
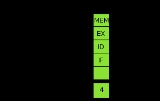
Instruction pipeline
Encyclopedia
Computer
A computer is a programmable machine designed to sequentially and automatically carry out a sequence of arithmetic or logical operations. The particular sequence of operations can be changed readily, allowing the computer to solve more than one kind of problem...
s and other digital electronic devices to increase their instruction throughput (the number of instructions that can be executed in a unit of time).
The fundamental idea is to split the processing of a computer instruction into a series of independent steps, with storage at the end of each step. This allows the computer's control circuitry to issue instructions at the processing rate of the slowest step, which is much faster than the time needed to perform all steps at once. The term pipeline refers to the fact that each step is carrying data at once (like water), and each step is connected to the next (like the links of a pipe.)
The origin of
pipelining is thought to be either the ILLIAC II
ILLIAC II
The ILLIAC II was a revolutionary super-computer built by the University of Illinois that became operational in 1962.-Description:The concept, proposed in 1958, pioneered Emitter-coupled logic circuitry, pipelining, and transistor memory with a design goal of 100x speedup compared to ILLIAC...
project or the IBM Stretch project
though a simple version was used earlier in the Z1
Z1 (computer)
The Z1 was a mechanical computer designed by Konrad Zuse from 1935 to 1936 and built by him from 1936 to 1938. It was a binary electrically driven mechanical calculator with limited programmability, reading instructions from punched tape....
in 1939
and the Z3 in 1941.
The IBM Stretch Project proposed the terms, "Fetch, Decode, and Execute" that became common usage.
Most modern CPUs
Central processing unit
The central processing unit is the portion of a computer system that carries out the instructions of a computer program, to perform the basic arithmetical, logical, and input/output operations of the system. The CPU plays a role somewhat analogous to the brain in the computer. The term has been in...
are driven by a clock. The CPU consists internally of logic and registers (flip flop
Flip-flop (electronics)
In electronics, a flip-flop or latch is a circuit that has two stable states and can be used to store state information. The circuit can be made to change state by signals applied to one or more control inputs and will have one or two outputs. It is the basic storage element in sequential logic...
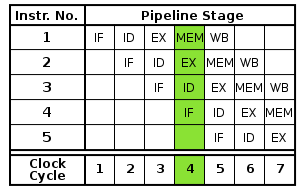
s). When the clock signal arrives, the flip flops take their new value and the logic then requires a period of time to decode the new values. Then the next clock pulse arrives and the flip flops again take their new values, and so on. By breaking the logic into smaller pieces and inserting flip flops between the pieces of logic, the delay before the logic gives valid outputs is reduced. In this way the clock period can be reduced. For example, the classic RISC pipeline
Classic RISC pipeline
In the history of computer hardware, some early reduced instruction set computer central processing units used a very similar architectural solution, now called a classic RISC pipeline. Those CPUs were: MIPS, SPARC, Motorola 88000, and later DLX....
is broken into five stages with a set of flip flops between each stage.
- Instruction fetch
- Instruction decode and register fetch
- Execute
- Memory access
- Register write back
When a programmer (or compiler) writes assembly code, they make the assumption that each instruction is executed before execution of the subsequent instruction is begun. This assumption is invalidated by pipelining. When this causes a program to behave incorrectly, the situation is known as a hazard. Various techniques for resolving hazards such as forwarding and stalling exist.
A non-pipeline architecture is inefficient because some CPU components (modules) are idle while another module is active during the instruction cycle. Pipelining does not completely cancel out idle time in a CPU but making those modules work in parallel improves program execution significantly.
Processors with pipelining are organized inside into stages which can semi-independently work on separate jobs. Each stage is organized and linked into a 'chain' so each stage's output is fed to another stage until the job is done. This organization of the processor allows overall processing time to be significantly reduced.
A deeper pipeline means that there are more stages in the pipeline, and therefore, fewer logic gates in each stage. This generally means that the processor's frequency can be increased as the cycle time is lowered. This happens because there are fewer components in each stage of the pipeline, so the propagation delay is decreased for the overall stage.
