

SARSA
Encyclopedia
SARSA is an algorithm
for learning a Markov decision process
policy, used in the reinforcement learning
area of machine learning
. It was introduced in the technical note "Online Q-Learning using Connectionist Systems" by Rummery & Niranjan (1994) where the alternative name SARSA was only mentioned as a footnote.
This name simply reflects the fact that the main function for updating the Q-value depends on the current state of the agent "S1", the action the agent chooses "A1", the reward "R" the agent gets for choosing this action, the state "S2" that the agent will now be in after taking that action, and finally the next action "A2" the agent will choose in its new state. Taking every letter in the quintuple (st , at , rt+1 , st+1 , at+1) yields the word SARSA.
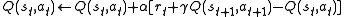
A SARSA agent will interact with the environment and update the policy based on actions taken, known as an on-policy learning algorithm. As expressed above, the Q value for a state-action is updated by an error, adjusted by the learning rate alpha. Q values represent the possible reward received in the next time step for taking action a in state s, plus the discounted future reward received from the next state-action observation. Watkin's Q-learning
was created as an alternative to the existing temporal difference technique
and which updates the policy based on the maximum reward of available actions. The difference may be explained as SARSA learns the Q values associated with taking the policy it follows itself, while Watkin's Q-learning learns the Q values associated with taking the exploitation policy while following an exploration/exploitation policy. For further information on the exploration/exploitation trade off, see reinforcement learning
.
Some optimizations of Watkin's Q-learning may also be applied to SARSA, for example in the paper "Fast Online Q(λ)" (Wiering and Schmidhuber, 1998) the small differences needed for SARSA(λ) implementations are described as they arise.
Algorithm
In mathematics and computer science, an algorithm is an effective method expressed as a finite list of well-defined instructions for calculating a function. Algorithms are used for calculation, data processing, and automated reasoning...
for learning a Markov decision process
Markov decision process
Markov decision processes , named after Andrey Markov, provide a mathematical framework for modeling decision-making in situations where outcomes are partly random and partly under the control of a decision maker. MDPs are useful for studying a wide range of optimization problems solved via...
policy, used in the reinforcement learning
Reinforcement learning
Inspired by behaviorist psychology, reinforcement learning is an area of machine learning in computer science, concerned with how an agent ought to take actions in an environment so as to maximize some notion of cumulative reward...
area of machine learning
Machine learning
Machine learning, a branch of artificial intelligence, is a scientific discipline concerned with the design and development of algorithms that allow computers to evolve behaviors based on empirical data, such as from sensor data or databases...
. It was introduced in the technical note "Online Q-Learning using Connectionist Systems" by Rummery & Niranjan (1994) where the alternative name SARSA was only mentioned as a footnote.
This name simply reflects the fact that the main function for updating the Q-value depends on the current state of the agent "S1", the action the agent chooses "A1", the reward "R" the agent gets for choosing this action, the state "S2" that the agent will now be in after taking that action, and finally the next action "A2" the agent will choose in its new state. Taking every letter in the quintuple (st , at , rt+1 , st+1 , at+1) yields the word SARSA.
Algorithm
A SARSA agent will interact with the environment and update the policy based on actions taken, known as an on-policy learning algorithm. As expressed above, the Q value for a state-action is updated by an error, adjusted by the learning rate alpha. Q values represent the possible reward received in the next time step for taking action a in state s, plus the discounted future reward received from the next state-action observation. Watkin's Q-learning
Q-learning
Q-learning is a reinforcement learning technique that works by learning an action-value function that gives the expected utility of taking a given action in a given state and following a fixed policy thereafter. One of the strengths of Q-learning is that it is able to compare the expected utility...
was created as an alternative to the existing temporal difference technique
Temporal difference learning
Temporal difference learning is a prediction method. It has been mostly used for solving the reinforcement learning problem. "TD learning is a combination of Monte Carlo ideas and dynamic programming ideas." TD resembles a Monte Carlo method because it learns by sampling the environment according...
and which updates the policy based on the maximum reward of available actions. The difference may be explained as SARSA learns the Q values associated with taking the policy it follows itself, while Watkin's Q-learning learns the Q values associated with taking the exploitation policy while following an exploration/exploitation policy. For further information on the exploration/exploitation trade off, see reinforcement learning
Reinforcement learning
Inspired by behaviorist psychology, reinforcement learning is an area of machine learning in computer science, concerned with how an agent ought to take actions in an environment so as to maximize some notion of cumulative reward...
.
Some optimizations of Watkin's Q-learning may also be applied to SARSA, for example in the paper "Fast Online Q(λ)" (Wiering and Schmidhuber, 1998) the small differences needed for SARSA(λ) implementations are described as they arise.