
Rete algorithm
Encyclopedia
The Rete algorithm is an efficient pattern matching
algorithm
for implementing production rule system
s. The Rete algorithm was designed by Dr Charles L. Forgy
of Carnegie Mellon University
, first published in a working paper in 1974, and later elaborated in his 1979 Ph.D. thesis and a 1982 paper (see References). Rete has become the basis for many popular expert system shells, including CLIPS, Jess
, Drools
, BizTalk, Rules Engine
and Soar
. The word 'Rete' is Latin for 'net' or 'comb'. The same word is used in modern Italian to mean network. Charles Forgy has reportedly stated that he adopted the term 'Rete' because of its use in anatomy to describe a network of blood vessels and nerve fibers.
A naïve implementation of an expert system might check each rule
against the known fact
s in the knowledge base
, firing that rule if necessary, then moving on to the next rule (and looping back to the first rule when finished). For even moderate sized rules and facts knowledge-bases, this naïve approach performs far too slowly. The Rete algorithm provides the basis for a more efficient implementation. A Rete-based expert system builds a network of node
s, where each node (except the root) corresponds to a pattern occurring in the left-hand-side (the condition part) of a rule. The path from the root node to a leaf node defines a complete rule left-hand-side. Each node has a memory of facts which satisfy that pattern. This structure is essentially a generalized trie
. As new facts are asserted or modified, they propagate along the network, causing nodes to be annotated when that fact matches that pattern. When a fact or combination of facts causes all of the patterns for a given rule to be satisfied, a leaf node is reached and the corresponding rule is triggered.
The Rete algorithm is designed to sacrifice memory
for increased speed. In most cases, the speed increase over naïve implementations is several orders of magnitude (because Rete performance is theoretically independent of the number of rules in the system). In very large expert systems, however, the original Rete algorithm tends to run into memory consumption problems. Other algorithms, both novel and Rete-based, have since been designed which require less memory.
s ("facts") against productions ("rules
") in a pattern-matching production system
(a category of rule engine). A production consists of one or more conditions and a set of actions which may be undertaken for each complete set of facts that match the conditions. Conditions test fact attributes
, including fact type specifiers/identifiers. The Rete algorithm exhibits the following major characteristics:
The Rete algorithm is widely used to implement matching functionality within pattern-matching engines that exploit a match-resolve-act cycle to support forward chaining
and inferencing
.
Retes are directed acyclic graph
s that represent higher-level rule sets. They are generally represented at run-time using a network of in-memory objects. These networks match rule conditions (patterns) to facts (relational data tuples). Rete networks act as a type of relational query processor, performing projections, selections and joins conditionally on arbitrary numbers of data tuples.
Productions (rules) are typically captured and defined by analysts
and developers
using some high-level rules language. They are collected into rule sets which are then translated, often at run time, into an executable Rete.
When facts are "asserted" to working memory, the engine creates working memory elements (WMEs) for each fact. Facts are n-tuples, and may therefore contain an arbitrary number of data items. Each WME may hold an entire n-tuple, or, alternatively, each fact may be represented by a set of WMEs where each WME contains a fixed-length tuple. In this case, tuples are typically triplets (3-tuples).
Each WME enters the Rete network at a single root node. The root node passes each WME on to its child nodes, and each WME may then be propagated through the network, possibly being stored in intermediate memories, until it arrives at a terminal node.
type typically traverse a given branch of nodes in the discrimination network.
Within the discrimination network, each branch of alpha nodes (also called 1-input nodes) terminates at a memory, called an alpha memory. These memories store collections of WMEs that match each condition in each node in a given node branch. WMEs that fail to match at least one condition in a branch are not materialised within the corresponding alpha memory. Alpha node branches may fork in order to minimise condition redundancy.
A possible variation is to introduce additional memories for each intermediate node in the discrimination network. This increases the overhead of the Rete, but may have advantages in situations where rules are dynamically added to or removed from the Rete, making it easier to vary the topography of the discrimination network dynamically.
An alternative implementation is described by Doorenbos. In this case, the discrimination network is replaced by a set of memories and an index
. The index may be implemented using a hash table
. Each memory holds WMEs that match a single conditional pattern, and the index is used to reference memories by their pattern. This approach is only practical when WMEs represent fixed-length tuples, and the length of each tuple is short (e.g., 3-tuples). In addition, the approach only applies to conditional patterns that perform equality tests against constant
values. When a WME enters the Rete, the index is used to locate a set of memories whose conditional pattern matches the WME attributes, and the WME is then added directly to each of these memories. In itself, this implementation contains no 1-input nodes. However, in order to implement non-equality tests, the Rete may contain additional 1-input node networks through which WMEs are passed before being placed in a memory. Alternatively, non-equality tests may be performed in the beta network described below.
Beta nodes process tokens. A token is a unit of storage within a memory and also a unit of exchange between memories and nodes. In many implementations, tokens are introduced within alpha memories where they are used to hold single WMEs. These tokens are then passed to the beta network.
Each beta node performs its work and, as a result, may create new tokens to hold a list of WMEs representing a partial match. These extended tokens are then stored in beta memories, and passed to subsequent beta nodes. In this case, the beta nodes typically pass lists of WMEs through the beta network by copying existing WME lists from each received token into new tokens and then adding a further WMEs to the lists as a result of performing a join or some other action. The new tokens are then stored in the output memory.
