow dependency, corresponding to the first statement producing a result used by the second statement. The second condition represents an anti-dependency, when the second statement (Pj) would overwrite a variable needed by the first expression (Pi). The third and final condition represents an output dependency: When two statements write to the same location, the final result must come from the logically last executed statement.
Consider the following functions, which demonstrate several kinds of dependencies:
1: function Dep(a, b)
2: c := a·b
3: d := 3·c
4: end function
Operation 3 in Dep(a, b) cannot be executed before (or even in parallel with) operation 2, because operation 3 uses a result from operation 2. It violates condition 1, and thus introduces a flow dependency.
1: function NoDep(a, b)
2: c := a·b
3: d := 3·b
4: e := a+b
5: end function
In this example, there are no dependencies between the instructions, so they can all be run in parallel.
Bernstein’s conditions do not allow memory to be shared between different processes. For that, some means of enforcing an ordering between accesses is necessary, such as semaphores
, barriers
or some other synchronization method
.
. Some parallel computer architectures use smaller, lightweight versions of threads known as fibers
, while others use bigger versions known as processes
. However, "threads" is generally accepted as a generic term for subtasks. Threads will often need to update some variable
that is shared between them. The instructions between the two programs may be interleaved in any order. For example, consider the following program:
If instruction 1B is executed between 1A and 3A, or if instruction 1A is executed between 1B and 3B, the program will produce incorrect data. This is known as a race condition
. The programmer must use a lock
to provide mutual exclusion
. A lock is a programming language construct that allows one thread to take control of a variable and prevent other threads from reading or writing it, until that variable is unlocked. The thread holding the lock is free to execute its critical section
(the section of a program that requires exclusive access to some variable), and to unlock the data when it is finished. Therefore, to guarantee correct program execution, the above program can be rewritten to use locks:
One thread will successfully lock variable V, while the other thread will be locked out
—unable to proceed until V is unlocked again. This guarantees correct execution of the program. Locks, while necessary to ensure correct program execution, can greatly slow a program.
Locking multiple variables using non-atomic locks introduces the possibility of program deadlock
. An atomic lock locks multiple variables all at once. If it cannot lock all of them, it does not lock any of them. If two threads each need to lock the same two variables using non-atomic locks, it is possible that one thread will lock one of them and the second thread will lock the second variable. In such a case, neither thread can complete, and deadlock results.
Many parallel programs require that their subtasks act in synchrony
. This requires the use of a barrier
. Barriers are typically implemented using a software lock. One class of algorithms, known as lock-free and wait-free algorithms, altogether avoids the use of locks and barriers. However, this approach is generally difficult to implement and requires correctly designed data structures.
Not all parallelization results in speed-up. Generally, as a task is split up into more and more threads, those threads spend an ever-increasing portion of their time communicating with each other. Eventually, the overhead from communication dominates the time spent solving the problem, and further parallelization (that is, splitting the workload over even more threads) increases rather than decreases the amount of time required to finish. This is known as parallel slowdown
.
if they rarely or never have to communicate. Embarrassingly parallel applications are considered the easiest to parallelize.
(also known as a memory model). The consistency model defines rules for how operations on computer memory occur and how results are produced.
One of the first consistency models was Leslie Lamport
's sequential consistency
model. Sequential consistency is the property of a parallel program that its parallel execution produces the same results as a sequential program. Specifically, a program is sequentially consistent if "... the results of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program".
Software transactional memory
is a common type of consistency model. Software transactional memory borrows from database theory
the concept of atomic transactions
and applies them to memory accesses.
Mathematically, these models can be represented in several ways. Petri net
s, which were introduced in Carl Adam Petri's 1962 doctoral thesis, were an early attempt to codify the rules of consistency models. Dataflow theory later built upon these, and Dataflow architecture
s were created to physically implement the ideas of dataflow theory. Beginning in the late 1970s, process calculi such as Calculus of Communicating Systems
and Communicating Sequential Processes
were developed to permit algebraic reasoning about systems composed of interacting components. More recent additions to the process calculus family, such as the π-calculus, have added the capability for reasoning about dynamic topologies. Logics such as Lamport's TLA+
, and mathematical models such as traces
and Actor event diagrams
, have also been developed to describe the behavior of concurrent systems.
created one of the earliest classification systems for parallel (and sequential) computers and programs, now known as Flynn's taxonomy
. Flynn classified programs and computers by whether they were operating using a single set or multiple sets of instructions, whether or not those instructions were using a single or multiple sets of data.
The single-instruction-single-data (SISD) classification is equivalent to an entirely sequential program. The single-instruction-multiple-data (SIMD) classification is analogous to doing the same operation repeatedly over a large data set. This is commonly done in signal processing
applications. Multiple-instruction-single-data (MISD) is a rarely used classification. While computer architectures to deal with this were devised (such as systolic array
s), few applications that fit this class materialized. Multiple-instruction-multiple-data (MIMD) programs are by far the most common type of parallel programs.
According to David A. Patterson and John L. Hennessy
, "Some machines are hybrids of these categories, of course, but this classic model has survived because it is simple, easy to understand, and gives a good first approximation. It is also—perhaps because of its understandability—the most widely used scheme."
(VLSI) computer-chip fabrication technology in the 1970s until about 1986, speed-up in computer architecture was driven by doubling computer word size—the amount of information the processor can manipulate per cycle. Increasing the word size reduces the number of instructions the processor must execute to perform an operation on variables whose sizes are greater than the length of the word. For example, where an 8-bit
processor must add two 16-bit
integer
s, the processor must first add the 8 lower-order bits from each integer using the standard addition instruction, then add the 8 higher-order bits using an add-with-carry instruction and the carry bit from the lower order addition; thus, an 8-bit processor requires two instructions to complete a single operation, where a 16-bit processor would be able to complete the operation with a single instruction.
Historically, 4-bit
microprocessors were replaced with 8-bit, then 16-bit, then 32-bit microprocessors. This trend generally came to an end with the introduction of 32-bit processors, which has been a standard in general-purpose computing for two decades. Not until recently (c. 2003–2004), with the advent of x86-64
architectures, have 64-bit
processors become commonplace.
 A computer program is, in essence, a stream of instructions executed by a processor. These instructions can be re-ordered
A computer program is, in essence, a stream of instructions executed by a processor. These instructions can be re-ordered
and combined into groups which are then executed in parallel without changing the result of the program. This is known as instruction-level parallelism. Advances in instruction-level parallelism dominated computer architecture from the mid-1980s until the mid-1990s.
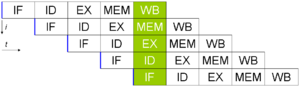
Modern processors have multi-stage instruction pipeline
s. Each stage in the pipeline corresponds to a different action the processor performs on that instruction in that stage; a processor with an N-stage pipeline can have up to N different instructions at different stages of completion. The canonical example of a pipelined processor is a RISC
processor, with five stages: instruction fetch, decode, execute, memory access, and write back. The Pentium 4
processor had a 35-stage pipeline.
In addition to instruction-level parallelism from pipelining, some processors can issue more than one instruction at a time. These are known as superscalar
processors. Instructions can be grouped together only if there is no data dependency
between them. Scoreboarding
and the Tomasulo algorithm
(which is similar to scoreboarding but makes use of register renaming
) are two of the most common techniques for implementing out-of-order execution and instruction-level parallelism .
A loop-carried dependency is the dependence of a loop iteration on the output of one or more previous iterations. Loop-carried dependencies prevent the parallelization of loops. For example, consider the following pseudocode
that computes the first few Fibonacci number
s:
1: PREV1 := 0
2: PREV2 := 1
4: do:
5: CUR := PREV1 + PREV2
6: PREV1 := PREV2
7: PREV2 := CUR
8: while (CUR < 10)
This loop cannot be parallelized because CUR depends on itself (PREV2) and PREV1, which are computed in each loop iteration. Since each iteration depends on the result of the previous one, they cannot be performed in parallel. As the size of a problem gets bigger, the amount of data-parallelism available usually does as well.
(shared between all processing elements in a single address space
), or distributed memory
(in which each processing element has its own local address space). Distributed memory refers to the fact that the memory is logically distributed, but often implies that it is physically distributed as well. Distributed shared memory
and memory virtualization
combine the two approaches, where the processing element has its own local memory and access to the memory on non-local processors. Accesses to local memory are typically faster than accesses to non-local memory.
Computer architectures in which each element of main memory can be accessed with equal latency and bandwidth
are known as Uniform Memory Access
(UMA) systems. Typically, that can be achieved only by a shared memory
system, in which the memory is not physically distributed. A system that does not have this property is known as a Non-Uniform Memory Access
(NUMA) architecture. Distributed memory systems have non-uniform memory access.
