

Reinforcement learning
Encyclopedia
Inspired by behaviorist psychology
, reinforcement learning is an area of machine learning
in computer science
, concerned with how an agent ought to take actions in an environment so as to maximize some notion of cumulative reward. The problem, due to its generality, is studied in many other disciplines, such as control theory
, operations research
, information theory
, simulation-based optimization, statistics
, and Genetic Algorithm
s. In the operations research and control literature the field where reinforcement learning methods are studied is called approximate dynamic programming. The problem has been studied in the theory of optimal control, though most studies there are concerned with existence of optimal solutions and their characterization, and not with the learning or approximation aspects.
In economics
and game theory
, reinforcement learning may be used to explain how equilibrium may arise under bounded rationality
.
In machine learning, the environment is typically formulated as a Markov decision process
(MDP), and many reinforcement learning algorithms for this context are highly related to dynamic programming
techniques. The main difference to these classical techniques is that reinforcement learning algorithms do not need the knowledge of the MDP and they target large MDPs where exact methods become infeasible.
Reinforcement learning differs from standard supervised learning
in that correct input/output pairs are never presented, nor sub-optimal actions explicitly corrected. Further, there is a focus on on-line performance, which involves finding a balance between exploration (of uncharted territory) and exploitation (of current knowledge). The exploration vs. exploitation trade-off in reinforcement learning has been most thoroughly studied through the multi-armed bandit
problem and in finite MDPs.
The basic reinforcement learning model consists of:
The rules are often stochastic. The observation typically involves the scalar immediate reward associated to the last transition.
In many works, the agent is also assumed to observe the current environmental state, in which case we talk about full observability, whereas in the opposing case we talk about partial observability. Sometimes the set of actions available to the agent is restricted (e.g., you cannot spend more money than what you possess).
A reinforcement learning agent interacts with its environment in discrete time steps.
At each time , the agent receives an observation
, the agent receives an observation  , which typically includes the reward
, which typically includes the reward 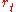 .
.
It then chooses an action from the set of actions available, which is subsequently sent to the environment.
from the set of actions available, which is subsequently sent to the environment.
The environment moves to a new state and the reward
and the reward  associated with the transition
associated with the transition 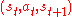 is determined.
is determined.
The goal of a reinforcement learning agent is to collect as much reward as possible. The agent
can choose any action as a function of the history and it can even randomize its action selection.
When the agent's performance is compared to that of an agent which acts optimally from the beginning, the difference in performance gives rise to the notion of regret.
Note that in order to act near optimally, the agent must reason about the long term consequences of its actions: In order to maximize my future income I better go to school now, although the immediate monetary reward associated with this might be negative.
Thus, reinforcement learning is particularly well suited to problems which include a long-term versus short-term reward trade-off. It has been applied successfully to various problems, including robot control
, elevator scheduling, telecommunications, backgammon
and checkers (Sutton and Barto 1998, Chapter 11).
Two components make reinforcement learning powerful:
The use of samples to optimize performance and the use of function approximation to deal with large environments.
Thanks to these two key components, reinforcement learning can be used in large environments in any of the following situations:
The first two of these problems could be considered planning problems (since some form of the model is available), while the last one could be considered as a genuine learning problem. However, under a reinforcement learning methodology both planning problems would be converted to machine learning
problems.
However, due to the lack of algorithms that would provably scale well with the number of states (or scale to problems with infinite state spaces), in practice people resort to simple exploration methods. One such method is -greedy, when the agent chooses the action that it believes has the best long-term effect with probability
-greedy, when the agent chooses the action that it believes has the best long-term effect with probability  , and it chooses an action uniformly at random, otherwise. Here,
, and it chooses an action uniformly at random, otherwise. Here, 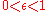 is a tuning parameter, which is sometimes changed, either according to a fixed schedule (making the agent explore less as time goes by), or adaptively based on some heuristics (Tokic & Palm, 2011).
is a tuning parameter, which is sometimes changed, either according to a fixed schedule (making the agent explore less as time goes by), or adaptively based on some heuristics (Tokic & Palm, 2011).
 and any initial distribution over the states. Given a fixed initial distribution
and any initial distribution over the states. Given a fixed initial distribution  , we can thus assign the expected return
, we can thus assign the expected return 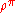 to policy
to policy  :
:
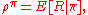
where the random variable denotes the return and is defined by
denotes the return and is defined by

where is the reward received after the
is the reward received after the  -th transition, the initial state is sampled at random from
-th transition, the initial state is sampled at random from  and actions are selected by policy
and actions are selected by policy  . Here,
. Here,  denotes the (random) time when a terminal state is reached, i.e., the time when the episode terminates.
denotes the (random) time when a terminal state is reached, i.e., the time when the episode terminates.