A common variation is to build linked list
s of tokens where each token holds a single WME. In this case, lists of WMEs for a partial match are represented by the linked list of tokens. This approach may be better because it eliminates the need to copy lists of WMEs from one token to another. Instead, a beta node needs only to create a new token to hold a WME it wishes to join to the partial match list, and then link the new token to a parent token stored in the input beta memory. The new token now forms the head of the token list, and is stored in the output beta memory.
In descriptions of Rete, it is common to refer to token passing within the beta network. In this article, however, we will describe data propagation in terms of WME lists, rather than tokens, in recognition of different implementation options and the underlying purpose and use of tokens. As any one WME list passes through the beta network, new WMEs may be added to it, and the list may be stored in beta memories. A WME list in a beta memory represents a partial match for the conditions in a given production.
WME lists that reach the end of a branch of beta nodes represent a complete match for a single production, and are passed to terminal nodes. These nodes are sometimes called p-nodes, where "p" stands for production. Each terminal node represents a single production, and each WME list that arrives at a terminal node represents a complete set of matching WMEs for the conditions in that production. For each WME list it receives, a production node will "activate" a new production instance on the "agenda". Agendas are typically implemented as prioritised queues
.
Beta nodes typically perform joins between WME lists stored in beta memories and individual WMEs stored in alpha memories. Each beta node is associated with two input memories. An alpha memory holds WM and performs "right" activations on the beta node each time it stores a new WME. A beta memory holds WME lists and performs "left" activations on the beta node each time it stores a new WME list. When a join node is right-activated, it compares one or more attributes of the newly stored WME from its input alpha memory against given attributes of specific WMEs in each WME list contained in the input beta memory. When a join node is left-activated it traverses a single newly stored WME list in the beta memory, retrieving specific attribute values of given WMEs. It compares these values with attribute values of each WME in the alpha memory.
Each beta node outputs WME lists which are either stored in a beta memory or sent directly to a terminal node. WME lists are stored in beta memories whenever the engine will perform additional left activations on subsequent beta nodes.
Logically, a beta node at the head of a branch of beta nodes is a special case because it takes no input from any beta memory higher in the network. Different engines handle this issue in different ways. Some engines use specialised adapter nodes to connect alpha memories to the left input of beta nodes. Other engines allow beta nodes to take input directly from two alpha memories, treating one as a "left" input and the other as a "right" input. In both cases, "head" beta nodes take their input from two alpha memories.
In order to eliminate node redundancies, any one alpha or beta memory may be used to perform activations on multiple beta nodes. As well as join nodes, the beta network may contain additional node types, some of which are described below. If a Rete contains no beta network, alpha nodes feed tokens, each containing a single WME, directly to p-nodes. In this case, there may be no need to store WMEs in alpha memories.
Conflict resolution is not defined as part of the Rete algorithm, but is used alongside the algorithm. Some specialised production systems do not perform conflict resolution.
By default, the engine will continue to fire each production instance in order until all production instances have been fired. Each production instance will fire only once, at most, during any one match-resolve-act cycle. This characteristic is termed refraction. However, the sequence of production instance firings may be interrupted at any stage by performing changes to the working memory. Rule actions can contain instructions to assert or retract WMEs from the working memory of the engine. Each time any single production instance performs one or more such changes, the engine immediately enters a new match-resolve-act cycle. This includes "updates" to WMEs currently in the working memory. Updates are represented by retracting and then re-asserting the WME. The engine undertakes matching of the changed data which, in turn, may result in changes to the list of production instances on the agenda. Hence, after the actions for any one specific production instance have been executed, previously activated instances may have been de-activated and removed from the agenda, and new instances may have been activated.
As part of the new match-resolve-act cycle, the engine performs conflict resolution on the agenda and then executes the current first instance. The engine continues to fire production instances, and to enter new match-resolve-act cycles, until no further production instances exist on the agenda. At this point the rule engine is deemed to have completed its work, and halts.
Some engines support advanced refraction strategies in which certain production instances executed in a previous cycle are not re-executed in the new cycle, even though they may still exist on the agenda.
It is possible for the engine to enter into never-ending loops in which the agenda never reaches the empty state. For this reason, most engines support explicit "halt" verbs that can be invoked from production action lists. They may also provide automatic loop detection in which never-ending loops are automatically halted after a given number of iterations. Some engines support a model in which, instead of halting when the agenda is empty, the engine enters a wait state until new facts are asserted externally.
As for conflict resolution, the firing of activated production instances is not a feature of the Rete algorithm. However, it is a central feature of engines that use Rete networks. Some of the optimisations offered by Rete networks are only useful in scenarios where the engine performs multiple match-resolve-act cycles.
s. Existential quantification
involves testing for the existence of at least one set of matching WMEs in working memory. Universal quantification
involves testing that an entire set of WMEs in working memory meets a given condition. A variation of universal quantification might test that a given number of WMEs, drawn from a set of WMEs, meets given criteria. This might be in terms of testing for either an exact number or a minimum number of matches.