Computer systems make use of cache
s—small, fast memories located close to the processor which store temporary copies of memory values (nearby in both the physical and logical sense). Parallel computer systems have difficulties with caches that may store the same value in more than one location, with the possibility of incorrect program execution. These computers require a cache coherency
system, which keeps track of cached values and strategically purges them, thus ensuring correct program execution. Bus snooping
is one of the most common methods for keeping track of which values are being accessed (and thus should be purged). Designing large, high-performance cache coherence systems is a very difficult problem in computer architecture. As a result, shared-memory computer architectures do not scale as well as distributed memory systems do.
Processor–processor and processor–memory communication can be implemented in hardware in several ways, including via shared (either multiported or multiplexed
) memory, a crossbar switch
, a shared bus or an interconnect network of a myriad of topologies
including star
, ring
, tree
, hypercube, fat hypercube (a hypercube with more than one processor at a node), or n-dimensional mesh
.
Parallel computers based on interconnect networks need to have some kind of routing
to enable the passing of messages between nodes that are not directly connected. The medium used for communication between the processors is likely to be hierarchical in large multiprocessor machines.
s ("cores") on the same chip. These processors differ from superscalar processors, which can issue multiple instructions per cycle from one instruction stream (thread); in contrast, a multicore processor can issue multiple instructions per cycle from multiple instruction streams. Each core in a multicore processor can potentially be superscalar as well—that is, on every cycle, each core can issue multiple instructions from one instruction stream.
Simultaneous multithreading
(of which Intel's HyperThreading is the best known) was an early form of pseudo-multicoreism. A processor capable of simultaneous multithreading has only one execution unit ("core"), but when that execution unit is idling (such as during a cache miss), it uses that execution unit to process a second thread. IBM
's Cell microprocessor
, designed for use in the Sony
PlayStation 3
, is another prominent multicore processor.
prevents bus architectures from scaling. As a result, SMPs generally do not comprise more than 32 processors. "Because of the small size of the processors and the significant reduction in the requirements for bus bandwidth achieved by large caches, such symmetric multiprocessors are extremely cost-effective, provided that a sufficient amount of memory bandwidth exists."
 A cluster is a group of loosely coupled computers that work together closely, so that in some respects they can be regarded as a single computer. Clusters are composed of multiple standalone machines connected by a network. While machines in a cluster do not have to be symmetric, load balancing
A cluster is a group of loosely coupled computers that work together closely, so that in some respects they can be regarded as a single computer. Clusters are composed of multiple standalone machines connected by a network. While machines in a cluster do not have to be symmetric, load balancing
is more difficult if they are not. The most common type of cluster is the Beowulf cluster
, which is a cluster implemented on multiple identical commercial off-the-shelf
computers connected with a TCP/IP Ethernet
local area network
. Beowulf technology was originally developed by Thomas Sterling
and Donald Becker
. The vast majority of the TOP500
supercomputers are clusters.
A massively parallel processor (MPP) is a single computer with many networked processors. MPPs have many of the same characteristics as clusters, but MPPs have specialized interconnect networks (whereas clusters use commodity hardware for networking). MPPs also tend to be larger than clusters, typically having "far more" than 100 processors. In an MPP, "each CPU contains its own memory and copy of the operating system and application. Each subsystem communicates with the others via a high-speed interconnect."
 Blue Gene/L, the fifth fastest supercomputer in the world according to the June 2009 TOP500 ranking, is an MPP.
Blue Gene/L, the fifth fastest supercomputer in the world according to the June 2009 TOP500 ranking, is an MPP.
Grid computing is the most distributed form of parallel computing. It makes use of computers communicating over the Internet
to work on a given problem. Because of the low bandwidth and extremely high latency available on the Internet, grid computing typically deals only with embarrassingly parallel
problems. Many grid computing applications have been created, of which SETI@home
and Folding@Home
are the best-known examples.
Most grid computing applications use middleware
, software that sits between the operating system and the application to manage network resources and standardize the software interface. The most common grid computing middleware is the Berkeley Open Infrastructure for Network Computing
(BOINC). Often, grid computing software makes use of "spare cycles", performing computations at times when a computer is idling.
, they tend to be applicable to only a few classes of parallel problems.
Reconfigurable computing
is the use of a field-programmable gate array
(FPGA) as a co-processor to a general-purpose computer. An FPGA is, in essence, a computer chip that can rewire itself for a given task.
FPGAs can be programmed with hardware description language
s such as VHDL or Verilog
. However, programming in these languages can be tedious. Several vendors have created C to HDL
languages that attempt to emulate the syntax and/or semantics of the C programming language, with which most programmers are familiar. The best known C to HDL languages are Mitrion-C, Impulse C
, DIME-C
, and Handel-C
. Specific subsets of SystemC
based on C++ can also be used for this purpose.
AMD's decision to open its HyperTransport
technology to third-party vendors has become the enabling technology for high-performance reconfigurable computing. According to Michael R. D'Amour, Chief Operating Officer of DRC Computer Corporation, "when we first walked into AMD, they called us 'the socket
stealers.' Now they call us their partners."
 General-purpose computing on graphics processing unit
General-purpose computing on graphics processing unit
s (GPGPU) is a fairly recent trend in computer engineering research. GPUs are co-processors that have been heavily optimized for computer graphics
processing. Computer graphics processing is a field dominated by data parallel operations—particularly linear algebra
matrix
operations.
In the early days, GPGPU programs used the normal graphics APIs for executing programs. However, several new programming languages and platforms have been built to do general purpose computation on GPUs with both Nvidia
and AMD releasing programming environments with CUDA
and CTM
respectively. Other GPU programming languages are BrookGPU
, PeakStream
, and RapidMind
. Nvidia has also released specific products for computation in their Tesla series
. The technology consortium Khronos Group has released the OpenCL
specification, which is a framework for writing programs that execute across platforms consisting of CPUs and GPUs. Apple, Intel, Nvidia
and others are supporting OpenCL
.
Several application-specific integrated circuit
(ASIC) approaches have been devised for dealing with parallel applications.
Because an ASIC is (by definition) specific to a given application, it can be fully optimized for that application. As a result, for a given application, an ASIC tends to outperform a general-purpose computer. However, ASICs are created by X-ray lithography
. This process requires a mask, which can be extremely expensive. A single mask can cost over a million US dollars. (The smaller the transistors required for the chip, the more expensive the mask will be.) Meanwhile, performance increases in general-purpose computing over time (as described by Moore's Law) tend to wipe out these gains in only one or two chip generations. High initial cost, and the tendency to be overtaken by Moore's-law-driven general-purpose computing, has rendered ASICs unfeasible for most parallel computing applications. However, some have been built. One example is the peta-flop RIKEN MDGRAPE-3
machine which uses custom ASICs for molecular dynamics
simulation.
A vector processor is a CPU or computer system that can execute the same instruction on large sets of data. "Vector processors have high-level operations that work on linear arrays of numbers or vectors. An example vector operation is A = B × C, where A, B, and C are each 64-element vectors of 64-bit floating-point
numbers." They are closely related to Flynn's SIMD classification.
Cray
computers became famous for their vector-processing computers in the 1970s and 1980s. However, vector processors—both as CPUs and as full computer systems—have generally disappeared. Modern processor instruction sets
do include some vector processing instructions, such as with AltiVec
and Streaming SIMD Extensions
(SSE).
Computing
Computing is usually defined as the activity of using and improving computer hardware and software. It is the computer-specific part of information technology...
in which many calculations are carried out simultaneously, operating on the principle that large problems can often be divided into smaller ones, which are then solved concurrently
Concurrency (computer science)
In computer science, concurrency is a property of systems in which several computations are executing simultaneously, and potentially interacting with each other...
("in parallel"). There are several different forms of parallel computing: bit-level
Bit-level parallelism
Bit-level parallelism is a form of parallel computing based on increasing processor word size. From the advent of very-large-scale integration computer chip fabrication technology in the 1970s until about 1986, advancements in computer architecture were done by increasing bit-level...
, instruction level
Instruction level parallelism
Instruction-level parallelism is a measure of how many of the operations in a computer program can be performed simultaneously. Consider the following program: 1. e = a + b 2. f = c + d 3. g = e * f...
, data
Data parallelism
Data parallelism is a form of parallelization of computing across multiple processors in parallel computing environments. Data parallelism focuses on distributing the data across different parallel computing nodes...
, and task parallelism
Task parallelism
Task parallelism is a form of parallelization of computer code across multiple processors in parallel computing environments. Task parallelism focuses on distributing execution processes across different parallel computing nodes...
. Parallelism has been employed for many years, mainly in high-performance computing, but interest in it has grown lately due to the physical constraints preventing frequency scaling
Frequency scaling
In computer architecture, frequency scaling is the technique of ramping a processor's frequency so as to achieve performance gains...
