

Record linkage
Encyclopedia
Record linkage refers to the task of finding records in a data set that refer to the same entity
across different data sources (e.g., data files, books, websites, databases). Record linkage is necessary when joining
data sets based on entities that may or may not share a common identifier (e.g., database key
, URI
, National identification number
), as may be the case due to differences in record shape, storage location, and/or curator style or preference. A data set that has undergone RL-oriented reconciliation may be referred to as being cross-linked. In mathematical graph theory
, record linkage can be seen as a technique of resolving bipartite graph
s.
in his 1946 article titled "Record Linkage" published in the American Journal of Public Health
. Howard Borden Newcombe laid the probabilistic foundations of modern record linkage theory in a 1959 article in Science
, which were then formalized in 1969 by Ivan Fellegi
and Alan Sunter who and proved that the probabilistic decision rule they described was optimal when the comparison attributes are conditionally independent. Their pioneering work "A Theory For Record Linkage" remains the mathematical foundation for many record linkage applications even today.
Since the late 1990s, various machine learning techniques have been developed that can, under favorable conditions, be used to estimate the conditional probabilities required by the Fellegi-Sunter (FS) theory. Several researchers have reported that the conditional independence assumption of the FS algorithm is often violated in practice; however, published efforts to explicitly model the conditional dependencies among the comparison attributes have not resulted in an improvement in record linkage quality.
Record linkage can be done entirely without the aid of a computer, but the primary reasons computers are often used for record linkage are to reduce or eliminate manual review and to make results more easily reproducible. Computer matching has the advantages of allowing central supervision of processing, better quality control, speed, consistency, and better reproducibility of results.
often refer to it as "data matching" or as the "object identity problem". Other names used to describe the same concept include "entity resolution", "identity resolution
", "entity disambiguation", "duplicate detection", "record matching", "instance identification", "deduplication", "coreference
resolution", "reference reconciliation", "data alignment", and "database hardening". This profusion of terminology has led to few cross-references between these research communities.
While they share similar names, record linkage and Linked Data
are two separate concepts. Whereas record linkage focuses on the more narrow task of identifying matching entities across different data sets, Linked Data focuses on the broader methods of structuring and publishing data to facilitate the discovery of related information.
prior to record linkage. Many key identifiers for the same entity can be presented quite differently between (and even within) data sets, which can greatly complicate record linkage unless understood ahead of time. For example, key identifiers for a man named William J. Smith might appear in three different data sets as so:
In this example, the different formatting styles lead to records that look different but in fact all refer to the same entity with the same logical identifier values. Most, if not all, record linkage strategies would result in more accurate linkage if these values were first normalized or standardized into a consistent format (e.g., all names are "Surname, Given name", all dates are "YYYY/MM/DD", and all cities are "Name, 2-letter state abbreviation"). Standardization can be accomplished through simple rule-based data transformations or more complex procedures such as lexicon-based tokenization and probabilistic hidden Markov models. Several of the packages listed in the Software Implementations section provide some of these features to simplify the process of data standardization.
As an example, consider two standardized data sets, Set A and Set B, that contain different bits of information about patients in a hospital system. The two data sets identify patients using a variety of identifiers: Social Security Number
(SSN), name, date of birth (DOB), sex, and ZIP code
(ZIP). The records in two data sets (identified by the "#" column) are shown below:
The most simple deterministic record linkage strategy would be to pick a single identifier that is assumed to be uniquely identifying, say SSN, and declare that records sharing the same value identify the same person while records not sharing the same value identify different people. In this example, deterministic linkage based on SSN would create entities based on A1 and A2; A3 and B1; and A4. While A1, A2, and B2 appear to represent the same entity, B2 would not be included into the match because it is missing a value for SSN.
Handling exceptions such as missing identifiers involves the creation of additional record linkage rules. One such rule in the case of missing SSN might be to compare name, date of birth, sex, and ZIP code with other records in hopes of finding a match. In the above example, this rule would still not match A1/A2 with B2 because the names are still slightly different: standardization put the names into the proper (Surname, Given name) format but could not discern "Bill" as a nickname for "William". Running names through a phonetic algorithm
such as Soundex
, NYSIIS, or metaphone
, can help to resolve these types of problems (though it may still stumble over surname changes as the result of marriage or divorce), but then B2 would be matched only with A1 since the ZIP code in A2 is different. Thus, another rule would need to be created to determine whether differences in particular identifiers are acceptable (such as ZIP code) and which are not (such as date of birth).
As this example demonstrates, even a small decrease in data quality or small increase in the complexity of the data can result in a very large increase in the number of rules necessary to link records properly. Eventually, these linkage rules will become too numerous and interrelated to to built without the aid of specialized software tools. In addition, linkage rules are often specific to the nature of the data sets they are designed to link together. One study was able to link the Social Security Death Master File
with two hospital registries from the Midwestern United States
using SSN, NYSIIS-encoded first name, birth month, and sex, but these rules may not work as well with data sets from other geographic regions or with data collected on younger populations. Thus, continuous maintenance testing of these rules is necessary to ensure they continue to function as expected as new data enter the system and need to be linked. New data that exhibit different characteristics than was initially expected could require a complete rebuilding of the record linkage rule set, which could be a very time-consuming and expensive endeavor.