Quantification is not universally implemented in Rete engines, and, where it is supported, several variations exist. A variant of existential quantification referred to as negation is widely, though not universally, supported, and is described in seminal documents. Existentially negated conditions and conjunctions involve the use of specialised beta nodes that test for non-existence of matching WMEs or sets of WMEs. These nodes propagate WME lists only when no match is found. The exact implementation of negation varies. In one approach, the node maintains a simple count on each WME list it receives from its left input. The count specifies the number of matches found with WMEs received from the right input. The node only propagates WME lists whose count is zero. In another approach, the node maintains an additional memory on each WME list received from the left input. These memories are a form of beta memory, and store WME lists for each match with WMEs received on the right input. If a WME list does not have any WME lists in its memory, it is propagated down the network. In this approach, negation nodes generally activate further beta nodes directly, rather than storing their output in an additional beta memory. Negation nodes provide a form of 'negation as failure'.
When changes are made to working memory, a WME list that previously matched no WMEs may now match newly asserted WMEs. In this case, the propagated WME list and all its extended copies need to be retracted from beta memories further down the network. The second approach described above is often used to support efficient mechanisms for removal of WME lists. When WME lists are removed, any corresponding production instances are de-activated and removed from the agenda.
Existential quantification can be performed by combining two negation beta nodes. This represents the semantics of double negation
(e.g., "If NOT NOT any matching WMEs, then..."). This is a common approach taken by several production systems.
. In many production systems, this is handled by interpreting a single production containing multiple ORed patterns as the equivalent of multiple productions. The resulting Rete network contains sets of terminal nodes which, together, represent single productions. This approach disallows any form of short-circuiting of the ORed conditions. It can also, in some cases, lead to duplicate production instances being activated on the agenda where the same set of WMEs match multiple internal productions. Some engines provide agenda de-duplication in order to handle this issue.
For a more detailed and complete description of the Rete algorithm, see chapter 2 of Production Matching for Large Learning Systems by Robert Doorenbos (see link below).
dependencies automatically. Some engines, however, support additional functionality in which truth dependencies can be automatically maintained. In this case, the retraction of one WME may lead to the automatic retraction of additional WMEs in order to maintain logical truth assertions.
The Rete algorithm does not define any approach to justification. Justification refers to mechanisms commonly required in expert and decision systems in which, at its simplest, the system reports each of the inner decisions used to reach some final conclusion. For example, an expert system might justify a conclusion that an animal is an elephant by reporting that it is large, grey, has big ears, a trunk and tusks. Some engines provide built-in justification systems in conjunction with their implementation of the Rete algorithm.
This article does not provide an exhaustive description of every possible variation or extension of the Rete algorithm. Other considerations and innovations exist. For example, engines may provide specialised support within the Rete network in order to apply pattern-matching rule processing to specific data types and sources such as programmatic objects
, XML
data or relational data tables
. Another example concerns additional time-stamping facilities provided by many engines for each WME entering a Rete network, and the use of these time-stamps in conjunction with conflict resolution strategies. Engines exhibit significant variation in the way they allow programmatic access to the engine and its working memory, and may extend the basic Rete model to support forms of parallel and distributed processing.
The Rete algorithm is orientated to scenarios where forward chaining and "inferencing" is used to calculate new facts from existing facts, or to filter and discard facts in order to arrive at some conclusion. It is also exploited as a reasonably efficient mechanism for performing highly combinatorial evaluations of facts where large numbers of joins must be performed between fact tuples. Other approaches to performing rule evaluation, such as the use of decision trees, or the implementation of sequential engines, may be more appropriate for simple scenarios, and should be considered as possible alternatives.
Rete II can be characterized by two areas of improvement; specific optimizations relating to the general performance of the Rete network (including the use of hashed memories in order to increase performance with larger sets of data), and the inclusion of a backward chaining
algorithm tailored to run on top of the Rete network. Backward chaining alone can account for the most extreme changes in benchmarks relating to Rete vs. Rete II.
Jess (at least versions 5.0 and later) also adds a backward chaining algorithm on top of the Rete network, but it cannot be said to fully implement Rete II, in part due to the fact that no full specification is publicly available.
Pattern matching
In computer science, pattern matching is the act of checking some sequence of tokens for the presence of the constituents of some pattern. In contrast to pattern recognition, the match usually has to be exact. The patterns generally have the form of either sequences or tree structures...
algorithm
Algorithm
In mathematics and computer science, an algorithm is an effective method expressed as a finite list of well-defined instructions for calculating a function. Algorithms are used for calculation, data processing, and automated reasoning...
for implementing production rule system
Production system
A production system is a computer program typically used to provide some form of artificial intelligence, which consists primarily of a set of rules about behavior. These rules, termed productions, are a basic representation found useful in automated planning, expert systems and action selection...
s. The Rete algorithm was designed by Dr Charles L. Forgy
Charles Forgy
Dr Charles L. Forgy is a computer scientist, known for developing the Rete algorithm used in his OPS5 and other production system languages used to build expert systems.- Early Life :Dr...
of Carnegie Mellon University
Carnegie Mellon University
Carnegie Mellon University is a private research university in Pittsburgh, Pennsylvania, United States....
, first published in a working paper in 1974, and later elaborated in his 1979 Ph.D. thesis and a 1982 paper (see References). Rete has become the basis for many popular expert system shells, including CLIPS, Jess
Jess programming language
Jess is a rule engine for the Java platform - it is a superset of CLIPS programming language, developed by Ernest Friedman-Hill of Sandia National Labs. It was first written in late 1995....
, Drools
Drools
Drools is a business rule management system with a forward chaining inference based rules engine, more correctly known as a production rule system, using an enhanced implementation of the Rete algorithm....