Unfortunately, not all instructions are independent. In a simple pipeline, completing an instruction may require 5 stages. To operate at full performance, this pipeline will need to run 4 subsequent independent instructions while the first is completing. If 4 instructions that do not depend on the output of the first instruction are not available, the pipeline control logic must insert a stall or wasted clock cycle into the pipeline until the dependency is resolved. Fortunately, techniques such as forwarding can significantly reduce the cases where stalling is required. While pipelining can in theory increase performance over an unpipelined core by a factor of the number of stages (assuming the clock frequency also scales with the number of stages), in reality, most code does not allow for ideal execution.
Advantages and disadvantages
Pipelining does not help in all cases. There are several possible disadvantages. An instruction pipeline is said to be fully pipelined if it can accept a new instruction every clock cycle. A pipeline that is not has wait cycles that delay the progress of the pipeline.Advantages of Pipelining:
- The cycle time of the processor is reduced, thus increasing instruction issue-rate in most cases.
- Some combinational circuits such as adders or multipliers can be made faster by adding more circuitry. If pipelining is used instead, it can save circuitry vs. a more complex combinational circuit.
Disadvantages of Pipelining:
- A non-pipelined processor executes only a single instruction at a time. This prevents branch delays (in effect, every branch is delayed) and problems with serial instructions being executed concurrently. Consequently the design is simpler and cheaper to manufacture.
- The instruction latency in a non-pipelined processor is slightly lower than in a pipelined equivalent. This is because extra flip flopsFlip-flop (electronics)In electronics, a flip-flop or latch is a circuit that has two stable states and can be used to store state information. The circuit can be made to change state by signals applied to one or more control inputs and will have one or two outputs. It is the basic storage element in sequential logic...
must be added to the data path of a pipelined processor. - A non-pipelined processor will have a stable instruction bandwidth. The performance of a pipelined processor is much harder to predict and may vary more widely between different programs.
Generic pipeline
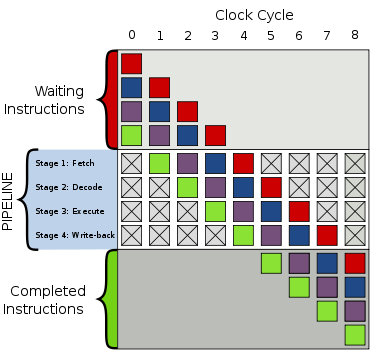
- Fetch
- Decode
- Execute
- Write-back
(for lw and sw memory is accessed after execute stage)
The top gray box is the list of instructions waiting to be executed; the bottom gray box is the list of instructions that have been completed; and the middle white box is the pipeline.
Execution is as follows:
| Time | Execution |
|---|---|
| 0 | Four instructions are awaiting to be executed |
| 1 |
|
| 2 |
|
| 3 |
|
| 4 |
|
| 5 |
|
| 6 |
|
| 7 |
|
| 8 |
|
| 9 | All instructions are executed |
Bubble

When a "hiccup" in execution occurs, a "bubble" is created in the pipeline in which nothing useful happens. In cycle 2, the fetching of the purple instruction is delayed and the decoding stage in cycle 3 now contains a bubble. Everything "behind" the purple instruction is delayed as well but everything "ahead" of the purple instruction continues with execution.
Clearly, when compared to the execution above, the bubble yields a total execution time of 8 clock ticks instead of 7.
Bubbles are like stalls, in which nothing useful will happen for the fetch, decode, execute and writeback. It can be completed with a nop code.
Example 1
A typical instruction to add two numbers might beADD A, B, C, which adds the values found in memory locations A and B, and then puts the result in memory location C. In a pipelined processor the pipeline controller would break this into a series of tasks similar to:
LOAD R1, A
LOAD R2, B
ADD R3, R1, R2
STORE C, R3
LOAD next instruction
The locations 'R1', 'R2' and 'R3' are registers
Processor register
In computer architecture, a processor register is a small amount of storage available as part of a CPU or other digital processor. Such registers are addressed by mechanisms other than main memory and can be accessed more quickly...
in the CPU. The values stored in memory locations labeled 'A' and 'B' are loaded (copied) into the R1 and R2 registers, then added, and the result (which is in register R3) is stored in a memory location labeled 'C'.
In this example the pipeline is three stages long: load, execute, and store. Each of the steps are called pipeline stages.
On a non-pipelined processor, only one stage can be working at a time so the entire instruction has to complete before the next instruction can begin. On a pipelined processor, all of the stages can be working at once on different instructions. So when this instruction is at the execute stage, a second instruction will be at the decode stage and a 3rd instruction will be at the fetch stage.
