
.gif)
Standard error (statistics)
Encyclopedia
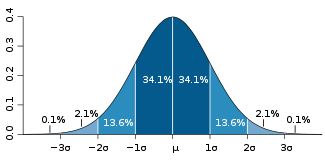
Standard deviation
Standard deviation is a widely used measure of variability or diversity used in statistics and probability theory. It shows how much variation or "dispersion" there is from the average...
of the sampling distribution
Sampling distribution
In statistics, a sampling distribution or finite-sample distribution is the probability distribution of a given statistic based on a random sample. Sampling distributions are important in statistics because they provide a major simplification on the route to statistical inference...
of a statistic
Statistic
A statistic is a single measure of some attribute of a sample . It is calculated by applying a function to the values of the items comprising the sample which are known together as a set of data.More formally, statistical theory defines a statistic as a function of a sample where the function...
. The term may also be used to refer to an estimate of that standard deviation, derived from a particular sample used to compute the estimate.
For example, the sample mean is the usual estimator
Estimator
In statistics, an estimator is a rule for calculating an estimate of a given quantity based on observed data: thus the rule and its result are distinguished....
of a population mean. However, different samples drawn from that same population would in general have different values of the sample mean. The standard error of the mean (i.e., of using the sample mean as a method of estimating the population mean) is the standard deviation of those sample means over all possible samples (of a given size) drawn from the population. Secondly, the standard error of the mean can refer to an estimate of that standard deviation, computed from the sample of data being analyzed at the time.
A way for remembering the term standard error is that, as long as the estimator is unbiased, the standard deviation of the error
Errors and residuals in statistics
In statistics and optimization, statistical errors and residuals are two closely related and easily confused measures of the deviation of a sample from its "theoretical value"...
(the difference between the estimate and the true value) is the same as the standard deviation of the estimates themselves; this is true since the standard deviation of the difference between the random variable and its expected value is equal to the standard deviation of a random variable itself.
In practical applications, the true value of the standard deviation (of the error) is usually unknown. As a result, the term standard error is often used to refer to an estimate of this unknown quantity. In such cases it is important to be clear about what has been done and to attempt to take proper account of the fact that the standard error is only an estimate. Unfortunately, this is not often possible and it may then be better to use an approach that avoids using a standard error, for example by using maximum likelihood
Maximum likelihood
In statistics, maximum-likelihood estimation is a method of estimating the parameters of a statistical model. When applied to a data set and given a statistical model, maximum-likelihood estimation provides estimates for the model's parameters....
or a more formal approach to deriving confidence interval
Confidence interval
In statistics, a confidence interval is a particular kind of interval estimate of a population parameter and is used to indicate the reliability of an estimate. It is an observed interval , in principle different from sample to sample, that frequently includes the parameter of interest, if the...
s. One well-known case where a proper allowance can be made arises where Student's t-distribution is used to provide a confidence interval
Confidence interval
In statistics, a confidence interval is a particular kind of interval estimate of a population parameter and is used to indicate the reliability of an estimate. It is an observed interval , in principle different from sample to sample, that frequently includes the parameter of interest, if the...
for an estimated mean or difference of means. In other cases, the standard error may usefully be used to provide an indication of the size of the uncertainty, but its formal or semi-formal use to provide confidence intervals or tests should be avoided unless the sample size is at least moderately large. Here "large enough" would depend on the particular quantities being analyzed (see power
Statistical power
The power of a statistical test is the probability that the test will reject the null hypothesis when the null hypothesis is actually false . The power is in general a function of the possible distributions, often determined by a parameter, under the alternative hypothesis...
).
In regression analysis
Regression analysis
In statistics, regression analysis includes many techniques for modeling and analyzing several variables, when the focus is on the relationship between a dependent variable and one or more independent variables...
, the term "standard error" is also used in the phrase standard error of the regression to mean the ordinary least squares
Ordinary least squares
In statistics, ordinary least squares or linear least squares is a method for estimating the unknown parameters in a linear regression model. This method minimizes the sum of squared vertical distances between the observed responses in the dataset and the responses predicted by the linear...
estimate of the standard deviation of the underlying errors
Errors and residuals in statistics
In statistics and optimization, statistical errors and residuals are two closely related and easily confused measures of the deviation of a sample from its "theoretical value"...
.
Standard error of the mean
The standard error of the mean (SEM) is the standard deviation of the sampleSample (statistics)
In statistics, a sample is a subset of a population. Typically, the population is very large, making a census or a complete enumeration of all the values in the population impractical or impossible. The sample represents a subset of manageable size...
mean estimate of a population
Statistical population
A statistical population is a set of entities concerning which statistical inferences are to be drawn, often based on a random sample taken from the population. For example, if we were interested in generalizations about crows, then we would describe the set of crows that is of interest...
mean. (It can also be viewed as the standard deviation of the error in the sample mean relative to the true mean, since the sample mean is an unbiased estimator.) SEM is usually estimated by the sample estimate of the population standard deviation
Standard deviation
Standard deviation is a widely used measure of variability or diversity used in statistics and probability theory. It shows how much variation or "dispersion" there is from the average...
(sample standard deviation) divided by the square root of the sample size (assuming statistical independence of the values in the sample):