In the case of non-episodic problems the return is often discounted,

giving rise to the total expected discounted reward criterion. Here is the so-called discount-factor. Since the undiscounted return is a special case of the discounted return, from now on we will assume discounting. Although this looks innocent enough, discounting is in fact problematic if one cares about online performance. This is because discounting makes the initial time steps more important. Since a learning agent is likely to make mistakes during the first few steps after its "life" starts, no uninformed learning algorithm can achieve near-optimal performance under discounting even if the class of environments is restricted to that of finite MDPs. (This does not mean though that, given enough time, a learning agent cannot figure how to act near-optimally, if time was restarted.)
is the so-called discount-factor. Since the undiscounted return is a special case of the discounted return, from now on we will assume discounting. Although this looks innocent enough, discounting is in fact problematic if one cares about online performance. This is because discounting makes the initial time steps more important. Since a learning agent is likely to make mistakes during the first few steps after its "life" starts, no uninformed learning algorithm can achieve near-optimal performance under discounting even if the class of environments is restricted to that of finite MDPs. (This does not mean though that, given enough time, a learning agent cannot figure how to act near-optimally, if time was restarted.)
The problem then is to specify an algorithm that can be used to find a policy with maximum expected return.
From the theory of MDPs it is known that, without loss of generality, the search can be restricted to the set of the so-called stationary policies. A policy is called stationary if the action-distribution returned by it depends only the last state visited (which is part of the observation history of the agent, by our simplifying assumption). In fact, the search can be further restricted to deterministic stationary policies. A deterministic stationary policy is one which deterministically selects actions based on the current state. Since any such policy can be identified with a mapping from the set of states to the set of action, these policies can be identified with such mappings with no loss of generality.
approach entails the following two steps:
One problem with this is that the number of policies can be extremely large, or even infinite. Another is that variance of the returns might be large, in which case a large number of samples will be required to accurately estimate the return of each policy.
These problems can be ameliorated if we assume some structure and perhaps allow samples generated from one policy to influence the estimates made for another. The two main approaches for achieving this are value function estimation and direct policy search.
These methods rely on the theory of MDPs, where optimality is defined in a sense which is stronger than the above one: A policy is called optimal if it achieves the best expected return from any initial state (i.e., initial distributions play no role in this definition). Again, one can always find an optimal policy amongst stationary policies.
To define optimality in a formal manner, define the value of a policy by
by
where stands for the random return associated with following
stands for the random return associated with following  from the initial state
from the initial state  .
.
Define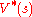 as the maximum possible value of
as the maximum possible value of 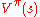 , where
, where  is allowed to change:
is allowed to change:
A policy which achieves these optimal values in each state is called optimal. Clearly, a policy optimal in this strong sense is also optimal in the sense that it maximizes the expected return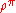 , since
, since 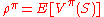 , where
, where  is a state randomly sampled from the distribution
is a state randomly sampled from the distribution  .
.
Although state-values suffice to define optimality, it will prove to be useful to define action-values. Given a state , an action
, an action  and a policy
and a policy  , the action-value of the pair
, the action-value of the pair 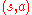 under
under  is defined by
is defined by

where, now, stands for the random return associated with first taking action
stands for the random return associated with first taking action  in state
in state  and following
and following  , thereafter.
, thereafter.
It is well-known from the theory of MDPs that if someone gives us for an optimal policy, we can always choose optimal actions (and thus act optimally) by simply choosing the action with the highest value at each state.
for an optimal policy, we can always choose optimal actions (and thus act optimally) by simply choosing the action with the highest value at each state.
The action-value function of such an optimal policy is called the optimal action-value function and is denoted by .
.
In summary, the knowledge of the optimal action-value function alone suffices to know how to act optimally.
Assuming full knowledge of the MDP, there are two basic approaches to compute the optimal action-value function, value iteration and policy iteration.
Both algorithms compute a sequence of functions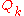 (
(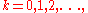 ) which converge to
) which converge to  .
.
Computing these functions involves computing expectations over the whole state-space, which is impractical for all, but the smallest (finite) MDPs, never mind the case when the MDP is unknown.
In reinforcement learning methods the expectations are approximated by averaging over samples and one uses function approximation techniques to cope with the need to represent value functions over large state-action spaces.
Policy iteration consists of two steps: policy evaluation and policy improvement.
The Monte Carlo methods are used in the policy evaluation step.
In this step, given a stationary, deterministic policy , the goal is to compute the function values
, the goal is to compute the function values 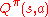 (or a good approximation to them) for all state-action pairs
(or a good approximation to them) for all state-action pairs 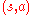 .
.
Assume (for simplicity) that the MDP is finite and in fact a table representing the action-values fits into the memory.
Further, assume that the problem is episodic and after each episode a new one starts from some random initial state.
Then, the estimate of the value of a given state-action pair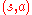 can be computed by simply averaging the sampled returns which originated from
can be computed by simply averaging the sampled returns which originated from 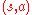 over time.
over time.
Given enough time, this procedure can thus construct a precise estimate of the action-value function
of the action-value function  .
.
This finishes the description of the policy evaluation step.
In the policy improvement step, as it is done in the standard policy iteration algorithm, the next policy is obtained by computing a greedy policy with respect to : Given a state
: Given a state  , this new policy returns an action that maximizes
, this new policy returns an action that maximizes 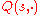 . In practice one often avoids computing and storing the new policy, but uses lazy evaluation
. In practice one often avoids computing and storing the new policy, but uses lazy evaluation
to defer the computation of the maximizing actions to when they are actually needed.
A few problems with this procedure are as follows:
The second issue can be corrected within the algorithm by allowing trajectories to contribute to any state-action pair in them.