, BizTalk, Rules Engine
Business rules engine
A business rules engine is a software system that executes one or more business rules in a runtime production environment. The rules might come from legal regulation , company policy , or other sources...
and Soar
Soar (cognitive architecture)
Soar is a symbolic cognitive architecture, created by John Laird, Allen Newell, and Paul Rosenbloom at Carnegie Mellon University, now maintained by John Laird's research group at the University of Michigan. It is both a view of what cognition is and an implementation of that view through a...
. The word 'Rete' is Latin for 'net' or 'comb'. The same word is used in modern Italian to mean network. Charles Forgy has reportedly stated that he adopted the term 'Rete' because of its use in anatomy to describe a network of blood vessels and nerve fibers.
A naïve implementation of an expert system might check each rule
Rule of inference
In logic, a rule of inference, inference rule, or transformation rule is the act of drawing a conclusion based on the form of premises interpreted as a function which takes premises, analyses their syntax, and returns a conclusion...
against the known fact
Fact
A fact is something that has really occurred or is actually the case. The usual test for a statement of fact is verifiability, that is whether it can be shown to correspond to experience. Standard reference works are often used to check facts...
s in the knowledge base
Knowledge base
A knowledge base is a special kind of database for knowledge management. A Knowledge Base provides a means for information to be collected, organised, shared, searched and utilised.-Types:...
, firing that rule if necessary, then moving on to the next rule (and looping back to the first rule when finished). For even moderate sized rules and facts knowledge-bases, this naïve approach performs far too slowly. The Rete algorithm provides the basis for a more efficient implementation. A Rete-based expert system builds a network of node
Vertex (graph theory)
In graph theory, a vertex or node is the fundamental unit out of which graphs are formed: an undirected graph consists of a set of vertices and a set of edges , while a directed graph consists of a set of vertices and a set of arcs...
s, where each node (except the root) corresponds to a pattern occurring in the left-hand-side (the condition part) of a rule. The path from the root node to a leaf node defines a complete rule left-hand-side. Each node has a memory of facts which satisfy that pattern. This structure is essentially a generalized trie
Trie
In computer science, a trie, or prefix tree, is an ordered tree data structure that is used to store an associative array where the keys are usually strings. Unlike a binary search tree, no node in the tree stores the key associated with that node; instead, its position in the tree defines the...
. As new facts are asserted or modified, they propagate along the network, causing nodes to be annotated when that fact matches that pattern. When a fact or combination of facts causes all of the patterns for a given rule to be satisfied, a leaf node is reached and the corresponding rule is triggered.
The Rete algorithm is designed to sacrifice memory
Computer memory
In computing, memory refers to the physical devices used to store programs or data on a temporary or permanent basis for use in a computer or other digital electronic device. The term primary memory is used for the information in physical systems which are fast In computing, memory refers to the...
for increased speed. In most cases, the speed increase over naïve implementations is several orders of magnitude (because Rete performance is theoretically independent of the number of rules in the system). In very large expert systems, however, the original Rete algorithm tends to run into memory consumption problems. Other algorithms, both novel and Rete-based, have since been designed which require less memory.
Description
The Rete algorithm provides a generalized logical description of an implementation of functionality responsible for matching data tupleTuple
In mathematics and computer science, a tuple is an ordered list of elements. In set theory, an n-tuple is a sequence of n elements, where n is a positive integer. There is also one 0-tuple, an empty sequence. An n-tuple is defined inductively using the construction of an ordered pair...
s ("facts") against productions ("rules
Rule of inference
In logic, a rule of inference, inference rule, or transformation rule is the act of drawing a conclusion based on the form of premises interpreted as a function which takes premises, analyses their syntax, and returns a conclusion...
") in a pattern-matching production system
Production system
A production system is a computer program typically used to provide some form of artificial intelligence, which consists primarily of a set of rules about behavior. These rules, termed productions, are a basic representation found useful in automated planning, expert systems and action selection...
(a category of rule engine). A production consists of one or more conditions and a set of actions which may be undertaken for each complete set of facts that match the conditions. Conditions test fact attributes
Attribute (computing)
In computing, an attribute is a specification that defines a property of an object, element, or file. It may also refer to or set the specific value for a given instance of such....
, including fact type specifiers/identifiers. The Rete algorithm exhibits the following major characteristics:
- It reduces or eliminates certain types of redundancy through the use of node sharing.
- It stores partial matches when performing joinsLogical conjunctionIn logic and mathematics, a two-place logical operator and, also known as logical conjunction, results in true if both of its operands are true, otherwise the value of false....
between different fact types. This, in turn, allows production systems to avoid complete re-evaluation of all facts each time changes are made to the production system's working memory. Instead, the production system needs only to evaluate the changes (deltas) to working memory. - It allows for efficient removal of memory elements when facts are retracted from working memory.
The Rete algorithm is widely used to implement matching functionality within pattern-matching engines that exploit a match-resolve-act cycle to support forward chaining
Forward chaining
Forward chaining is one of the two main methods of reasoning when using inference rules and can be described logically as repeated application of modus ponens. Forward chaining is a popular implementation strategy for expert systems, business and production rule systems...
and inferencing
Inference
Inference is the act or process of deriving logical conclusions from premises known or assumed to be true. The conclusion drawn is also called an idiomatic. The laws of valid inference are studied in the field of logic.Human inference Inference is the act or process of deriving logical conclusions...
.