where
- s is the sample standard deviation (i.e., the sample-based estimate of the standard deviation of the population), and
- n is the size (number of observations) of the sample.
This estimate may be compared with the formula for the true standard deviation of the sample mean:

where
- σ is the standard deviationStandard deviationStandard deviation is a widely used measure of variability or diversity used in statistics and probability theory. It shows how much variation or "dispersion" there is from the average...
of the population.
This formula may be derived from what we know about the variance of a sum of independent random variables.
- If
 ,
,  , ...,
, ...,  are
are  independent observations from a population that has a mean
independent observations from a population that has a mean  and standard deviation
and standard deviation  , then the variance of the total
, then the variance of the total  is
is  .
. - The variance of
 must be
must be  .
. - And the standard deviation of
 must be
must be  .
. - Of course,
 is the sample mean
is the sample mean  .
.
Note: the standard error and the standard deviation of small samples tend to systematically underestimate the population standard error and deviations: the standard error of the mean is a biased estimator of the population standard error. With n = 2 the underestimate is about 25%, but for n = 6 the underestimate is only 5%. Gurland and Tripathi (1971) provide a correction and equation for this effect. Sokal and Rohlf (1981) give an equation of the correction factor for small samples of n < 20. See unbiased estimation of standard deviation
Unbiased estimation of standard deviation
The question of unbiased estimation of a standard deviation arises in statistics mainly as question in statistical theory. Except in some important situations, outlined later, the task has little relevance to applications of statistics since its need is avoided by standard procedures, such as the...
for further discussion.
A practical result: Decreasing the uncertainty in a mean value estimate by a factor of two requires acquiring four times as many observations in the sample. Or decreasing standard error by a factor of ten requires a hundred times as many observations.
Assumptions and usage
If the data are assumed to be normally distributed, quantileQuantile
Quantiles are points taken at regular intervals from the cumulative distribution function of a random variable. Dividing ordered data into q essentially equal-sized data subsets is the motivation for q-quantiles; the quantiles are the data values marking the boundaries between consecutive subsets...
s of the normal distribution and the sample mean and standard error can be used to calculate approximate confidence intervals for the mean. The following expressions can be used to calculate the upper and lower 95% confidence limits, where
 is equal to the sample mean,
is equal to the sample mean,  is equal to the standard error for the sample mean, and 1.96
is equal to the standard error for the sample mean, and 1.961.96
1.96 is the approximate value of the 97.5 percentile point of the normal distribution used in probability and statistics. 95% of the area under a normal curve lies within roughly 1.96 standard deviations of the mean, and due to the central limit theorem, this number is therefore used in the...
is the .975 quantile of the normal distribution:
- Upper 95% Limit =