This may also help to some extent with the third problem, although a better solution when returns have high variance is to use Sutton's temporal difference (TD) methods which are based on the recursive Bellman equation. Note that the computation in TD methods can be incremental (when after each transition the memory is changed and the transition is thrown away), or batch (when the transitions are collected and then the estimates are computed once based on a large number of transitions). Batch methods, a prime example of which is the least-squares temporal difference method due to Bradtke and Barto (1996), may use the information in the samples better, whereas incremental methods are the only choice when batch methods become infeasible due to their high computational or memory complexity. In addition, there exist methods that try to unify the advantages of the two approaches. Methods based on temporal differences also overcome the second but last issue.
In order to address the last issue mentioned in the previous section, function approximation methods are used.
In linear function approximation one starts with a mapping that assigns a finite dimensional vector to each state-action pair. Then, the action values of a state-action pair
that assigns a finite dimensional vector to each state-action pair. Then, the action values of a state-action pair 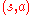 are obtained by linearly combining the components of
are obtained by linearly combining the components of 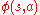 with some weights
with some weights 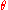 :
:
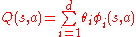 .
.
The algorithms then adjust the weights, instead of adjusting the values associated with the individual state-action pairs.
However, linear function approximation is not the only choice.
More recently, methods based on ideas from nonparametric statistics (which can be seen to construct their own features) have been explored.
So far, the discussion was restricted to how policy iteration can be used as a basis of the designing reinforcement learning algorithms. Equally importantly, value iteration can also be used as a starting point, giving rise to the Q-Learning
algorithm (Watkins 1989) and its many variants.
The problem with methods that use action-values is that they may need highly precise estimates of the competing action values, which can be hard to obtain when the returns are noisy. Though this problem is mitigated to some extent by temporal difference methods and if one uses the so-called compatible function approximation method, more work remains to be done to increase generality and efficiency. Another problem specific to temporal difference methods comes from their reliance on the recursive Bellman equation. Most temporal difference methods have a so-called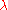 parameter
parameter 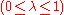 that allows one to continuously interpolate between Monte-Carlo methods (which do not rely on the Bellman equations) and the basic temporal difference methods (which rely entirely on the Bellman equations), which can thus be effective in palliating this issue.
that allows one to continuously interpolate between Monte-Carlo methods (which do not rely on the Bellman equations) and the basic temporal difference methods (which rely entirely on the Bellman equations), which can thus be effective in palliating this issue.
. The two approaches available are gradient-based and gradient-free methods.
Gradient-based methods (giving rise to the so-called policy gradient methods) start with a mapping from a finite dimensional (parameter) space to the space of policies: given the parameter vector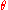 , let
, let  denote the policy associated to
denote the policy associated to 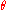 .
.
Define the performance function by
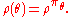
Under mild conditions this function will be differentiable as a function of the parameter vector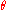 .
.
If the gradient of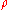 was known, one could use gradient ascent
was known, one could use gradient ascent
.
Since an analytic expression for the gradient is not available, one must rely on a noisy estimate.
Such an estimate can be constructed in many ways, giving rise to algorithms like Williams' REINFORCE method (which is also known as the likelihood ratio method in the simulation-based optimization literature).
Policy gradient methods have received a lot of attention in the last couple of years (e.g., Peters et al. (2003)), but they remain an active field.
The issue with many of these methods is that they may get stuck in local optima (as they are based on local search
).
A large class of methods avoids relying on gradient information.
These include simulated annealing
, cross-entropy search
or methods of evolutionary computation
.
Many gradient-free methods can achieve (in theory and in the limit) a global optimum.
In a number of cases they have indeed demonstrated remarkable performance.
The issue with policy search methods is that they may converge slowly if the information based on which they act is noisy.
For example, this happens when in episodic problems the trajectories are long and the variance of the returns is large. As argued beforehand, value-function based methods that rely on temporal differences might help in this case. In recent years, several actor-critic algorithms have been proposed following this idea and were demonstrated to perform well on various benchmarks.
Both the asymptotic and finite-sample behavior of most algorithms is well-understood.
As mentioned beforehand, algorithms with provably good online performance (addressing the exploration issue) are known.
The theory of large MDPs needs more work. Efficient exploration is largely untouched (except for the case of bandit problems).
Although finite-time performance bounds appeared for many algorithms in the recent years, these bounds are expected to be rather loose and thus more work is needed to better understand the relative advantages, as well as the limitations of these algorithms.
For incremental algorithm asymptotic convergence issues have been settled. Recently, new incremental, temporal-difference-based algorithms have appeared which converge under a much wider set of conditions than was previously possible (for example, when used with arbitrary, smooth function approximation).
adaptive methods which work with fewer (or no) parameters under a large number of conditions,
addressing the exploration problem in large MDPs,
large scale empirical evaluations,
learning and acting under partial information
(e.g., using Predictive State Representation
),
modular and hierarchical reinforcement learning,
improving existing value-function and policy search methods,
algorithms that work well with large (or continuous) action spaces,
transfer learning,
lifelong learning,
efficient sample-based planning (e.g., based on Monte-Carlo tree search).
Multiagent or Distributed Reinforcement Learning is also a topic of interest in current research.
There is also a growing interest in real life applications of reinforcement learning.
Successes of reinforcement learning are collected on
here and
here.