Retes are directed acyclic graph
Directed acyclic graph
In mathematics and computer science, a directed acyclic graph , is a directed graph with no directed cycles. That is, it is formed by a collection of vertices and directed edges, each edge connecting one vertex to another, such that there is no way to start at some vertex v and follow a sequence of...
s that represent higher-level rule sets. They are generally represented at run-time using a network of in-memory objects. These networks match rule conditions (patterns) to facts (relational data tuples). Rete networks act as a type of relational query processor, performing projections, selections and joins conditionally on arbitrary numbers of data tuples.
Productions (rules) are typically captured and defined by analysts
Business analyst
A Business Analyst analyzes the organization and design of businesses, government departments, and non-profit organizations; BAs also assess business models and their integration with technology.-Levels:...
and developers
Software developer
A software developer is a person concerned with facets of the software development process. Their work includes researching, designing, developing, and testing software. A software developer may take part in design, computer programming, or software project management...
using some high-level rules language. They are collected into rule sets which are then translated, often at run time, into an executable Rete.
When facts are "asserted" to working memory, the engine creates working memory elements (WMEs) for each fact. Facts are n-tuples, and may therefore contain an arbitrary number of data items. Each WME may hold an entire n-tuple, or, alternatively, each fact may be represented by a set of WMEs where each WME contains a fixed-length tuple. In this case, tuples are typically triplets (3-tuples).
Each WME enters the Rete network at a single root node. The root node passes each WME on to its child nodes, and each WME may then be propagated through the network, possibly being stored in intermediate memories, until it arrives at a terminal node.
Alpha network
The "left" (alpha) side of the node graph forms a discrimination network responsible for selecting individual WMEs based on simple conditional tests which match WME attributes against constant values. Nodes in the discrimination network may also perform tests that compare two or more attributes of the same WME. If a WME is successfully matched against the conditions represented by one node, it is passed to the next node. In most engines, the immediate child nodes of the root node are used to test the entity identifier or fact type of each WME. Hence, all the WMEs which represent the same entityEntity
An entity is something that has a distinct, separate existence, although it need not be a material existence. In particular, abstractions and legal fictions are usually regarded as entities. In general, there is also no presumption that an entity is animate.An entity could be viewed as a set...
type typically traverse a given branch of nodes in the discrimination network.
Within the discrimination network, each branch of alpha nodes (also called 1-input nodes) terminates at a memory, called an alpha memory. These memories store collections of WMEs that match each condition in each node in a given node branch. WMEs that fail to match at least one condition in a branch are not materialised within the corresponding alpha memory. Alpha node branches may fork in order to minimise condition redundancy.
A possible variation is to introduce additional memories for each intermediate node in the discrimination network. This increases the overhead of the Rete, but may have advantages in situations where rules are dynamically added to or removed from the Rete, making it easier to vary the topography of the discrimination network dynamically.
An alternative implementation is described by Doorenbos. In this case, the discrimination network is replaced by a set of memories and an index
Index (information technology)
In computer science, an index can be:# an integer that identifies an array element# a data structure that enables sublinear-time lookup -Array element identifier:...
. The index may be implemented using a hash table
Hash table
In computer science, a hash table or hash map is a data structure that uses a hash function to map identifying values, known as keys , to their associated values . Thus, a hash table implements an associative array...
. Each memory holds WMEs that match a single conditional pattern, and the index is used to reference memories by their pattern. This approach is only practical when WMEs represent fixed-length tuples, and the length of each tuple is short (e.g., 3-tuples). In addition, the approach only applies to conditional patterns that perform equality tests against constant
Variable (mathematics)
In mathematics, a variable is a value that may change within the scope of a given problem or set of operations. In contrast, a constant is a value that remains unchanged, though often unknown or undetermined. The concepts of constants and variables are fundamental to many areas of mathematics and...
values. When a WME enters the Rete, the index is used to locate a set of memories whose conditional pattern matches the WME attributes, and the WME is then added directly to each of these memories. In itself, this implementation contains no 1-input nodes. However, in order to implement non-equality tests, the Rete may contain additional 1-input node networks through which WMEs are passed before being placed in a memory. Alternatively, non-equality tests may be performed in the beta network described below.
Beta network
The "right" (beta) side of the graph chiefly performs joins between different WMEs. It is optional, and is only included if required. It consists of 2-input nodes where each node has a "left" and a "right" input. Each beta node sends its output to a beta memory.Beta nodes process tokens. A token is a unit of storage within a memory and also a unit of exchange between memories and nodes. In many implementations, tokens are introduced within alpha memories where they are used to hold single WMEs. These tokens are then passed to the beta network.
Each beta node performs its work and, as a result, may create new tokens to hold a list of WMEs representing a partial match. These extended tokens are then stored in beta memories, and passed to subsequent beta nodes. In this case, the beta nodes typically pass lists of WMEs through the beta network by copying existing WME lists from each received token into new tokens and then adding a further WMEs to the lists as a result of performing a join or some other action. The new tokens are then stored in the output memory.
A common variation is to build linked list
Linked list
In computer science, a linked list is a data structure consisting of a group of nodes which together represent a sequence. Under the simplest form, each node is composed of a datum and a reference to the next node in the sequence; more complex variants add additional links...
s of tokens where each token holds a single WME. In this case, lists of WMEs for a partial match are represented by the linked list of tokens. This approach may be better because it eliminates the need to copy lists of WMEs from one token to another. Instead, a beta node needs only to create a new token to hold a WME it wishes to join to the partial match list, and then link the new token to a parent token stored in the input beta memory. The new token now forms the head of the token list, and is stored in the output beta memory.