. As power consumption (and consequently heat generation) by computers has become a concern in recent years, parallel computing has become the dominant paradigm in computer architecture
Computer architecture
In computer science and engineering, computer architecture is the practical art of selecting and interconnecting hardware components to create computers that meet functional, performance and cost goals and the formal modelling of those systems....
, mainly in the form of multicore processor
Multi-core (computing)
A multi-core processor is a single computing component with two or more independent actual processors , which are the units that read and execute program instructions...
s.
Parallel computers can be roughly classified according to the level at which the hardware supports parallelism, with multi-core and multi-processor
Symmetric multiprocessing
In computing, symmetric multiprocessing involves a multiprocessor computer hardware architecture where two or more identical processors are connected to a single shared main memory and are controlled by a single OS instance. Most common multiprocessor systems today use an SMP architecture...
computers having multiple processing elements within a single machine, while clusters, MPPs, and grids
Grid computing
Grid computing is a term referring to the combination of computer resources from multiple administrative domains to reach a common goal. The grid can be thought of as a distributed system with non-interactive workloads that involve a large number of files...
use multiple computers to work on the same task. Specialized parallel computer architectures are sometimes used alongside traditional processors, for accelerating specific tasks.
Parallel computer programs
Parallel algorithm
In computer science, a parallel algorithm or concurrent algorithm, as opposed to a traditional sequential algorithm, is an algorithm which can be executed a piece at a time on many different processing devices, and then put back together again at the end to get the correct result.Some algorithms...
are more difficult to write than sequential ones, because concurrency introduces several new classes of potential software bug
Software bug
A software bug is the common term used to describe an error, flaw, mistake, failure, or fault in a computer program or system that produces an incorrect or unexpected result, or causes it to behave in unintended ways. Most bugs arise from mistakes and errors made by people in either a program's...
s, of which race condition
Race condition
A race condition or race hazard is a flaw in an electronic system or process whereby the output or result of the process is unexpectedly and critically dependent on the sequence or timing of other events...
s are the most common. Communication and synchronization
Synchronization (computer science)
In computer science, synchronization refers to one of two distinct but related concepts: synchronization of processes, and synchronization of data. Process synchronization refers to the idea that multiple processes are to join up or handshake at a certain point, so as to reach an agreement or...
between the different subtasks are typically some of the greatest obstacles to getting good parallel program performance.
The maximum possible speed-up of a program as a result of
parallelization
is observed as Amdahl's law
Amdahl's law
Amdahl's law, also known as Amdahl's argument, is named after computer architect Gene Amdahl, and is used to find the maximum expected improvement to an overall system when only part of the system is improved...
.
Background
Traditionally, computer software has been written for serial computation. To solve a problem, an algorithmAlgorithm
In mathematics and computer science, an algorithm is an effective method expressed as a finite list of well-defined instructions for calculating a function. Algorithms are used for calculation, data processing, and automated reasoning...
is constructed and implemented as a serial stream of instructions. These instructions are executed on a central processing unit
Central processing unit
The central processing unit is the portion of a computer system that carries out the instructions of a computer program, to perform the basic arithmetical, logical, and input/output operations of the system. The CPU plays a role somewhat analogous to the brain in the computer. The term has been in...
on one computer. Only one instruction may execute at a time—after that instruction is finished, the next is executed.
Parallel computing, on the other hand, uses multiple processing elements simultaneously to solve a problem. This is accomplished by breaking the problem into independent parts so that each processing element can execute its part of the algorithm simultaneously with the others. The processing elements can be diverse and include resources such as a single computer with multiple processors, several networked computers, specialized hardware, or any combination of the above.
Frequency scaling
Frequency scaling
In computer architecture, frequency scaling is the technique of ramping a processor's frequency so as to achieve performance gains...
was the dominant reason for improvements in computer performance from the mid-1980s until 2004. The runtime of a program is equal to the number of instructions multiplied by the average time per instruction. Maintaining everything else constant, increasing the clock frequency decreases the average time it takes to execute an instruction. An increase in frequency thus decreases runtime for all computation-bounded
CPU bound
In computer science, CPU bound is when the time for a computer to complete a task is determined principally by the speed of the central processor: processor utilization is high, perhaps at 100% usage for many seconds or minutes...
programs.
However, power consumption by a chip is given by the equation P = C × V2 × F, where P is power, C is the capacitance
Capacitance
In electromagnetism and electronics, capacitance is the ability of a capacitor to store energy in an electric field. Capacitance is also a measure of the amount of electric potential energy stored for a given electric potential. A common form of energy storage device is a parallel-plate capacitor...
being switched per clock cycle (proportional to the number of transistors whose inputs change), V is voltage
Voltage
Voltage, otherwise known as electrical potential difference or electric tension is the difference in electric potential between two points — or the difference in electric potential energy per unit charge between two points...
, and F is the processor frequency (cycles per second). Increases in frequency increase the amount of power used in a processor. Increasing processor power consumption led ultimately to Intel's May 2004 cancellation of its Tejas and Jayhawk
Tejas and Jayhawk
Tejas was a code name for Intel's microprocessor which was to be a successor to the latest Pentium 4 with the Prescott core. Jayhawk was a code name for its Xeon counterpart...
processors, which is generally cited as the end of frequency scaling as the dominant computer architecture paradigm.
Moore's Law
Moore's Law
Moore's law describes a long-term trend in the history of computing hardware: the number of transistors that can be placed inexpensively on an integrated circuit doubles approximately every two years....
is the empirical observation that transistor density in a microprocessor doubles every 18 to 24 months. Despite power consumption issues, and repeated predictions of its end, Moore's law is still in effect. With the end of frequency scaling, these additional transistors (which are no longer used for frequency scaling) can be used to add extra hardware for parallel computing.
Amdahl's law and Gustafson's law
The potential speed-up of an algorithm on a parallel computing platform is given by Amdahl's law
Amdahl's law
Amdahl's law, also known as Amdahl's argument, is named after computer architect Gene Amdahl, and is used to find the maximum expected improvement to an overall system when only part of the system is improved...
, originally formulated by Gene Amdahl
Gene Amdahl
Gene Myron Amdahl is a Norwegian-American computer architect and high-tech entrepreneur, chiefly known for his work on mainframe computers at IBM and later his own companies, especially Amdahl Corporation...
in the 1960s. It states that a small portion of the program which cannot be parallelized will limit the overall speed-up available from parallelization. A program solving a large mathematical or engineering problem will typically consist of several parallelizable parts and several non-parallelizable (sequential) parts. If
is the fraction of running time a sequential program spends on non-parallelizable parts, thenis the maximum speed-up with parallelization of the program. If the sequential portion of a program accounts for 10% of the runtime, we can get no more than a 10× speed-up, regardless of how many processors are added. This puts an upper limit on the usefulness of adding more parallel execution units. "When a task cannot be partitioned because of sequential constraints, the application of more effort has no effect on the schedule. The bearing of a child takes nine months, no matter how many women are assigned."
Gustafson's law
Gustafson's law
Gustafson's Law is a law in computer science which says that problems with large, repetitive data sets can be efficiently parallelized. Gustafson's Law contradicts Amdahl's law, which describes a limit on the speed-up that parallelization can provide. Gustafson's law was first described by John...
is another law in computing, closely related to Amdahl's law. It states that the speedup with
processors isAmdahl's law assumes a fixed problem size and that the running time of the sequential section of the program is independent of the number of processors, whereas Gustafson's law does not make these assumptions.
Dependencies
Understanding data dependenciesData dependency
A data dependency in computer science is a situation in which a program statement refers to the data of a preceding statement. In compiler theory, the technique used to discover data dependencies among statements is called dependence analysis.There are three types of dependencies: data, name, and...
is fundamental in implementing parallel algorithm
Parallel algorithm
In computer science, a parallel algorithm or concurrent algorithm, as opposed to a traditional sequential algorithm, is an algorithm which can be executed a piece at a time on many different processing devices, and then put back together again at the end to get the correct result.Some algorithms...
s. No program can run more quickly than the longest chain of dependent calculations (known as the critical path
Critical path method
The critical path method is an algorithm for scheduling a set of project activities. It is an important tool for effective project management.-History:...
), since calculations that depend upon prior calculations in the chain must be executed in order. However, most algorithms do not consist of just a long chain of dependent calculations; there are usually opportunities to execute independent calculations in parallel.
Let Pi and Pj be two program fragments. Bernstein's conditions describe when the two are independent and can be executed in parallel. For Pi, let Ii be all of the input variables and Oi the output variables, and likewise for Pj. P i and Pj are independent if they satisfy



Violation of the first condition introduces a flow dependency, corresponding to the first statement producing a result used by the second statement. The second condition represents an anti-dependency, when the second statement (Pj) would overwrite a variable needed by the first expression (Pi). The third and final condition represents an output dependency: When two statements write to the same location, the final result must come from the logically last executed statement.