Reinforcement learning algorithms such as TD learning are also being investigated as a model for Dopamine
-based learning in the brain. In this model, the dopaminergic projections from the substantia nigra to the basal ganglia function as the prediction error. Reinforcement learning has also been used as a part of the model for human skill learning, especially in relation to the interaction between implicit and explicit learning in skill acquisition (the first publication on this application was in 1995-1996, and there have been many follow-up studies). See http://webdocs.cs.ualberta.ca/~sutton/RL-FAQ.html#behaviorism for further details of these research areas above.
Behaviorism
Behaviorism , also called the learning perspective , is a philosophy of psychology based on the proposition that all things that organisms do—including acting, thinking, and feeling—can and should be regarded as behaviors, and that psychological disorders are best treated by altering behavior...
, reinforcement learning is an area of machine learning
Machine learning
Machine learning, a branch of artificial intelligence, is a scientific discipline concerned with the design and development of algorithms that allow computers to evolve behaviors based on empirical data, such as from sensor data or databases...
in computer science
Computer science
Computer science or computing science is the study of the theoretical foundations of information and computation and of practical techniques for their implementation and application in computer systems...
, concerned with how an agent ought to take actions in an environment so as to maximize some notion of cumulative reward. The problem, due to its generality, is studied in many other disciplines, such as control theory
Control theory
Control theory is an interdisciplinary branch of engineering and mathematics that deals with the behavior of dynamical systems. The desired output of a system is called the reference...
, operations research
Operations research
Operations research is an interdisciplinary mathematical science that focuses on the effective use of technology by organizations...
, information theory
Information theory
Information theory is a branch of applied mathematics and electrical engineering involving the quantification of information. Information theory was developed by Claude E. Shannon to find fundamental limits on signal processing operations such as compressing data and on reliably storing and...
, simulation-based optimization, statistics
Statistics
Statistics is the study of the collection, organization, analysis, and interpretation of data. It deals with all aspects of this, including the planning of data collection in terms of the design of surveys and experiments....
, and Genetic Algorithm
Genetic algorithm
A genetic algorithm is a search heuristic that mimics the process of natural evolution. This heuristic is routinely used to generate useful solutions to optimization and search problems...
s. In the operations research and control literature the field where reinforcement learning methods are studied is called approximate dynamic programming. The problem has been studied in the theory of optimal control, though most studies there are concerned with existence of optimal solutions and their characterization, and not with the learning or approximation aspects.
In economics
Economics
Economics is the social science that analyzes the production, distribution, and consumption of goods and services. The term economics comes from the Ancient Greek from + , hence "rules of the house"...
and game theory
Game theory
Game theory is a mathematical method for analyzing calculated circumstances, such as in games, where a person’s success is based upon the choices of others...
, reinforcement learning may be used to explain how equilibrium may arise under bounded rationality
Bounded rationality
Bounded rationality is the idea that in decision making, rationality of individuals is limited by the information they have, the cognitive limitations of their minds, and the finite amount of time they have to make a decision...
.
In machine learning, the environment is typically formulated as a Markov decision process
Markov decision process
Markov decision processes , named after Andrey Markov, provide a mathematical framework for modeling decision-making in situations where outcomes are partly random and partly under the control of a decision maker. MDPs are useful for studying a wide range of optimization problems solved via...
(MDP), and many reinforcement learning algorithms for this context are highly related to dynamic programming
Dynamic programming
In mathematics and computer science, dynamic programming is a method for solving complex problems by breaking them down into simpler subproblems. It is applicable to problems exhibiting the properties of overlapping subproblems which are only slightly smaller and optimal substructure...
techniques. The main difference to these classical techniques is that reinforcement learning algorithms do not need the knowledge of the MDP and they target large MDPs where exact methods become infeasible.
Reinforcement learning differs from standard supervised learning
Supervised learning
Supervised learning is the machine learning task of inferring a function from supervised training data. The training data consist of a set of training examples. In supervised learning, each example is a pair consisting of an input object and a desired output value...
in that correct input/output pairs are never presented, nor sub-optimal actions explicitly corrected. Further, there is a focus on on-line performance, which involves finding a balance between exploration (of uncharted territory) and exploitation (of current knowledge). The exploration vs. exploitation trade-off in reinforcement learning has been most thoroughly studied through the multi-armed bandit
Multi-armed bandit
In statistics, particularly in the design of sequential experiments, a multi-armed bandit takes its name from a traditional slot machine . Multiple levers are considered in the motivating applications in statistics. When pulled, each lever provides a reward drawn from a distribution associated...
problem and in finite MDPs.
The basic reinforcement learning model consists of:
- a set of environment states
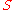 ;
; - a set of actions
 ;
; - rules of transitioning between states;
- rules that determine the scalar immediate reward of a transition; and
- rules that describe what the agent observes.
The rules are often stochastic. The observation typically involves the scalar immediate reward associated to the last transition.
In many works, the agent is also assumed to observe the current environmental state, in which case we talk about full observability, whereas in the opposing case we talk about partial observability. Sometimes the set of actions available to the agent is restricted (e.g., you cannot spend more money than what you possess).
A reinforcement learning agent interacts with its environment in discrete time steps.