In descriptions of Rete, it is common to refer to token passing within the beta network. In this article, however, we will describe data propagation in terms of WME lists, rather than tokens, in recognition of different implementation options and the underlying purpose and use of tokens. As any one WME list passes through the beta network, new WMEs may be added to it, and the list may be stored in beta memories. A WME list in a beta memory represents a partial match for the conditions in a given production.
WME lists that reach the end of a branch of beta nodes represent a complete match for a single production, and are passed to terminal nodes. These nodes are sometimes called p-nodes, where "p" stands for production. Each terminal node represents a single production, and each WME list that arrives at a terminal node represents a complete set of matching WMEs for the conditions in that production. For each WME list it receives, a production node will "activate" a new production instance on the "agenda". Agendas are typically implemented as prioritised queues
Priority queue
A priority queue is an abstract data type in computer programming.It is exactly like a regular queue or stack data structure, but additionally, each element is associated with a "priority"....
.
Beta nodes typically perform joins between WME lists stored in beta memories and individual WMEs stored in alpha memories. Each beta node is associated with two input memories. An alpha memory holds WM and performs "right" activations on the beta node each time it stores a new WME. A beta memory holds WME lists and performs "left" activations on the beta node each time it stores a new WME list. When a join node is right-activated, it compares one or more attributes of the newly stored WME from its input alpha memory against given attributes of specific WMEs in each WME list contained in the input beta memory. When a join node is left-activated it traverses a single newly stored WME list in the beta memory, retrieving specific attribute values of given WMEs. It compares these values with attribute values of each WME in the alpha memory.
Each beta node outputs WME lists which are either stored in a beta memory or sent directly to a terminal node. WME lists are stored in beta memories whenever the engine will perform additional left activations on subsequent beta nodes.
Logically, a beta node at the head of a branch of beta nodes is a special case because it takes no input from any beta memory higher in the network. Different engines handle this issue in different ways. Some engines use specialised adapter nodes to connect alpha memories to the left input of beta nodes. Other engines allow beta nodes to take input directly from two alpha memories, treating one as a "left" input and the other as a "right" input. In both cases, "head" beta nodes take their input from two alpha memories.
In order to eliminate node redundancies, any one alpha or beta memory may be used to perform activations on multiple beta nodes. As well as join nodes, the beta network may contain additional node types, some of which are described below. If a Rete contains no beta network, alpha nodes feed tokens, each containing a single WME, directly to p-nodes. In this case, there may be no need to store WMEs in alpha memories.
Conflict resolution
During any one match-resolve-act cycle, the engine will find all possible matches for the facts currently asserted to working memory. Once all the current matches have been found, and corresponding production instances have been activated on the agenda, the engine determines an order in which the production instances may be "fired". This is termed conflict resolution, and the list of activated production instances is termed the conflict set. The order may be based on rule priority (salience), rule order, the time at which facts contained in each instance were asserted to the working memory, the complexity of each production, or some other criteria. Many engines allow rule developers to select between different conflict resolution strategies or to chain a selection of multiple strategies.Conflict resolution is not defined as part of the Rete algorithm, but is used alongside the algorithm. Some specialised production systems do not perform conflict resolution.
Production execution
Having performed conflict resolution, the engine now "fires" the first production instance, executing a list of actions associated with the production. The actions act on the data represented by the production instance's WME list.By default, the engine will continue to fire each production instance in order until all production instances have been fired. Each production instance will fire only once, at most, during any one match-resolve-act cycle. This characteristic is termed refraction. However, the sequence of production instance firings may be interrupted at any stage by performing changes to the working memory. Rule actions can contain instructions to assert or retract WMEs from the working memory of the engine. Each time any single production instance performs one or more such changes, the engine immediately enters a new match-resolve-act cycle. This includes "updates" to WMEs currently in the working memory. Updates are represented by retracting and then re-asserting the WME. The engine undertakes matching of the changed data which, in turn, may result in changes to the list of production instances on the agenda. Hence, after the actions for any one specific production instance have been executed, previously activated instances may have been de-activated and removed from the agenda, and new instances may have been activated.
As part of the new match-resolve-act cycle, the engine performs conflict resolution on the agenda and then executes the current first instance. The engine continues to fire production instances, and to enter new match-resolve-act cycles, until no further production instances exist on the agenda. At this point the rule engine is deemed to have completed its work, and halts.
Some engines support advanced refraction strategies in which certain production instances executed in a previous cycle are not re-executed in the new cycle, even though they may still exist on the agenda.
It is possible for the engine to enter into never-ending loops in which the agenda never reaches the empty state. For this reason, most engines support explicit "halt" verbs that can be invoked from production action lists. They may also provide automatic loop detection in which never-ending loops are automatically halted after a given number of iterations. Some engines support a model in which, instead of halting when the agenda is empty, the engine enters a wait state until new facts are asserted externally.
As for conflict resolution, the firing of activated production instances is not a feature of the Rete algorithm. However, it is a central feature of engines that use Rete networks. Some of the optimisations offered by Rete networks are only useful in scenarios where the engine performs multiple match-resolve-act cycles.