Consider the following functions, which demonstrate several kinds of dependencies:
1: function Dep(a, b)
2: c := a·b
3: d := 3·c
4: end function
Operation 3 in Dep(a, b) cannot be executed before (or even in parallel with) operation 2, because operation 3 uses a result from operation 2. It violates condition 1, and thus introduces a flow dependency.
1: function NoDep(a, b)
2: c := a·b
3: d := 3·b
4: e := a+b
5: end function
In this example, there are no dependencies between the instructions, so they can all be run in parallel.
Bernstein’s conditions do not allow memory to be shared between different processes. For that, some means of enforcing an ordering between accesses is necessary, such as semaphores
Semaphore (programming)
In computer science, a semaphore is a variable or abstract data type that provides a simple but useful abstraction for controlling access by multiple processes to a common resource in a parallel programming environment....
, barriers
Barrier (computer science)
- Threads synchronization primitive :In parallel computing, a barrier is a type of synchronization method. A barrier for a group of threads or processes in the source code means any thread/process must stop at this point and cannot proceed until all other threads/processes reach this barrier.Many...
or some other synchronization method
Synchronization (computer science)
In computer science, synchronization refers to one of two distinct but related concepts: synchronization of processes, and synchronization of data. Process synchronization refers to the idea that multiple processes are to join up or handshake at a certain point, so as to reach an agreement or...
.
Race conditions, mutual exclusion, synchronization, and parallel slowdown
Subtasks in a parallel program are often called threadsThread (computer science)
In computer science, a thread of execution is the smallest unit of processing that can be scheduled by an operating system. The implementation of threads and processes differs from one operating system to another, but in most cases, a thread is contained inside a process...
. Some parallel computer architectures use smaller, lightweight versions of threads known as fibers
Fiber (computer science)
In computer science, a fiber is a particularly lightweight thread of execution.Like threads, fibers share address space. However, fibers use co-operative multitasking while threads use pre-emptive multitasking. Threads often depend on the kernel's thread scheduler to preempt a busy thread and...
, while others use bigger versions known as processes
Process (computing)
In computing, a process is an instance of a computer program that is being executed. It contains the program code and its current activity. Depending on the operating system , a process may be made up of multiple threads of execution that execute instructions concurrently.A computer program is a...
. However, "threads" is generally accepted as a generic term for subtasks. Threads will often need to update some variable
Variable (programming)
In computer programming, a variable is a symbolic name given to some known or unknown quantity or information, for the purpose of allowing the name to be used independently of the information it represents...
that is shared between them. The instructions between the two programs may be interleaved in any order. For example, consider the following program:
| Thread A | Thread B |
| 1A: Read variable V | 1B: Read variable V |
| 2A: Add 1 to variable V | 2B: Add 1 to variable V |
| 3A Write back to variable V | 3B: Write back to variable V |
If instruction 1B is executed between 1A and 3A, or if instruction 1A is executed between 1B and 3B, the program will produce incorrect data. This is known as a race condition
Race condition
A race condition or race hazard is a flaw in an electronic system or process whereby the output or result of the process is unexpectedly and critically dependent on the sequence or timing of other events...
. The programmer must use a lock
Lock (computer science)
In computer science, a lock is a synchronization mechanism for enforcing limits on access to a resource in an environment where there are many threads of execution. Locks are one way of enforcing concurrency control policies.-Types:...
to provide mutual exclusion
Mutual exclusion
Mutual exclusion algorithms are used in concurrent programming to avoid the simultaneous use of a common resource, such as a global variable, by pieces of computer code called critical sections. A critical section is a piece of code in which a process or thread accesses a common resource...
. A lock is a programming language construct that allows one thread to take control of a variable and prevent other threads from reading or writing it, until that variable is unlocked. The thread holding the lock is free to execute its critical section
Critical section
In concurrent programming a critical section is a piece of code that accesses a shared resource that must not be concurrently accessed by more than one thread of execution. A critical section will usually terminate in fixed time, and a thread, task or process will have to wait a fixed time to...
(the section of a program that requires exclusive access to some variable), and to unlock the data when it is finished. Therefore, to guarantee correct program execution, the above program can be rewritten to use locks:
| Thread A | Thread B |
| 1A: Lock variable V | 1B: Lock variable V |
| 2A: Read variable V | 2B: Read variable V |
| 3A: Add 1 to variable V | 3B: Add 1 to variable V |
| 4A Write back to variable V | 4B: Write back to variable V |
| 5A: Unlock variable V | 5B: Unlock variable V |
One thread will successfully lock variable V, while the other thread will be locked out
Software lockout
In multiprocessor computer systems, software lockout is the issue of performance degradation due to the idle wait times spent by the CPUs in kernel-level critical sections. Software lockout is the major cause of scalability degradation in a multiprocessor system, posing a limit on the maximum...
—unable to proceed until V is unlocked again. This guarantees correct execution of the program. Locks, while necessary to ensure correct program execution, can greatly slow a program.
Locking multiple variables using non-atomic locks introduces the possibility of program deadlock
Deadlock
A deadlock is a situation where in two or more competing actions are each waiting for the other to finish, and thus neither ever does. It is often seen in a paradox like the "chicken or the egg"...
. An atomic lock locks multiple variables all at once. If it cannot lock all of them, it does not lock any of them. If two threads each need to lock the same two variables using non-atomic locks, it is possible that one thread will lock one of them and the second thread will lock the second variable. In such a case, neither thread can complete, and deadlock results.
Many parallel programs require that their subtasks act in synchrony
Synchronization (computer science)
In computer science, synchronization refers to one of two distinct but related concepts: synchronization of processes, and synchronization of data. Process synchronization refers to the idea that multiple processes are to join up or handshake at a certain point, so as to reach an agreement or...
. This requires the use of a barrier
Barrier (computer science)
- Threads synchronization primitive :In parallel computing, a barrier is a type of synchronization method. A barrier for a group of threads or processes in the source code means any thread/process must stop at this point and cannot proceed until all other threads/processes reach this barrier.Many...
. Barriers are typically implemented using a software lock. One class of algorithms, known as lock-free and wait-free algorithms, altogether avoids the use of locks and barriers. However, this approach is generally difficult to implement and requires correctly designed data structures.
Not all parallelization results in speed-up. Generally, as a task is split up into more and more threads, those threads spend an ever-increasing portion of their time communicating with each other. Eventually, the overhead from communication dominates the time spent solving the problem, and further parallelization (that is, splitting the workload over even more threads) increases rather than decreases the amount of time required to finish. This is known as parallel slowdown
Parallel slowdown
Parallel slowdown is a phenomenon in parallel computing where parallelization of a parallel computer program beyond a certain point causes the program to run slower ....
.
Fine-grained, coarse-grained, and embarrassing parallelism
Applications are often classified according to how often their subtasks need to synchronize or communicate with each other. An application exhibits fine-grained parallelism if its subtasks must communicate many times per second; it exhibits coarse-grained parallelism if they do not communicate many times per second, and it is embarrassingly parallelEmbarrassingly parallel
In parallel computing, an embarrassingly parallel workload is one for which little or no effort is required to separate the problem into a number of parallel tasks...
if they rarely or never have to communicate. Embarrassingly parallel applications are considered the easiest to parallelize.
Consistency models
Parallel programming languages and parallel computers must have a consistency modelConsistency model
In computer science, consistency models are used in distributed systems like distributed shared memory systems or distributed data stores . The system supports a given model, if operations on memory follow specific rules...
(also known as a memory model). The consistency model defines rules for how operations on computer memory occur and how results are produced.
One of the first consistency models was Leslie Lamport
Leslie Lamport
Leslie Lamport is an American computer scientist. A graduate of the Bronx High School of Science, he received a B.S. in mathematics from the Massachusetts Institute of Technology in 1960, and M.A. and Ph.D. degrees in mathematics from Brandeis University, respectively in 1963 and 1972...
's sequential consistency
Sequential consistency
Sequential consistency is one of the consistency models used in the domain of concurrent programming . It was first defined as the property that requires that ".....
model. Sequential consistency is the property of a parallel program that its parallel execution produces the same results as a sequential program. Specifically, a program is sequentially consistent if "... the results of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program".
Software transactional memory
Software transactional memory
In computer science, software transactional memory is a concurrency control mechanism analogous to database transactions for controlling access to shared memory in concurrent computing. It is an alternative to lock-based synchronization. A transaction in this context is a piece of code that...
is a common type of consistency model. Software transactional memory borrows from database theory
Database management system
A database management system is a software package with computer programs that control the creation, maintenance, and use of a database. It allows organizations to conveniently develop databases for various applications by database administrators and other specialists. A database is an integrated...
the concept of atomic transactions
Atomic commit
An atomic commit is an operation in which a set of distinct changes is applied as a single operation. If the changes are applied then the atomic commit is said to have succeeded. If there is a failure before the atomic commit can be completed then all of the changes completed in the atomic commit...
and applies them to memory accesses.