- Lower 95% Limit =

In particular, the standard error of a sample statistic (such as sample mean) is the estimated standard deviation of the error in the process by which it was generated. In other words, it is the standard deviation of the sampling distribution
Sampling distribution
In statistics, a sampling distribution or finite-sample distribution is the probability distribution of a given statistic based on a random sample. Sampling distributions are important in statistics because they provide a major simplification on the route to statistical inference...
of the sample statistic. The notation for standard error can be any one of
 ,
,  (for standard error of measurement or mean), or
(for standard error of measurement or mean), or  .
.Standard errors provide simple measures of uncertainty in a value and are often used because:
- If the standard error of several individual quantities is known then the standard error of some functionFunction (mathematics)In mathematics, a function associates one quantity, the argument of the function, also known as the input, with another quantity, the value of the function, also known as the output. A function assigns exactly one output to each input. The argument and the value may be real numbers, but they can...
of the quantities can be easily calculated in many cases; - Where the probability distributionProbability distributionIn probability theory, a probability mass, probability density, or probability distribution is a function that describes the probability of a random variable taking certain values....
of the value is known, it can be used to calculate a good approximation to an exact confidence intervalConfidence intervalIn statistics, a confidence interval is a particular kind of interval estimate of a population parameter and is used to indicate the reliability of an estimate. It is an observed interval , in principle different from sample to sample, that frequently includes the parameter of interest, if the...
; and - Where the probability distribution is unknown, relationships like ChebyshevChebyshev's inequalityIn probability theory, Chebyshev’s inequality guarantees that in any data sample or probability distribution,"nearly all" values are close to the mean — the precise statement being that no more than 1/k2 of the distribution’s values can be more than k standard deviations away from the mean...
's or the Vysochanskiï-Petunin inequalityVysochanskiï-Petunin inequalityIn probability theory, the Vysochanskij–Petunin inequality gives a lower bound for the probability that a random variable with finite variance lies within a certain number of standard deviations of the variable's mean, or equivalently an upper bound for the probability that it lies further away....
can be used to calculate a conservative confidence interval - As the sample sizeSample sizeSample size determination is the act of choosing the number of observations to include in a statistical sample. The sample size is an important feature of any empirical study in which the goal is to make inferences about a population from a sample...
tends to infinity the central limit theoremCentral limit theoremIn probability theory, the central limit theorem states conditions under which the mean of a sufficiently large number of independent random variables, each with finite mean and variance, will be approximately normally distributed. The central limit theorem has a number of variants. In its common...
guarantees that the sampling distribution of the mean is asymptotically normal.
Correction for finite population
The formula given above for the standard error assumes that the sample size is much smaller than the population size, so that the population can be considered to be effectively infinite in size. When the sampling fractionSampling fraction
In sampling theory, sampling fraction is the ratio of sample size to population size or, in the context of stratified sampling, the ratio of the sample size to the size of the stratum....
is large (approximately at 5% or more), the estimate of the error must be corrected by multiplying by a "finite population correction"
-

to account for the added precision gained by sampling close to a larger percentage of the population. The effect of the FPC is that the error becomes zero when the sample size n is equal to the population size N.
Correction for correlation in the sample
If values of the measured quantity A are not statistically independent but have been obtained from known locations in parameter space x, an unbiased estimate of the true standard error of the mean (actually a correction on the standard deviation part) may be obtained by multiplying the calculated standard error of the sample by the factor f:

where the sample bias coefficient ρ is the widely used Prais-Winsten estimate of the autocorrelationAutocorrelationAutocorrelation is the cross-correlation of a signal with itself. Informally, it is the similarity between observations as a function of the time separation between them...
-coefficient (a quantity between -1 and 1) for all sample point pairs. This approximate formula is for moderate to large sample sizes; the reference gives the exact formulas for any sample size, and can be applied to heavily autocorrelated time series like Wall Street stock quotes. Moreover this formula works for positive and negative ρ alike. See also unbiased estimation of standard deviationUnbiased estimation of standard deviationThe question of unbiased estimation of a standard deviation arises in statistics mainly as question in statistical theory. Except in some important situations, outlined later, the task has little relevance to applications of statistics since its need is avoided by standard procedures, such as the...
for more discussion.
Relative standard error
The relative standard error (RSE) is simply the standard error divided by the mean and expressed as a percentage. For example, consider two surveys of household income that both result in a sample mean of $50,000. If one survey has a standard error of $10,000 and the other has a standard error of $5,000, then the relative standard errors are 20% and 10% respectively. The survey with the lower relative standard error has a more precise measurement since there is less variance around the mean. In fact, data organizations often set reliability standards that their data must reach before publication. For example, the U.S. National Center for Health Statistics typically does not report an estimate if the relative standard error exceeds 30%. (NCHS also typically requires at least 30 observations for an estimate to be reported.)