At each time
, the agent receives an observation , which typically includes the reward .It then chooses an action
from the set of actions available, which is subsequently sent to the environment.The environment moves to a new state
and the reward associated with the transition is determined.The goal of a reinforcement learning agent is to collect as much reward as possible. The agent
Software agent
In computer science, a software agent is a piece of software that acts for a user or other program in a relationship of agency, which derives from the Latin agere : an agreement to act on one's behalf...
can choose any action as a function of the history and it can even randomize its action selection.
When the agent's performance is compared to that of an agent which acts optimally from the beginning, the difference in performance gives rise to the notion of regret.
Note that in order to act near optimally, the agent must reason about the long term consequences of its actions: In order to maximize my future income I better go to school now, although the immediate monetary reward associated with this might be negative.
Thus, reinforcement learning is particularly well suited to problems which include a long-term versus short-term reward trade-off. It has been applied successfully to various problems, including robot control
Robot control
-See also:* Control theory* Mobile robot navigation* Robot kinematics* Simultaneous localization and mapping* Robot locomotion* Motion planning* Robot learning* Vision Based Robot Control...
, elevator scheduling, telecommunications, backgammon
Backgammon
Backgammon is one of the oldest board games for two players. The playing pieces are moved according to the roll of dice, and players win by removing all of their pieces from the board. There are many variants of backgammon, most of which share common traits...
and checkers (Sutton and Barto 1998, Chapter 11).
Two components make reinforcement learning powerful:
The use of samples to optimize performance and the use of function approximation to deal with large environments.
Thanks to these two key components, reinforcement learning can be used in large environments in any of the following situations:
- A model of the environment is known, but an analytic solution is not available;
- Only a simulation model of the environment is given (the subject of simulation-based optimization);
- The only way to collect information about the environment is by interacting with it.
The first two of these problems could be considered planning problems (since some form of the model is available), while the last one could be considered as a genuine learning problem. However, under a reinforcement learning methodology both planning problems would be converted to machine learning
Machine learning
Machine learning, a branch of artificial intelligence, is a scientific discipline concerned with the design and development of algorithms that allow computers to evolve behaviors based on empirical data, such as from sensor data or databases...
problems.
Exploration
The reinforcement learning problem as described requires clever exploration mechanisms. Randomly selecting actions is known to give rise to very poor performance. The case of (small) finite MDPs is relatively well understood by now.However, due to the lack of algorithms that would provably scale well with the number of states (or scale to problems with infinite state spaces), in practice people resort to simple exploration methods. One such method is
-greedy, when the agent chooses the action that it believes has the best long-term effect with probability , and it chooses an action uniformly at random, otherwise. Here, is a tuning parameter, which is sometimes changed, either according to a fixed schedule (making the agent explore less as time goes by), or adaptively based on some heuristics (Tokic & Palm, 2011).Algorithms for control learning
Even if the issue of exploration is disregarded and even if the state was observable (which we assume from now on), the problem remains to find out which actions are good based on past experience.Criterion of optimality
For simplicity, assume for a moment that the problem studied is episodic, an episode ending when some terminal state is reached. Assume further that no matter what course of actions the agent takes, termination is inevitable with probability one. Under some additional mild regularity conditions the expectation of the total reward is then well-defined, for any policy and any initial distribution over the states. Given a fixed initial distribution , we can thus assign the expected return to policy :where the random variable
denotes the return and is defined bywhere
is the reward received after the -th transition, the initial state is sampled at random from and actions are selected by policy . Here, denotes the (random) time when a terminal state is reached, i.e., the time when the episode terminates.In the case of non-episodic problems the return is often discounted,
giving rise to the total expected discounted reward criterion. Here
is the so-called discount-factor. Since the undiscounted return is a special case of the discounted return, from now on we will assume discounting. Although this looks innocent enough, discounting is in fact problematic if one cares about online performance. This is because discounting makes the initial time steps more important. Since a learning agent is likely to make mistakes during the first few steps after its "life" starts, no uninformed learning algorithm can achieve near-optimal performance under discounting even if the class of environments is restricted to that of finite MDPs. (This does not mean though that, given enough time, a learning agent cannot figure how to act near-optimally, if time was restarted.)The problem then is to specify an algorithm that can be used to find a policy with maximum expected return.
From the theory of MDPs it is known that, without loss of generality, the search can be restricted to the set of the so-called stationary policies. A policy is called stationary if the action-distribution returned by it depends only the last state visited (which is part of the observation history of the agent, by our simplifying assumption). In fact, the search can be further restricted to deterministic stationary policies. A deterministic stationary policy is one which deterministically selects actions based on the current state. Since any such policy can be identified with a mapping from the set of states to the set of action, these policies can be identified with such mappings with no loss of generality.
Brute force
The brute forceBrute force
Brute force may refer to any of several problem-solving methods involving the evaluation of multiple possible answer for fitness. The term has also been used as a stage name, book title, etc.In mathematics:...
approach entails the following two steps:
- For each possible policy, sample returns while following it
- Choose the policy with the largest expected return
One problem with this is that the number of policies can be extremely large, or even infinite. Another is that variance of the returns might be large, in which case a large number of samples will be required to accurately estimate the return of each policy.
These problems can be ameliorated if we assume some structure and perhaps allow samples generated from one policy to influence the estimates made for another. The two main approaches for achieving this are value function estimation and direct policy search.