Mathematically, these models can be represented in several ways. Petri net
Petri net
A Petri net is one of several mathematical modeling languages for the description of distributed systems. A Petri net is a directed bipartite graph, in which the nodes represent transitions and places...
s, which were introduced in Carl Adam Petri's 1962 doctoral thesis, were an early attempt to codify the rules of consistency models. Dataflow theory later built upon these, and Dataflow architecture
Dataflow architecture
Dataflow architecture is a computer architecture that directly contrasts the traditional von Neumann architecture or control flow architecture. Dataflow architectures do not have a program counter, or the executability and execution of instructions is solely determined based on the availability of...
s were created to physically implement the ideas of dataflow theory. Beginning in the late 1970s, process calculi such as Calculus of Communicating Systems
Calculus of Communicating Systems
The Calculus of Communicating Systems is a process calculus introduced by Robin Milner around 1980 and the title of a book describing the calculus. Its actions model indivisible communications between exactly two participants. The formal language includes primitives for describing parallel...
and Communicating Sequential Processes
Communicating sequential processes
In computer science, Communicating Sequential Processes is a formal language for describing patterns of interaction in concurrent systems. It is a member of the family of mathematical theories of concurrency known as process algebras, or process calculi...
were developed to permit algebraic reasoning about systems composed of interacting components. More recent additions to the process calculus family, such as the π-calculus, have added the capability for reasoning about dynamic topologies. Logics such as Lamport's TLA+
Temporal Logic of Actions
Temporal logic of actions is a logic developed by Leslie Lamport, which combines temporal logic with a logic of actions.It is used to describe behaviours of concurrent systems.- Details :...
, and mathematical models such as traces
Trace theory
In mathematics and computer science, trace theory aims to provide a concrete mathematical underpinning for the study of concurrent computation and process calculi...
and Actor event diagrams
Actor model theory
In theoretical computer science, Actor model theory concerns theoretical issues for the Actor model.Actors are the primitives that form the basis of the Actor model of concurrent digital computation. In response to a message that it receives, an Actor can make local decisions, create more Actors,...
, have also been developed to describe the behavior of concurrent systems.
Flynn's taxonomy
Michael J. FlynnMichael J. Flynn
Michael J. Flynn is an American professor emeritus at Stanford University. He co-founded Palyn Associates with Max Paley and is Chairman of Maxeler Technologies. He proposed Flynn's taxonomy in 1966....
created one of the earliest classification systems for parallel (and sequential) computers and programs, now known as Flynn's taxonomy
Flynn's Taxonomy
Flynn's taxonomy is a classification of computer architectures, proposed by Michael J. Flynn in 1966.-Classifications:The four classifications defined by Flynn are based upon the number of concurrent instruction and data streams available in the architecture:Single Instruction, Single Data stream...
. Flynn classified programs and computers by whether they were operating using a single set or multiple sets of instructions, whether or not those instructions were using a single or multiple sets of data.
The single-instruction-single-data (SISD) classification is equivalent to an entirely sequential program. The single-instruction-multiple-data (SIMD) classification is analogous to doing the same operation repeatedly over a large data set. This is commonly done in signal processing
Signal processing
Signal processing is an area of systems engineering, electrical engineering and applied mathematics that deals with operations on or analysis of signals, in either discrete or continuous time...
applications. Multiple-instruction-single-data (MISD) is a rarely used classification. While computer architectures to deal with this were devised (such as systolic array
Systolic array
In computer architecture, a systolic array is a pipe network arrangement of processing units called cells. It is a specialized form of parallel computing, where cells , compute data and store it independently of each other.thumb|240px...
s), few applications that fit this class materialized. Multiple-instruction-multiple-data (MIMD) programs are by far the most common type of parallel programs.
According to David A. Patterson and John L. Hennessy
John L. Hennessy
John LeRoy Hennessy is an American computer scientist and academician. Hennessy is one of the founders of MIPS Computer Systems Inc. and is the 10th President of Stanford University.-Background:...
, "Some machines are hybrids of these categories, of course, but this classic model has survived because it is simple, easy to understand, and gives a good first approximation. It is also—perhaps because of its understandability—the most widely used scheme."
Bit-level parallelism
From the advent of very-large-scale integrationVery-large-scale integration
Very-large-scale integration is the process of creating integrated circuits by combining thousands of transistors into a single chip. VLSI began in the 1970s when complex semiconductor and communication technologies were being developed. The microprocessor is a VLSI device.The first semiconductor...
(VLSI) computer-chip fabrication technology in the 1970s until about 1986, speed-up in computer architecture was driven by doubling computer word size—the amount of information the processor can manipulate per cycle. Increasing the word size reduces the number of instructions the processor must execute to perform an operation on variables whose sizes are greater than the length of the word. For example, where an 8-bit
8-bit
The first widely adopted 8-bit microprocessor was the Intel 8080, being used in many hobbyist computers of the late 1970s and early 1980s, often running the CP/M operating system. The Zilog Z80 and the Motorola 6800 were also used in similar computers...
processor must add two 16-bit
16-bit
-16-bit architecture:The HP BPC, introduced in 1975, was the world's first 16-bit microprocessor. Prominent 16-bit processors include the PDP-11, Intel 8086, Intel 80286 and the WDC 65C816. The Intel 8088 was program-compatible with the Intel 8086, and was 16-bit in that its registers were 16...
integer
Integer
The integers are formed by the natural numbers together with the negatives of the non-zero natural numbers .They are known as Positive and Negative Integers respectively...
s, the processor must first add the 8 lower-order bits from each integer using the standard addition instruction, then add the 8 higher-order bits using an add-with-carry instruction and the carry bit from the lower order addition; thus, an 8-bit processor requires two instructions to complete a single operation, where a 16-bit processor would be able to complete the operation with a single instruction.
Historically, 4-bit
4-bit
The Intel 4004, the world's first commercially available single-chip microprocessor, was a 4-bit CPU. The F-14 Tomcat's Central Air Data Computer was created a year before the 4004, but its existence was classified by the United States Navy until 1997...
microprocessors were replaced with 8-bit, then 16-bit, then 32-bit microprocessors. This trend generally came to an end with the introduction of 32-bit processors, which has been a standard in general-purpose computing for two decades. Not until recently (c. 2003–2004), with the advent of x86-64
X86-64
x86-64 is an extension of the x86 instruction set. It supports vastly larger virtual and physical address spaces than are possible on x86, thereby allowing programmers to conveniently work with much larger data sets. x86-64 also provides 64-bit general purpose registers and numerous other...
architectures, have 64-bit
64-bit
64-bit is a word size that defines certain classes of computer architecture, buses, memory and CPUs, and by extension the software that runs on them. 64-bit CPUs have existed in supercomputers since the 1970s and in RISC-based workstations and servers since the early 1990s...
processors become commonplace.
Instruction-level parallelism
Out-of-order execution
In computer engineering, out-of-order execution is a paradigm used in most high-performance microprocessors to make use of instruction cycles that would otherwise be wasted by a certain type of costly delay...
and combined into groups which are then executed in parallel without changing the result of the program. This is known as instruction-level parallelism. Advances in instruction-level parallelism dominated computer architecture from the mid-1980s until the mid-1990s.
Modern processors have multi-stage instruction pipeline
Instruction pipeline
An instruction pipeline is a technique used in the design of computers and other digital electronic devices to increase their instruction throughput ....
s. Each stage in the pipeline corresponds to a different action the processor performs on that instruction in that stage; a processor with an N-stage pipeline can have up to N different instructions at different stages of completion. The canonical example of a pipelined processor is a RISC
Reduced instruction set computer
Reduced instruction set computing, or RISC , is a CPU design strategy based on the insight that simplified instructions can provide higher performance if this simplicity enables much faster execution of each instruction. A computer based on this strategy is a reduced instruction set computer...
processor, with five stages: instruction fetch, decode, execute, memory access, and write back. The Pentium 4
Pentium 4
Pentium 4 was a line of single-core desktop and laptop central processing units , introduced by Intel on November 20, 2000 and shipped through August 8, 2008. They had a 7th-generation x86 microarchitecture, called NetBurst, which was the company's first all-new design since the introduction of the...
processor had a 35-stage pipeline.