Existential and universal quantifications
Conditional tests are most commonly used to perform selections and joins on individual tuples. However, by implementing additional beta node types, it is possible for Rete networks to perform quantificationQuantification
Quantification has several distinct senses. In mathematics and empirical science, it is the act of counting and measuring that maps human sense observations and experiences into members of some set of numbers. Quantification in this sense is fundamental to the scientific method.In logic,...
s. Existential quantification
Existential quantification
In predicate logic, an existential quantification is the predication of a property or relation to at least one member of the domain. It is denoted by the logical operator symbol ∃ , which is called the existential quantifier...
involves testing for the existence of at least one set of matching WMEs in working memory. Universal quantification
Universal quantification
In predicate logic, universal quantification formalizes the notion that something is true for everything, or every relevant thing....
involves testing that an entire set of WMEs in working memory meets a given condition. A variation of universal quantification might test that a given number of WMEs, drawn from a set of WMEs, meets given criteria. This might be in terms of testing for either an exact number or a minimum number of matches.
Quantification is not universally implemented in Rete engines, and, where it is supported, several variations exist. A variant of existential quantification referred to as negation is widely, though not universally, supported, and is described in seminal documents. Existentially negated conditions and conjunctions involve the use of specialised beta nodes that test for non-existence of matching WMEs or sets of WMEs. These nodes propagate WME lists only when no match is found. The exact implementation of negation varies. In one approach, the node maintains a simple count on each WME list it receives from its left input. The count specifies the number of matches found with WMEs received from the right input. The node only propagates WME lists whose count is zero. In another approach, the node maintains an additional memory on each WME list received from the left input. These memories are a form of beta memory, and store WME lists for each match with WMEs received on the right input. If a WME list does not have any WME lists in its memory, it is propagated down the network. In this approach, negation nodes generally activate further beta nodes directly, rather than storing their output in an additional beta memory. Negation nodes provide a form of 'negation as failure'.
When changes are made to working memory, a WME list that previously matched no WMEs may now match newly asserted WMEs. In this case, the propagated WME list and all its extended copies need to be retracted from beta memories further down the network. The second approach described above is often used to support efficient mechanisms for removal of WME lists. When WME lists are removed, any corresponding production instances are de-activated and removed from the agenda.
Existential quantification can be performed by combining two negation beta nodes. This represents the semantics of double negation
Double negation
In the theory of logic, double negation is expressed by saying that a proposition A is identical to not , or by the formula A = ~~A. Like the Law of Excluded Middle, this principle when extended to an infinite collection of individuals is disallowed by Intuitionistic logic...
(e.g., "If NOT NOT any matching WMEs, then..."). This is a common approach taken by several production systems.
Memory indexing
The Rete algorithm does not mandate any specific approach to indexing the working memory. However, most modern production systems provide indexing mechanisms. In some cases, only beta memories are indexed, whilst in others, indexing is used for both alpha and beta memories. A good indexing strategy is a major factor in deciding the overall performance of a production system, especially when executing rule sets that result in highly combinatorial pattern matching (i.e., intensive use of beta join nodes), or, for some engines, when executing rules sets that perform a significant number of WME retractions during multiple match-resolve-act cycles. Memories are often implemented using combinations of hash tables, and hash values are used to perform conditional joins on subsets of WME lists and WMEs, rather than on the entire contents of memories. This, in turn, often significantly reduces the number of evaluations performed by the Rete network.Removal of WMEs and WME lists
When a WME is retracted from working memory, it must be removed from every alpha memory in which it is stored. In addition, WME lists that contain the WME must be removed from beta memories, and activated production instances for these WME lists must be de-activated and removed from the agenda. Several implementation variations exist, including tree-based and rematch-based removal. Memory indexing may be used in some cases to optimise removal.Handling ORed conditions
When defining productions in a rule set, it is common to allow conditions to be grouped using an OR connectiveLogical connective
In logic, a logical connective is a symbol or word used to connect two or more sentences in a grammatically valid way, such that the compound sentence produced has a truth value dependent on the respective truth values of the original sentences.Each logical connective can be expressed as a...
. In many production systems, this is handled by interpreting a single production containing multiple ORed patterns as the equivalent of multiple productions. The resulting Rete network contains sets of terminal nodes which, together, represent single productions. This approach disallows any form of short-circuiting of the ORed conditions. It can also, in some cases, lead to duplicate production instances being activated on the agenda where the same set of WMEs match multiple internal productions. Some engines provide agenda de-duplication in order to handle this issue.
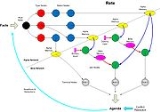
Diagram
The following diagram illustrates the basic Rete topography, and shows the associations between different node types and memories.- Most implementations use type nodes to perform the first level of selection on n-tuple working memory elements. Type nodes can be considered as specialized select nodes. They discriminate between different tuple relation types.
- The diagram does not illustrate the use of specialized nodes types such as negated conjunction nodes. Some engines implement several different node specialisations in order to extend functionality and maximise optimisation.
- The diagram provides a logical view of the Rete. Implementations may differ in physical detail. In particular, the diagram shows dummy inputs providing right activations at the head of beta node branches. Engines may implement other approaches, such as adapters that allow alpha memories to perform right activations directly.
- The diagram does not illustrate all node-sharing possibilities.
For a more detailed and complete description of the Rete algorithm, see chapter 2 of Production Matching for Large Learning Systems by Robert Doorenbos (see link below).