Value function approaches
Value function approaches attempt to find a policy that maximizes the return by maintaining a set of estimates of expected returns for some policy (usually either the "current" or the optimal one).These methods rely on the theory of MDPs, where optimality is defined in a sense which is stronger than the above one: A policy is called optimal if it achieves the best expected return from any initial state (i.e., initial distributions play no role in this definition). Again, one can always find an optimal policy amongst stationary policies.
To define optimality in a formal manner, define the value of a policy
by
where
stands for the random return associated with following from the initial state .Define
as the maximum possible value of , where is allowed to change: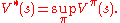
A policy which achieves these optimal values in each state is called optimal. Clearly, a policy optimal in this strong sense is also optimal in the sense that it maximizes the expected return
, since , where is a state randomly sampled from the distribution .Although state-values suffice to define optimality, it will prove to be useful to define action-values. Given a state
, an action and a policy , the action-value of the pair under is defined bywhere, now,
stands for the random return associated with first taking action in state and following , thereafter.It is well-known from the theory of MDPs that if someone gives us
for an optimal policy, we can always choose optimal actions (and thus act optimally) by simply choosing the action with the highest value at each state.The action-value function of such an optimal policy is called the optimal action-value function and is denoted by
.In summary, the knowledge of the optimal action-value function alone suffices to know how to act optimally.
Assuming full knowledge of the MDP, there are two basic approaches to compute the optimal action-value function, value iteration and policy iteration.
Both algorithms compute a sequence of functions
() which converge to .Computing these functions involves computing expectations over the whole state-space, which is impractical for all, but the smallest (finite) MDPs, never mind the case when the MDP is unknown.
In reinforcement learning methods the expectations are approximated by averaging over samples and one uses function approximation techniques to cope with the need to represent value functions over large state-action spaces.
Monte Carlo methods
The simplest Monte Carlo methods can be used in an algorithm that mimics policy iteration.Policy iteration consists of two steps: policy evaluation and policy improvement.
The Monte Carlo methods are used in the policy evaluation step.
In this step, given a stationary, deterministic policy
, the goal is to compute the function values (or a good approximation to them) for all state-action pairs .Assume (for simplicity) that the MDP is finite and in fact a table representing the action-values fits into the memory.
Further, assume that the problem is episodic and after each episode a new one starts from some random initial state.
Then, the estimate of the value of a given state-action pair
can be computed by simply averaging the sampled returns which originated from over time.Given enough time, this procedure can thus construct a precise estimate
of the action-value function .This finishes the description of the policy evaluation step.
In the policy improvement step, as it is done in the standard policy iteration algorithm, the next policy is obtained by computing a greedy policy with respect to
: Given a state , this new policy returns an action that maximizes . In practice one often avoids computing and storing the new policy, but uses lazy evaluationLazy evaluation
In programming language theory, lazy evaluation or call-by-need is an evaluation strategy which delays the evaluation of an expression until the value of this is actually required and which also avoids repeated evaluations...
to defer the computation of the maximizing actions to when they are actually needed.
A few problems with this procedure are as follows:
- The procedure may waste too much time on evaluating a suboptimal policy;
- It uses samples inefficiently in that a long trajectory is used to improve the estimate only of the single state-action pair that started the trajectory;
- When the returns along the trajectories have high variance, convergence will be slow;
- It works in episodic problems only;
- It works in small, finite MDPs only.
Temporal difference methods
The first issue is easily corrected by allowing the procedure to change the policy (at all, or at some states) before the values settle. However good this sounds, this may be dangerous as this might prevent convergence. Still, most current algorithms implement this idea, giving rise to the class of generalized policy iteration algorithm. We note in passing that actor critic methods belong to this category.The second issue can be corrected within the algorithm by allowing trajectories to contribute to any state-action pair in them.
This may also help to some extent with the third problem, although a better solution when returns have high variance is to use Sutton's temporal difference (TD) methods which are based on the recursive Bellman equation. Note that the computation in TD methods can be incremental (when after each transition the memory is changed and the transition is thrown away), or batch (when the transitions are collected and then the estimates are computed once based on a large number of transitions). Batch methods, a prime example of which is the least-squares temporal difference method due to Bradtke and Barto (1996), may use the information in the samples better, whereas incremental methods are the only choice when batch methods become infeasible due to their high computational or memory complexity. In addition, there exist methods that try to unify the advantages of the two approaches. Methods based on temporal differences also overcome the second but last issue.
In order to address the last issue mentioned in the previous section, function approximation methods are used.
In linear function approximation one starts with a mapping
that assigns a finite dimensional vector to each state-action pair. Then, the action values of a state-action pair are obtained by linearly combining the components of with some weights :.The algorithms then adjust the weights, instead of adjusting the values associated with the individual state-action pairs.
However, linear function approximation is not the only choice.
More recently, methods based on ideas from nonparametric statistics (which can be seen to construct their own features) have been explored.
So far, the discussion was restricted to how policy iteration can be used as a basis of the designing reinforcement learning algorithms. Equally importantly, value iteration can also be used as a starting point, giving rise to the Q-Learning
Q-learning
Q-learning is a reinforcement learning technique that works by learning an action-value function that gives the expected utility of taking a given action in a given state and following a fixed policy thereafter. One of the strengths of Q-learning is that it is able to compare the expected utility...
algorithm (Watkins 1989) and its many variants.