In addition to instruction-level parallelism from pipelining, some processors can issue more than one instruction at a time. These are known as superscalar
Superscalar
A superscalar CPU architecture implements a form of parallelism called instruction level parallelism within a single processor. It therefore allows faster CPU throughput than would otherwise be possible at a given clock rate...
processors. Instructions can be grouped together only if there is no data dependency
Data dependency
A data dependency in computer science is a situation in which a program statement refers to the data of a preceding statement. In compiler theory, the technique used to discover data dependencies among statements is called dependence analysis.There are three types of dependencies: data, name, and...
between them. Scoreboarding
Scoreboarding
Scoreboarding is a centralized method, used in the CDC 6600 computer, for dynamically scheduling a pipeline so that the instructions can execute out of order when there are no conflicts and the hardware is available. In a scoreboard, the data dependencies of every instruction are logged...
and the Tomasulo algorithm
Tomasulo algorithm
The Tomasulo algorithm is a hardware algorithm developed in 1967 by Robert Tomasulo from IBM. It allows sequential instructions that would normally be stalled due to certain dependencies to execute non-sequentially...
(which is similar to scoreboarding but makes use of register renaming
Register renaming
In computer architecture, register renaming refers to a technique used to avoid unnecessary serialization of program operations imposed by the reuse of registers by those operations.-Problem definition:...
) are two of the most common techniques for implementing out-of-order execution and instruction-level parallelism .
Data parallelism
Data parallelism is parallelism inherent in program loops, which focuses on distributing the data across different computing nodes to be processed in parallel. "Parallelizing loops often leads to similar (not necessarily identical) operation sequences or functions being performed on elements of a large data structure." Many scientific and engineering applications exhibit data parallelism.A loop-carried dependency is the dependence of a loop iteration on the output of one or more previous iterations. Loop-carried dependencies prevent the parallelization of loops. For example, consider the following pseudocode
Pseudocode
In computer science and numerical computation, pseudocode is a compact and informal high-level description of the operating principle of a computer program or other algorithm. It uses the structural conventions of a programming language, but is intended for human reading rather than machine reading...
that computes the first few Fibonacci number
Fibonacci number
In mathematics, the Fibonacci numbers are the numbers in the following integer sequence:0,\;1,\;1,\;2,\;3,\;5,\;8,\;13,\;21,\;34,\;55,\;89,\;144,\; \ldots\; ....
s:
1: PREV1 := 0
2: PREV2 := 1
4: do:
5: CUR := PREV1 + PREV2
6: PREV1 := PREV2
7: PREV2 := CUR
8: while (CUR < 10)
This loop cannot be parallelized because CUR depends on itself (PREV2) and PREV1, which are computed in each loop iteration. Since each iteration depends on the result of the previous one, they cannot be performed in parallel. As the size of a problem gets bigger, the amount of data-parallelism available usually does as well.
Task parallelism
Task parallelism is the characteristic of a parallel program that "entirely different calculations can be performed on either the same or different sets of data". This contrasts with data parallelism, where the same calculation is performed on the same or different sets of data. Task parallelism does not usually scale with the size of a problem.Memory and communication
Main memory in a parallel computer is either shared memoryShared memory
In computing, shared memory is memory that may be simultaneously accessed by multiple programs with an intent to provide communication among them or avoid redundant copies. Depending on context, programs may run on a single processor or on multiple separate processors...
(shared between all processing elements in a single address space
Address space
In computing, an address space defines a range of discrete addresses, each of which may correspond to a network host, peripheral device, disk sector, a memory cell or other logical or physical entity.- Overview :...
), or distributed memory
Distributed memory
In computer science, distributed memory refers to a multiple-processor computer system in which each processor has its own private memory. Computational tasks can only operate on local data, and if remote data is required, the computational task must communicate with one or more remote processors...
(in which each processing element has its own local address space). Distributed memory refers to the fact that the memory is logically distributed, but often implies that it is physically distributed as well. Distributed shared memory
Distributed shared memory
Distributed Shared Memory , in Computer Architecture is a form of memory architecture where the memories can be addressed as one address space...
and memory virtualization
Memory virtualization
In computer science, memory virtualization decouples volatile random access memory resources from individual systems in the data center, and then aggregates those resources into a virtualized memory pool available to any computer in the cluster. The memory pool is accessed by the operating system...
combine the two approaches, where the processing element has its own local memory and access to the memory on non-local processors. Accesses to local memory are typically faster than accesses to non-local memory.
Computer architectures in which each element of main memory can be accessed with equal latency and bandwidth
Bandwidth (computing)
In computer networking and computer science, bandwidth, network bandwidth, data bandwidth, or digital bandwidth is a measure of available or consumed data communication resources expressed in bits/second or multiples of it .Note that in textbooks on wireless communications, modem data transmission,...
are known as Uniform Memory Access
Uniform Memory Access
Uniform Memory Access is a shared memory architecture used in parallel computers.All the processors in the UMA model share the physical memory uniformly...
(UMA) systems. Typically, that can be achieved only by a shared memory
Shared memory
In computing, shared memory is memory that may be simultaneously accessed by multiple programs with an intent to provide communication among them or avoid redundant copies. Depending on context, programs may run on a single processor or on multiple separate processors...
system, in which the memory is not physically distributed. A system that does not have this property is known as a Non-Uniform Memory Access
Non-Uniform Memory Access
Non-Uniform Memory Access is a computer memory design used in Multiprocessing, where the memory access time depends on the memory location relative to a processor...
(NUMA) architecture. Distributed memory systems have non-uniform memory access.
Computer systems make use of cache
Cache
In computer engineering, a cache is a component that transparently stores data so that future requests for that data can be served faster. The data that is stored within a cache might be values that have been computed earlier or duplicates of original values that are stored elsewhere...
s—small, fast memories located close to the processor which store temporary copies of memory values (nearby in both the physical and logical sense). Parallel computer systems have difficulties with caches that may store the same value in more than one location, with the possibility of incorrect program execution. These computers require a cache coherency
Cache coherency
In computing, cache coherence refers to the consistency of data stored in local caches of a shared resource.When clients in a system maintain caches of a common memory resource, problems may arise with inconsistent data. This is particularly true of CPUs in a multiprocessing system...
system, which keeps track of cached values and strategically purges them, thus ensuring correct program execution. Bus snooping
Bus sniffing
Bus sniffing or Bus snooping is a technique used in distributed shared memory systems and multiprocessors to achieve cache coherence. Although there is one main memory, there are several caches , and unless preventative steps are taken, the same memory location may be loaded into two caches, and...
is one of the most common methods for keeping track of which values are being accessed (and thus should be purged). Designing large, high-performance cache coherence systems is a very difficult problem in computer architecture. As a result, shared-memory computer architectures do not scale as well as distributed memory systems do.
Processor–processor and processor–memory communication can be implemented in hardware in several ways, including via shared (either multiported or multiplexed
Multiplexing
The multiplexed signal is transmitted over a communication channel, which may be a physical transmission medium. The multiplexing divides the capacity of the low-level communication channel into several higher-level logical channels, one for each message signal or data stream to be transferred...
) memory, a crossbar switch
Crossbar switch
In electronics, a crossbar switch is a switch connecting multiple inputs to multiple outputs in a matrix manner....
, a shared bus or an interconnect network of a myriad of topologies
Network topology
Network topology is the layout pattern of interconnections of the various elements of a computer or biological network....
including star
Star network
Star networks are one of the most common computer network topologies. In its simplest form, a star network consists of one central switch, hub or computer, which acts as a conduit to transmit messages...
, ring
Ring network
A ring network is a network topology in which each node connects to exactly two other nodes, forming a single continuous pathway for signals through each node - a ring...
, tree
Tree (graph theory)
In mathematics, more specifically graph theory, a tree is an undirected graph in which any two vertices are connected by exactly one simple path. In other words, any connected graph without cycles is a tree...
, hypercube, fat hypercube (a hypercube with more than one processor at a node), or n-dimensional mesh
Mesh networking
Mesh networking is a type of networking where each node must not only capture and disseminate its own data, but also serve as a relay for other nodes, that is, it must collaborate to propagate the data in the network....
.
Parallel computers based on interconnect networks need to have some kind of routing
Routing
Routing is the process of selecting paths in a network along which to send network traffic. Routing is performed for many kinds of networks, including the telephone network , electronic data networks , and transportation networks...
to enable the passing of messages between nodes that are not directly connected. The medium used for communication between the processors is likely to be hierarchical in large multiprocessor machines.
Classes of parallel computers
Parallel computers can be roughly classified according to the level at which the hardware supports parallelism. This classification is broadly analogous to the distance between basic computing nodes. These are not mutually exclusive; for example, clusters of symmetric multiprocessors are relatively common.Multicore computing
A multicore processor is a processor that includes multiple execution unitExecution unit
In computer engineering, an execution unit is a part of a CPU that performs the operations and calculations called for by the Branch Unit, which receives data from the CPU...
s ("cores") on the same chip. These processors differ from superscalar processors, which can issue multiple instructions per cycle from one instruction stream (thread); in contrast, a multicore processor can issue multiple instructions per cycle from multiple instruction streams. Each core in a multicore processor can potentially be superscalar as well—that is, on every cycle, each core can issue multiple instructions from one instruction stream.