Pipelining doesn't reduce the time it takes to complete an instruction; it increases the number of instructions that can be processed at once and reduces the delay between completed instructions. The more pipeline stages a processor has, the more instructions it can be working on at once and the less of a delay there is between completed instructions. Modern microprocessor core designs use at least two stages of pipeline. (The Atmel AVR
Atmel AVR
The AVR is a modified Harvard architecture 8-bit RISC single chip microcontroller which was developed by Atmel in 1996. The AVR was one of the first microcontroller families to use on-chip flash memory for program storage, as opposed to one-time programmable ROM, EPROM, or EEPROM used by other...
and the PIC microcontroller
PIC microcontroller
PIC is a family of Harvard architecture microcontrollers made by Microchip Technology, derived from the PIC1650 originally developed by General Instrument's Microelectronics Division...
each have a 2-stage pipeline.) Intel Pentium 4 processors have 20-stage pipelines.
Example 2
To better visualize the concept, we can look at a theoretical 3-stage pipeline:| Stage | Description |
|---|---|
| Load | Read instruction from memory |
| Execute | Execute instruction |
| Store | Store result in memory and/or registers |
and a pseudo-code assembly
Assembly language
An assembly language is a low-level programming language for computers, microprocessors, microcontrollers, and other programmable devices. It implements a symbolic representation of the machine codes and other constants needed to program a given CPU architecture...
listing to be executed:
LOAD A, #40 ; load 40 in A
MOVE B, A ; copy A in B
ADD B, #20 ; add 20 to B
STORE 0x300, B ; store B into memory cell 0x300
This is how it would be executed:
| Load | Execute | Store |
|---|---|---|
| LOAD |
The LOAD instruction is fetched from memory.
| Load | Execute | Store |
|---|---|---|
| MOVE | LOAD |
The LOAD instruction is executed, while the MOVE instruction is fetched from memory.
| Load | Execute | Store |
|---|---|---|
| ADD | MOVE | LOAD |
The LOAD instruction is in the Store stage, where its result (the number 40) will be stored in the register A.
In the meantime, the MOVE instruction is being executed.
Since it must move the contents of A into B, it must wait for the ending of the LOAD instruction.
| Load | Execute | Store |
|---|---|---|
| STORE | ADD | MOVE |
The STORE instruction is loaded, while the MOVE instruction is finishing off and the ADD is calculating.
And so on. Note that, sometimes, an instruction will depend on the result of another one (like our MOVE example). When more than one instruction references a particular location for an operand, either reading it (as an input) or writing it (as an output), executing those instructions in an order different from the original program order can lead to hazards
Hazard (computer architecture)
Hazards are problems with the instruction pipeline in central processing unit microarchitectures that potentially result in incorrect computation...
(mentioned above). There are several established techniques for either preventing hazards from occurring, or working around them if they do.
Complications
Many designs include pipelines as long as 7, 10 and even 20 stages (like in the Intel Pentium 4Pentium 4
Pentium 4 was a line of single-core desktop and laptop central processing units , introduced by Intel on November 20, 2000 and shipped through August 8, 2008. They had a 7th-generation x86 microarchitecture, called NetBurst, which was the company's first all-new design since the introduction of the...
). The later "Prescott" and "Cedar Mill" Pentium 4 cores (and their Pentium D
Pentium D
The Pentium D brand refers to two series of desktop dual-core 64-bit x86-64 microprocessors with the NetBurst microarchitecture manufactured by Intel. Each CPU comprised two dies, each containing a single core, residing next to each other on a multi-chip module package. The brand's first processor,...
derivatives) had a 31-stage pipeline, the longest in mainstream consumer computing. The Xelerated X10q Network Processor has a pipeline more than a thousand stages long. The downside of a long pipeline is that when a program branches, the processor cannot know where to fetch the next instruction from and must wait until the branch instruction finishes, leaving the pipeline behind it empty. In the extreme case, the performance of a pipelined processor could theoretically approach that of an un-pipelined processor, or even slightly worse if all but one pipeline stages are idle and a small overhead is present between stages. Branch prediction attempts to alleviate this problem by guessing whether the branch will be taken or not and speculatively executing
Speculative execution
Speculative execution in computer systems is doing work, the result of which may not be needed. This performance optimization technique is used in pipelined processors and other systems.-Main idea:...
the code path that it predicts will be taken. When its predictions are correct, branch prediction avoids the penalty associated with branching. However, branch prediction itself can end up exacerbating the problem if branches are predicted poorly, as the incorrect code path which has begun execution must be flushed from the pipeline before resuming execution at the correct location.