The problem with methods that use action-values is that they may need highly precise estimates of the competing action values, which can be hard to obtain when the returns are noisy. Though this problem is mitigated to some extent by temporal difference methods and if one uses the so-called compatible function approximation method, more work remains to be done to increase generality and efficiency. Another problem specific to temporal difference methods comes from their reliance on the recursive Bellman equation. Most temporal difference methods have a so-called
parameter that allows one to continuously interpolate between Monte-Carlo methods (which do not rely on the Bellman equations) and the basic temporal difference methods (which rely entirely on the Bellman equations), which can thus be effective in palliating this issue.Direct policy search
An alternative method to find a good policy is to search directly in (some subset) of the policy space, in which case the problem becomes an instance of stochastic optimizationStochastic optimization
Stochastic optimization methods are optimization methods that generate and use random variables. For stochastic problems, the random variables appear in the formulation of the optimization problem itself, which involve random objective functions or random constraints, for example. Stochastic...
. The two approaches available are gradient-based and gradient-free methods.
Gradient-based methods (giving rise to the so-called policy gradient methods) start with a mapping from a finite dimensional (parameter) space to the space of policies: given the parameter vector
, let denote the policy associated to .Define the performance function by
Under mild conditions this function will be differentiable as a function of the parameter vector
.If the gradient of
was known, one could use gradient ascentGradient descent
Gradient descent is a first-order optimization algorithm. To find a local minimum of a function using gradient descent, one takes steps proportional to the negative of the gradient of the function at the current point...
.
Since an analytic expression for the gradient is not available, one must rely on a noisy estimate.
Such an estimate can be constructed in many ways, giving rise to algorithms like Williams' REINFORCE method (which is also known as the likelihood ratio method in the simulation-based optimization literature).
Policy gradient methods have received a lot of attention in the last couple of years (e.g., Peters et al. (2003)), but they remain an active field.
The issue with many of these methods is that they may get stuck in local optima (as they are based on local search
Local search (optimization)
In computer science, local search is a metaheuristic method for solving computationally hard optimization problems. Local search can be used on problems that can be formulated as finding a solution maximizing a criterion among a number of candidate solutions...
).
A large class of methods avoids relying on gradient information.
These include simulated annealing
Simulated annealing
Simulated annealing is a generic probabilistic metaheuristic for the global optimization problem of locating a good approximation to the global optimum of a given function in a large search space. It is often used when the search space is discrete...
, cross-entropy search
Cross-entropy method
The cross-entropy method attributed to Reuven Rubinstein is a general Monte Carlo approach tocombinatorial and continuous multi-extremal optimization and importance sampling.The method originated from the field of rare event simulation, where...
or methods of evolutionary computation
Evolutionary computation
In computer science, evolutionary computation is a subfield of artificial intelligence that involves combinatorial optimization problems....
.
Many gradient-free methods can achieve (in theory and in the limit) a global optimum.
In a number of cases they have indeed demonstrated remarkable performance.
The issue with policy search methods is that they may converge slowly if the information based on which they act is noisy.
For example, this happens when in episodic problems the trajectories are long and the variance of the returns is large. As argued beforehand, value-function based methods that rely on temporal differences might help in this case. In recent years, several actor-critic algorithms have been proposed following this idea and were demonstrated to perform well on various benchmarks.
Theory
The theory for small, finite MDPs is quite mature.Both the asymptotic and finite-sample behavior of most algorithms is well-understood.
As mentioned beforehand, algorithms with provably good online performance (addressing the exploration issue) are known.
The theory of large MDPs needs more work. Efficient exploration is largely untouched (except for the case of bandit problems).
Although finite-time performance bounds appeared for many algorithms in the recent years, these bounds are expected to be rather loose and thus more work is needed to better understand the relative advantages, as well as the limitations of these algorithms.
For incremental algorithm asymptotic convergence issues have been settled. Recently, new incremental, temporal-difference-based algorithms have appeared which converge under a much wider set of conditions than was previously possible (for example, when used with arbitrary, smooth function approximation).
Current research
Current research topics include:adaptive methods which work with fewer (or no) parameters under a large number of conditions,
addressing the exploration problem in large MDPs,
large scale empirical evaluations,
learning and acting under partial information
Partially observable Markov decision process
A Partially Observable Markov Decision Process is a generalization of a Markov Decision Process. A POMDP models an agent decision process in which it is assumed that the system dynamics are determined by an MDP, but the agent cannot directly observe the underlying state...
(e.g., using Predictive State Representation
Predictive State Representation
In computer science, a predictive state representation is a dynamical system representation that keeps track of the state of the system using predictions of future observations. A PSR's state is grounded directly to statistics over observable quantities...
),
modular and hierarchical reinforcement learning,
improving existing value-function and policy search methods,
algorithms that work well with large (or continuous) action spaces,
transfer learning,
lifelong learning,
efficient sample-based planning (e.g., based on Monte-Carlo tree search).
Multiagent or Distributed Reinforcement Learning is also a topic of interest in current research.
There is also a growing interest in real life applications of reinforcement learning.
Successes of reinforcement learning are collected on
here and
here.