Simultaneous multithreading
Simultaneous multithreading
Simultaneous multithreading, often abbreviated as SMT, is a technique for improving the overall efficiency of superscalar CPUs with hardware multithreading...
(of which Intel's HyperThreading is the best known) was an early form of pseudo-multicoreism. A processor capable of simultaneous multithreading has only one execution unit ("core"), but when that execution unit is idling (such as during a cache miss), it uses that execution unit to process a second thread. IBM
IBM
International Business Machines Corporation or IBM is an American multinational technology and consulting corporation headquartered in Armonk, New York, United States. IBM manufactures and sells computer hardware and software, and it offers infrastructure, hosting and consulting services in areas...
's Cell microprocessor
Cell (microprocessor)
Cell is a microprocessor architecture jointly developed by Sony, Sony Computer Entertainment, Toshiba, and IBM, an alliance known as "STI". The architectural design and first implementation were carried out at the STI Design Center in Austin, Texas over a four-year period beginning March 2001 on a...
, designed for use in the Sony
Sony
, commonly referred to as Sony, is a Japanese multinational conglomerate corporation headquartered in Minato, Tokyo, Japan and the world's fifth largest media conglomerate measured by revenues....
PlayStation 3
PlayStation 3
The is the third home video game console produced by Sony Computer Entertainment and the successor to the PlayStation 2 as part of the PlayStation series. The PlayStation 3 competes with Microsoft's Xbox 360 and Nintendo's Wii as part of the seventh generation of video game consoles...
, is another prominent multicore processor.
Symmetric multiprocessing
A symmetric multiprocessor (SMP) is a computer system with multiple identical processors that share memory and connect via a bus. Bus contentionBus contention
Bus contention, in computer design, is an undesirable state of the bus in which more than one device on the bus attempts to place values on the bus at the same time. Most bus architectures require their devices follow an arbitration protocol carefully designed to make the likelihood of contention...
prevents bus architectures from scaling. As a result, SMPs generally do not comprise more than 32 processors. "Because of the small size of the processors and the significant reduction in the requirements for bus bandwidth achieved by large caches, such symmetric multiprocessors are extremely cost-effective, provided that a sufficient amount of memory bandwidth exists."
Distributed computing
A distributed computer (also known as a distributed memory multiprocessor) is a distributed memory computer system in which the processing elements are connected by a network. Distributed computers are highly scalable.Cluster computing
Load balancing (computing)
Load balancing is a computer networking methodology to distribute workload across multiple computers or a computer cluster, network links, central processing units, disk drives, or other resources, to achieve optimal resource utilization, maximize throughput, minimize response time, and avoid...
is more difficult if they are not. The most common type of cluster is the Beowulf cluster
Beowulf (computing)
A Beowulf cluster is a computer cluster of what are normally identical, commodity-grade computers networked into a small local area network with libraries and programs installed which allow processing to be shared among them...
, which is a cluster implemented on multiple identical commercial off-the-shelf
Commercial off-the-shelf
In the United States, Commercially available Off-The-Shelf is a Federal Acquisition Regulation term defining a nondevelopmental item of supply that is both commercial and sold in substantial quantities in the commercial marketplace, and that can be procured or utilized under government contract...
computers connected with a TCP/IP Ethernet
Ethernet
Ethernet is a family of computer networking technologies for local area networks commercially introduced in 1980. Standardized in IEEE 802.3, Ethernet has largely replaced competing wired LAN technologies....
local area network
Local area network
A local area network is a computer network that interconnects computers in a limited area such as a home, school, computer laboratory, or office building...
. Beowulf technology was originally developed by Thomas Sterling
Thomas Sterling (computing)
Dr. Thomas Sterling is currently a Professor of Computer Science at Louisiana State University, a Faculty Associate at California Institute of Technology, and a Distinguished Visiting Scientist at Oak Ridge National Laboratory. He received his PhD as a Hertz Fellow from MIT in 1984...
and Donald Becker
Donald Becker
right|thumbnail|Donald Becker is a developer, well-known for writing many of the Ethernet drivers for the Linux operating system. Thousands of computers around the world routinely use his drivers to connect to the Internet....
. The vast majority of the TOP500
TOP500
The TOP500 project ranks and details the 500 most powerful known computer systems in the world. The project was started in 1993 and publishes an updated list of the supercomputers twice a year...
supercomputers are clusters.
Massive parallel processing
A massively parallel processor (MPP) is a single computer with many networked processors. MPPs have many of the same characteristics as clusters, but MPPs have specialized interconnect networks (whereas clusters use commodity hardware for networking). MPPs also tend to be larger than clusters, typically having "far more" than 100 processors. In an MPP, "each CPU contains its own memory and copy of the operating system and application. Each subsystem communicates with the others via a high-speed interconnect."
Grid computing
Grid computing is the most distributed form of parallel computing. It makes use of computers communicating over the Internet
Internet
The Internet is a global system of interconnected computer networks that use the standard Internet protocol suite to serve billions of users worldwide...
to work on a given problem. Because of the low bandwidth and extremely high latency available on the Internet, grid computing typically deals only with embarrassingly parallel
Embarrassingly parallel
In parallel computing, an embarrassingly parallel workload is one for which little or no effort is required to separate the problem into a number of parallel tasks...
problems. Many grid computing applications have been created, of which SETI@home
SETI@home
SETI@home is an Internet-based public volunteer computing project employing the BOINC software platform, hosted by the Space Sciences Laboratory, at the University of California, Berkeley, in the United States. SETI is an acronym for the Search for Extra-Terrestrial Intelligence...
and Folding@Home
Folding@home
Folding@home is a distributed computing project designed to use spare processing power on personal computers to perform simulations of disease-relevant protein folding and other molecular dynamics, and to improve on the methods of doing so...
are the best-known examples.
Most grid computing applications use middleware
Middleware
Middleware is computer software that connects software components or people and their applications. The software consists of a set of services that allows multiple processes running on one or more machines to interact...
, software that sits between the operating system and the application to manage network resources and standardize the software interface. The most common grid computing middleware is the Berkeley Open Infrastructure for Network Computing
Berkeley Open Infrastructure for Network Computing
The Berkeley Open Infrastructure for Network Computing is an open source middleware system for volunteer and grid computing. It was originally developed to support the SETI@home project before it became useful as a platform for other distributed applications in areas as diverse as mathematics,...
(BOINC). Often, grid computing software makes use of "spare cycles", performing computations at times when a computer is idling.
Specialized parallel computers
Within parallel computing, there are specialized parallel devices that remain niche areas of interest. While not domain-specificDomain-specific programming language
In software development and domain engineering, a domain-specific language is a programming language or specification language dedicated to a particular problem domain, a particular problem representation technique, and/or a particular solution technique...
, they tend to be applicable to only a few classes of parallel problems.
Reconfigurable computing with field-programmable gate arrays
Reconfigurable computing
Reconfigurable computing
Reconfigurable computing is a computer architecture combining some of the flexibility of software with the high performance of hardware by processing with very flexible high speed computing fabrics like field-programmable gate arrays...
is the use of a field-programmable gate array
Field-programmable gate array
A field-programmable gate array is an integrated circuit designed to be configured by the customer or designer after manufacturing—hence "field-programmable"...
(FPGA) as a co-processor to a general-purpose computer. An FPGA is, in essence, a computer chip that can rewire itself for a given task.
FPGAs can be programmed with hardware description language
Hardware description language
In electronics, a hardware description language or HDL is any language from a class of computer languages, specification languages, or modeling languages for formal description and design of electronic circuits, and most-commonly, digital logic...
s such as VHDL or Verilog
Verilog
In the semiconductor and electronic design industry, Verilog is a hardware description language used to model electronic systems. Verilog HDL, not to be confused with VHDL , is most commonly used in the design, verification, and implementation of digital logic chips at the register-transfer level...
. However, programming in these languages can be tedious. Several vendors have created C to HDL
C to HDL
C to HDL tools convert C or C-like computer program code into a hardware description language such as VHDL or Verilog. The converted code can then be synthesized and translated into a hardware device such as a field-programmable gate array...
languages that attempt to emulate the syntax and/or semantics of the C programming language, with which most programmers are familiar. The best known C to HDL languages are Mitrion-C, Impulse C
Impulse C
Impulse C is a subset of the C programming language combined with a C-compatible function library supporting parallel programming, in particular for programming of applications targeting FPGA devices...
, DIME-C
DIME-C
DIME-C is a C to HDL tool developed by Nallatech it is part of their DIMEtalk Design Tools suite. It includes an editor, a compiler and a parallelization visualizer. It supports the majority of ANSI C. It generates VHDL.- External links :*...