In certain applications, such as supercomputing
Supercomputer
A supercomputer is a computer at the frontline of current processing capacity, particularly speed of calculation.Supercomputers are used for highly calculation-intensive tasks such as problems including quantum physics, weather forecasting, climate research, molecular modeling A supercomputer is a...
, programs are specially written to branch rarely and so very long pipelines can speed up computation by reducing cycle time. If branching happens constantly, re-ordering branches such that the more likely to be needed instructions are placed into the pipeline can significantly reduce the speed losses associated with having to flush failed branches. Programs such as gcov can be used to examine how often particular branches are actually executed using a technique known as coverage analysis
Code coverage
Code coverage is a measure used in software testing. It describes the degree to which the source code of a program has been tested. It is a form of testing that inspects the code directly and is therefore a form of white box testing....
; however such analysis is often a last resort for optimization.
Self-Modifying Programs: Because of the instruction pipeline, code that the processor loads will not immediately execute. Due to this, updates in the code very near the current location of execution may not take effect because they are already loaded into the Prefetch Input Queue
Prefetch input queue
Fetching the instruction opcodes from program memory well in advance is known as prefetching and it is served by using prefetch input queue .The pre-fetched instructions are stored in data structure Queue. The fetching of opcodes well in advance, prior to their need for execution increases the...
. Instruction caches make this phenomenon even worse. This is only relevant to self-modifying programs
Self-modifying code
In computer science, self-modifying code is code that alters its own instructions while it is executing - usually to reduce the instruction path length and improve performance or simply to reduce otherwise repetitively similar code, thus simplifying maintenance...
.
Mathematical pipelines: Mathematical or arithmetic pipelines are different from instructional pipelines, in that when mathematically processing large arrays or vectors, a particular mathematical process, such as a multiply is repeated many thousands of times. In this environment, an instruction need only kick off an event whereby the arithmetic logic unit (which is pipelined) takes over, and begins its series of calculations. Most of these circuits can be found today in math processors and math processing sections of CPUs like the Intel Pentium line.
History
Math processing (super-computing) began in earnest in the late 1970s as Vector Processors and Array Processors. Usually very large bulky super-computing machines that needed special environments and super-cooling of the cores. One of the early super computers was the Cyber series built by Control Data Corporation. Its main architect was Seymour CraySeymour Cray
Seymour Roger Cray was an American electrical engineer and supercomputer architect who designed a series of computers that were the fastest in the world for decades, and founded Cray Research which would build many of these machines. Called "the father of supercomputing," Cray has been credited...
, who later resigned from CDC to head up Cray Research. Cray developed the XMP line of super computers, using pipelining for both multiply and add/subtract functions. Later, Star Technologies took pipelining to another level by adding parallelism (several pipelined functions working in parallel), developed by their engineer, Roger Chen. In 1984, Star Technologies made another breakthrough with the pipelined divide circuit, developed by James Bradley. By the mid 1980s, super-computing had taken off with offerings from many different companies around the world.
Today, most of these circuits can be found embedded inside most micro-processors.
See also
- Wait stateWait stateA wait state is a delay experienced by a computer processor when accessing external memory or another device that is slow to respond.As of late 2011, computer microprocessors run at very high speeds, while memory technology does not seem to be able to catch up: typical PC processors like the Intel...
- Classic RISC pipelineClassic RISC pipelineIn the history of computer hardware, some early reduced instruction set computer central processing units used a very similar architectural solution, now called a classic RISC pipeline. Those CPUs were: MIPS, SPARC, Motorola 88000, and later DLX....
- Pipeline (computing)
- Parallel computingParallel computingParallel computing is a form of computation in which many calculations are carried out simultaneously, operating on the principle that large problems can often be divided into smaller ones, which are then solved concurrently . There are several different forms of parallel computing: bit-level,...
- Instruction unitInstruction unitThe instruction unit in a central processing unit is responsible for organising for program instructions to be fetched from memory, and executed, in an appropriate order...