Reinforcement learning algorithms such as TD learning are also being investigated as a model for Dopamine
Dopamine
Dopamine is a catecholamine neurotransmitter present in a wide variety of animals, including both vertebrates and invertebrates. In the brain, this substituted phenethylamine functions as a neurotransmitter, activating the five known types of dopamine receptors—D1, D2, D3, D4, and D5—and their...
-based learning in the brain. In this model, the dopaminergic projections from the substantia nigra to the basal ganglia function as the prediction error. Reinforcement learning has also been used as a part of the model for human skill learning, especially in relation to the interaction between implicit and explicit learning in skill acquisition (the first publication on this application was in 1995-1996, and there have been many follow-up studies). See http://webdocs.cs.ualberta.ca/~sutton/RL-FAQ.html#behaviorism for further details of these research areas above.
Conferences, journals
Most reinforcement learning papers are published at the major machine learning and AI conferences (ICML, NIPS, AAAI, IJCAI, UAI, AI and Statistics) and journals (JAIR, JMLR, Machine learning journal). Some theory papers are published at COLT and ALT. However, many papers appear in robotics conferences (IROS, ICRA) and the "agent" conference AAMAS. Operations researchers publish their papers at the INFORMS conference and, for example, in the Operation Research, and the Mathematics of Operations Research journals. Control researchers publish their papers at the CDC and ACC conferences, or, e.g., in the journals IEEE Transactions on Automatic Control, or Automatica, although applied works tend to be published in more specialized journals. The Winter Simulation Conference also publishes many relevant papers. Other than this, papers also published in the major conferences of the neural networks, fuzzy, and evolutionary computation communities. The annual IEEE symposium titled Approximate Dynamic Programming and Reinforcement Learning (ADPRL) and the biannual European Workshop on Reinforcement Learning (EWRL) are two regularly held meetings where RL researchers meet.See also
- Marcus Hutter's Universal artificial intelligence, also called AIXI
- Temporal difference learningTemporal difference learningTemporal difference learning is a prediction method. It has been mostly used for solving the reinforcement learning problem. "TD learning is a combination of Monte Carlo ideas and dynamic programming ideas." TD resembles a Monte Carlo method because it learns by sampling the environment according...
- Q learning
- SARSASARSASARSA is an algorithm for learning a Markov decision process policy, used in the reinforcement learning area of machine learning...
- Fictitious playFictitious playIn game theory, fictitious play is a learning rule first introduced by G.W. Brown . In it, each player presumes that the opponents are playing stationary strategies. At each round, each player thus best responds to the empirical frequency of play of his opponent...
- Learning classifier systemLearning classifier systemA learning classifier system, or LCS, is a machine learning system with close links to reinforcement learning and genetic algorithms. First described by John Holland, his LCS consisted of a population of binary rules on which a genetic algorithm altered and selected the best rules.Rule fitness...
- Optimal controlOptimal controlOptimal control theory, an extension of the calculus of variations, is a mathematical optimization method for deriving control policies. The method is largely due to the work of Lev Pontryagin and his collaborators in the Soviet Union and Richard Bellman in the United States.-General method:Optimal...
- Dynamic treatment regimesDynamic treatment regimesIn medical research, a dynamic treatment regime or adaptive treatment strategy is a set of rules for choosing effective treatments for individual patients. The treatment choices made for a particular patient are based on that individual's characteristics and history, with the goal of optimizing...
- Error-driven learningError-driven learningError-driven learning is a sub-area of machine learning concerned with how an agent ought to take actions in an environment so as to minimize some error feedback. It is a type of reinforcement learning....
Implementations
- RL-Glue provides a standard interface that allows you to connect agents, environments, and experiment programs together, even if they are written in different languages.
- Maja Machine Learning Framework The Maja Machine Learning Framework (MMLF) is a general framework for problems in the domain of Reinforcement Learning (RL) written in python.
- Software Tools for Reinforcement Learning (Matlab and Python)
- PyBrain(Python)
- TeachingBox is a Java reinforcement learning framework supporting many features like RBF networks, gradient decent learning methods, ...
- C++ implementation for some well known reinforcement learning algorithms with source.
- OrangeOrange (software)Orange is a component-based data mining and machine learning software suite, featuring friendly yet powerful and flexible visual programming front-end for explorative data analysis and visualization, and Python bindings and libraries for scripting...
, a free data mining software suite, module orngReinforcement
External links
- Reinforcement Learning Repository
- Reinforcement Learning and Artificial Intelligence (Sutton's lab at the University of Alberta)
- Autonomous Learning Laboratory (Barto's lab at the University of Massachusetts Amherst)
- RL-Glue
- Software Tools for Reinforcement Learning (Matlab and Python)
- The UofA Reinforcement Learning Library (texts)
- The Reinforcement Learning Toolbox from the (Graz University of Technology)
- Hybrid reinforcement learning
- Piqle: a Generic Java Platform for Reinforcement Learning
- A Short Introduction To Some Reinforcement Learning Algorithms
- Reinforcement Learning applied to Tic-Tac-Toe Game
- Scholarpedia Reinforcement Learning
- Scholarpedia Temporal Difference Learning
- Annual Reinforcement Learning Competition
- Stanford Reinforcement Learning Course