, and Handel-C
Handel-C
Handel-C is a high level programming language which targets low-level hardware, most commonly used in the programming of FPGAs. It is a rich subset of C, with non-standard extensions to control hardware instantiation with an emphasis on parallelism. Handel-C is to hardware design what the first...
. Specific subsets of SystemC
SystemC
SystemC is a set of C++ classes and macros which provide an event-driven simulation kernel in C++ . These facilities enable a designer to simulate concurrent processes, each described using plain C++ syntax...
based on C++ can also be used for this purpose.
AMD's decision to open its HyperTransport
HyperTransport
HyperTransport , formerly known as Lightning Data Transport , is a technology for interconnection of computer processors. It is a bidirectional serial/parallel high-bandwidth, low-latency point-to-point link that was introduced on April 2, 2001...
technology to third-party vendors has become the enabling technology for high-performance reconfigurable computing. According to Michael R. D'Amour, Chief Operating Officer of DRC Computer Corporation, "when we first walked into AMD, they called us 'the socket
CPU socket
A CPU socket or CPU slot is a mechanical component that provides mechanical and electrical connections between a microprocessor and a printed circuit board . This allows the CPU to be replaced without soldering....
stealers.' Now they call us their partners."
General-purpose computing on graphics processing units (GPGPU)
Graphics processing unit
A graphics processing unit or GPU is a specialized circuit designed to rapidly manipulate and alter memory in such a way so as to accelerate the building of images in a frame buffer intended for output to a display...
s (GPGPU) is a fairly recent trend in computer engineering research. GPUs are co-processors that have been heavily optimized for computer graphics
Computer graphics
Computer graphics are graphics created using computers and, more generally, the representation and manipulation of image data by a computer with help from specialized software and hardware....
processing. Computer graphics processing is a field dominated by data parallel operations—particularly linear algebra
Linear algebra
Linear algebra is a branch of mathematics that studies vector spaces, also called linear spaces, along with linear functions that input one vector and output another. Such functions are called linear maps and can be represented by matrices if a basis is given. Thus matrix theory is often...
matrix
Matrix (mathematics)
In mathematics, a matrix is a rectangular array of numbers, symbols, or expressions. The individual items in a matrix are called its elements or entries. An example of a matrix with six elements isMatrices of the same size can be added or subtracted element by element...
operations.
In the early days, GPGPU programs used the normal graphics APIs for executing programs. However, several new programming languages and platforms have been built to do general purpose computation on GPUs with both Nvidia
NVIDIA
Nvidia is an American global technology company based in Santa Clara, California. Nvidia is best known for its graphics processors . Nvidia and chief rival AMD Graphics Techonologies have dominated the high performance GPU market, pushing other manufacturers to smaller, niche roles...
and AMD releasing programming environments with CUDA
CUDA
CUDA or Compute Unified Device Architecture is a parallel computing architecture developed by Nvidia. CUDA is the computing engine in Nvidia graphics processing units that is accessible to software developers through variants of industry standard programming languages...
and CTM
Close to Metal
Close To Metal is the name of a beta version of a low-level programming interface developed by ATI , aimed at enabling GPGPU computing...
respectively. Other GPU programming languages are BrookGPU
BrookGPU
BrookGPU is the Stanford University graphics group's compiler and runtime implementation of the Brook stream programming language for using modern graphics hardware for non-graphical, general purpose computations...
, PeakStream
PeakStream
PeakStream was a parallel processing software company located in Redwood Shores, California founded by Matthew Papakipos and Asher Waldfogel in April 2005 and backed by Sequoia Capital and Kleiner Perkins. PeakStream released a high-performance parallel processing library targeting ATI graphics...
, and RapidMind
RapidMind
RapidMind Inc. was a privately held company founded and headquartered in Waterloo, Ontario, Canada, acquired by Intel in 2009. It provided a software product that aims to make it simpler for software developers to target multi-core processors and accelerators such as GPUs.-History:RapidMind was...
. Nvidia has also released specific products for computation in their Tesla series
Nvidia Tesla
The Tesla graphics processing unit is nVidia's third brand of GPUs. It is based on high-end GPUs from the G80 , as well as the Quadro lineup. Tesla is nVidia's first dedicated General Purpose GPU...
. The technology consortium Khronos Group has released the OpenCL
OpenCL
OpenCL is a framework for writing programs that execute across heterogeneous platforms consisting of CPUs, GPUs, and other processors. OpenCL includes a language for writing kernels , plus APIs that are used to define and then control the platforms...
specification, which is a framework for writing programs that execute across platforms consisting of CPUs and GPUs. Apple, Intel, Nvidia
NVIDIA
Nvidia is an American global technology company based in Santa Clara, California. Nvidia is best known for its graphics processors . Nvidia and chief rival AMD Graphics Techonologies have dominated the high performance GPU market, pushing other manufacturers to smaller, niche roles...
and others are supporting OpenCL
OpenCL
OpenCL is a framework for writing programs that execute across heterogeneous platforms consisting of CPUs, GPUs, and other processors. OpenCL includes a language for writing kernels , plus APIs that are used to define and then control the platforms...
.
Application-specific integrated circuits
Several application-specific integrated circuit
Application-specific integrated circuit
An application-specific integrated circuit is an integrated circuit customized for a particular use, rather than intended for general-purpose use. For example, a chip designed solely to run a cell phone is an ASIC...
(ASIC) approaches have been devised for dealing with parallel applications.
Because an ASIC is (by definition) specific to a given application, it can be fully optimized for that application. As a result, for a given application, an ASIC tends to outperform a general-purpose computer. However, ASICs are created by X-ray lithography
X-ray lithography
300px|thumbX-ray lithography, is a process used in electronic industry to selectively remove parts of a thin film. It uses X-rays to transfer a geometric pattern from a mask to a light-sensitive chemical photoresist, or simply "resist," on the substrate...
. This process requires a mask, which can be extremely expensive. A single mask can cost over a million US dollars. (The smaller the transistors required for the chip, the more expensive the mask will be.) Meanwhile, performance increases in general-purpose computing over time (as described by Moore's Law) tend to wipe out these gains in only one or two chip generations. High initial cost, and the tendency to be overtaken by Moore's-law-driven general-purpose computing, has rendered ASICs unfeasible for most parallel computing applications. However, some have been built. One example is the peta-flop RIKEN MDGRAPE-3
RIKEN MDGRAPE-3
MDGRAPE-3 is an ultra-high performance petascale supercomputer system developed by the RIKEN research institute in Japan. It is a special purpose system built for molecular dynamics simulations, especially protein structure prediction....
machine which uses custom ASICs for molecular dynamics
Molecular dynamics
Molecular dynamics is a computer simulation of physical movements of atoms and molecules. The atoms and molecules are allowed to interact for a period of time, giving a view of the motion of the atoms...
simulation.
Vector processors
A vector processor is a CPU or computer system that can execute the same instruction on large sets of data. "Vector processors have high-level operations that work on linear arrays of numbers or vectors. An example vector operation is A = B × C, where A, B, and C are each 64-element vectors of 64-bit floating-point
Floating point
In computing, floating point describes a method of representing real numbers in a way that can support a wide range of values. Numbers are, in general, represented approximately to a fixed number of significant digits and scaled using an exponent. The base for the scaling is normally 2, 10 or 16...
numbers." They are closely related to Flynn's SIMD classification.
Cray
Cray
Cray Inc. is an American supercomputer manufacturer based in Seattle, Washington. The company's predecessor, Cray Research, Inc. , was founded in 1972 by computer designer Seymour Cray. Seymour Cray went on to form the spin-off Cray Computer Corporation , in 1989, which went bankrupt in 1995,...
computers became famous for their vector-processing computers in the 1970s and 1980s. However, vector processors—both as CPUs and as full computer systems—have generally disappeared. Modern processor instruction sets
Instruction set
An instruction set, or instruction set architecture , is the part of the computer architecture related to programming, including the native data types, instructions, registers, addressing modes, memory architecture, interrupt and exception handling, and external I/O...
do include some vector processing instructions, such as with AltiVec
AltiVec
AltiVec is a floating point and integer SIMD instruction set designed and owned by Apple, IBM and Freescale Semiconductor, formerly the Semiconductor Products Sector of Motorola, , and implemented on versions of the PowerPC including Motorola's G4, IBM's G5 and POWER6 processors, and P.A. Semi's...
and Streaming SIMD Extensions
Streaming SIMD Extensions
In computing, Streaming SIMD Extensions is a SIMD instruction set extension to the x86 architecture, designed by Intel and introduced in 1999 in their Pentium III series processors as a reply to AMD's 3DNow! . SSE contains 70 new instructions, most of which work on single precision floating point...
(SSE).