Miscellaneous considerations
Although not defined by the Rete algorithm, some engines provide extended functionality to support greater control of truth maintenance. For example, when a match is found for one production, this may result in the assertion of new WMEs which, in turn, match the conditions for another production. If a subsequent change to working memory causes the first match to become invalid, it may be that this implies that the second match is also invalid. The Rete algorithm does not define any mechanism to define and handle these logical truthLogical truth
Logical truth is one of the most fundamental concepts in logic, and there are different theories on its nature. A logical truth is a statement which is true and remains true under all reinterpretations of its components other than its logical constants. It is a type of analytic statement.Logical...
dependencies automatically. Some engines, however, support additional functionality in which truth dependencies can be automatically maintained. In this case, the retraction of one WME may lead to the automatic retraction of additional WMEs in order to maintain logical truth assertions.
The Rete algorithm does not define any approach to justification. Justification refers to mechanisms commonly required in expert and decision systems in which, at its simplest, the system reports each of the inner decisions used to reach some final conclusion. For example, an expert system might justify a conclusion that an animal is an elephant by reporting that it is large, grey, has big ears, a trunk and tusks. Some engines provide built-in justification systems in conjunction with their implementation of the Rete algorithm.
This article does not provide an exhaustive description of every possible variation or extension of the Rete algorithm. Other considerations and innovations exist. For example, engines may provide specialised support within the Rete network in order to apply pattern-matching rule processing to specific data types and sources such as programmatic objects
Object (computer science)
In computer science, an object is any entity that can be manipulated by the commands of a programming language, such as a value, variable, function, or data structure...
, XML
XML
Extensible Markup Language is a set of rules for encoding documents in machine-readable form. It is defined in the XML 1.0 Specification produced by the W3C, and several other related specifications, all gratis open standards....
data or relational data tables
Table (database)
In relational databases and flat file databases, a table is a set of data elements that is organized using a model of vertical columns and horizontal rows. A table has a specified number of columns, but can have any number of rows...
. Another example concerns additional time-stamping facilities provided by many engines for each WME entering a Rete network, and the use of these time-stamps in conjunction with conflict resolution strategies. Engines exhibit significant variation in the way they allow programmatic access to the engine and its working memory, and may extend the basic Rete model to support forms of parallel and distributed processing.
Optimisation and performance
Several optimisations for Rete have been identified and described in academic literature. Several of these, however, apply only in very specific scenarios, and therefore often have little or no application in a general-purpose rules engine. In addition, alternative algorithms such as TREAT and LEAPS have been formulated which may provide additional performance improvements. There are currently very few commercial or open source examples of productions systems that support these alternative algorithms.The Rete algorithm is orientated to scenarios where forward chaining and "inferencing" is used to calculate new facts from existing facts, or to filter and discard facts in order to arrive at some conclusion. It is also exploited as a reasonably efficient mechanism for performing highly combinatorial evaluations of facts where large numbers of joins must be performed between fact tuples. Other approaches to performing rule evaluation, such as the use of decision trees, or the implementation of sequential engines, may be more appropriate for simple scenarios, and should be considered as possible alternatives.
Rete II
In the 1980s Charles L. Forgy developed a successor to the Rete algorithm named Rete II. Unlike the original Rete (which is public domain) this algorithm was not disclosed. Rete II claims better performance for more complex problems (even orders of magnitude), and is officially implemented in CLIPS/R2.Rete II can be characterized by two areas of improvement; specific optimizations relating to the general performance of the Rete network (including the use of hashed memories in order to increase performance with larger sets of data), and the inclusion of a backward chaining
Backward chaining
Backward chaining is an inference method that can be described as working backward from the goal...
algorithm tailored to run on top of the Rete network. Backward chaining alone can account for the most extreme changes in benchmarks relating to Rete vs. Rete II.
Jess (at least versions 5.0 and later) also adds a backward chaining algorithm on top of the Rete network, but it cannot be said to fully implement Rete II, in part due to the fact that no full specification is publicly available.
See also
- Action selection mechanism
- Expert systemExpert systemIn artificial intelligence, an expert system is a computer system that emulates the decision-making ability of a human expert. Expert systems are designed to solve complex problems by reasoning about knowledge, like an expert, and not by following the procedure of a developer as is the case in...
- Inference engineInference engineIn computer science, and specifically the branches of knowledge engineering and artificial intelligence, an inference engine is a computer program that tries to derive answers from a knowledge base. It is the "brain" that expert systems use to reason about the information in the knowledge base for...
- OPS5OPS5OPS5 is a rule-based or production system computer language, notable as the first such language to be used in a successful expert system, the R1/XCON system used to configure VAX computers....
- Production systemProduction systemA production system is a computer program typically used to provide some form of artificial intelligence, which consists primarily of a set of rules about behavior. These rules, termed productions, are a basic representation found useful in automated planning, expert systems and action selection...
External links
- Rete Algorithm explained Bruce Schneier, Dr. Dobb's Journal
- Production Matching for Large Learning Systems – R Doorenbos Detailed and accessible description of Rete, also describes a variant named Rete/UL, optimised for large systems (PDF)
- According to the Rules (A short introduction from cut-the-knotCut-the-knotCut-the-knot is a free, advertisement-funded educational website maintained by Alexander Bogomolny and devoted to popular exposition of many topics in mathematics. The site has won more than 20 awards from scientific and educational publications, including a Scientific American Web Award in 2003,...
)