, takes a different approach to the record linkage problem by taking into account a wider range of potential identifiers, computing weights for each identifier based on its estimated ability to correctly identify a match or a non-match, and using these weights to calculate the probability that two given records refer to the same entity. Record pairs with probabilities above a certain threshold are considered to be matches, while pairs with probabilities below another threshold are considered to be non-matches; pairs that fall between these two thresholds are considered to be "possible matches" and can be dealt with accordingly (e.g., human reviewed, linked, or not linked, depending on the requirements). Whereas deterministic record linkage requires a series of potentially complex rules to be programmed ahead of time, probabilistic record linkage methods can be "trained" to perform well with much less human intervention.
Many probabilistic record linkage algorithms assign match/non-match weights to identifiers by means of u probabilities and m probabilities. The u probability is the probability that an identifier in two non-matching records will agree purely by chance. For example, the u probability for birth month (where there are twelve values that are approximately uniformly distributed) is 1/12 ≈ 0.083; identifiers with values that are not uniformly distributed will have different u probabilities for different values (possibly including missing values). The m probability is the probability that an identifier in matching pairs will agree (or be sufficiently similar, such as strings with high Jaro-Winkler distance or low Levenshtein distance
). This value would be 1.0 in the case of perfect data, but given that this is rarely (if ever) true, it can instead be estimated. This estimation may be done based on prior knowledge of the data sets, by manually identifying a large number of matching and non-matching pairs to "train" the probabilistic record linkage algorithm, or by iteratively running the algorithm to obtain closer estimations of the m probability. If a value of 0.95 were to be estimated for the m probability, then the match/non-match weights for the birth month identifier would be:
The same calculations would be done for all other identifiers under consideration to find their match/non-match weights. Then, the identifiers of one record would be compared with the identifiers with every other record to compute the total weight: the match weight is added to the running total whenever a pair of identifiers agree, while the non-match weight is added (i.e. the runnin total decreases) whenever the pair of identifiers disagrees. The resulting total weight is then compared to the aforementioned thresholds to determine whether the pair should be linked, non-linked, or set aside for special consideration (e.g. manual validation).
Determining where to set the match/non-match thresholds is a balancing act between obtaining an acceptable sensitivity (or recall, the proportion of truly matching records that are linked by the algorithm) and positive predictive value
(or precision, the proportion of records linked by the algorithm that truly do match). Various manual and automated methods are available to predict the best thresholds, and some record linkage software packages have built-in tools to help the user find the most acceptable values. Because this can be a very computationally demanding task, particularly for large data sets, a technique known as blocking is often used to improve efficiency. Blocking attempts to restrict comparisons to just those records for which one or more particularly discriminating identifiers agree, which has the effect of increasing the positive predictive value (precision) at the expense of sensitivity (recall). For example, blocking based on a phonetically coded surname and ZIP code would reduce the total number of comparisons required and would improve the chances that linked records would be correct (since two identifiers already agree), but would potentially miss records referring to the same person whose surname or ZIP code was different (due to marriage or relocation, for instance). Blocking based on birth month, a more stable identifier that would be expected to change only in the case of data error, would provide a more modest gain in positive predictive value and loss in sensitivity, but would create only twelve distinct groups which, for extremely large data sets, may not provide much net improvement in computation speed. Thus, robust record linkage systems often use multiple blocking passes to group data in various ways in order to come up with groups of records that should be compared to each other.
In recent years, a variety of machine learning techniques have been used in record linkage. It has been recognized that probabilistic record linkage is equivalent to the "Naive Bayes" algorithm in the field of machine learning, and suffers from the same assumption of the independence of its features (an assumption that is typically not true). Higher accuracy can often be achieved by using various other machine learning techniques, including a single-layer perceptron
.
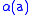 in file A and
in file A and 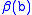 in file B. Assign
in file B. Assign  characteristics to each record. The set of records that represent identical entities is defined by
characteristics to each record. The set of records that represent identical entities is defined by
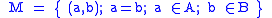
and the complement of set , namely set
, namely set  representing different entities is defined as
representing different entities is defined as
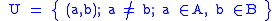 .
.
A vector, is defined, that contains the coded agreements and disagreements on each characteristic:
is defined, that contains the coded agreements and disagreements on each characteristic:
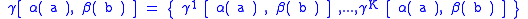
where is a subscript for the characteristics (sex, age, marital status, etc.) in the files. The conditional probabilities of observing a specific vector
is a subscript for the characteristics (sex, age, marital status, etc.) in the files. The conditional probabilities of observing a specific vector  given
given 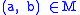 ,
,  are defined as
are defined as

and

respectively.
. Data warehouses serve to combine data from many different operational source systems into one logical data model, which can then be subsequently fed into a business intelligence system for reporting and analytics. Each operational source system may have its own method of identifying the same entities used in the logical data model, so record linkage between the different sources becomes necessary to ensure that the information about a particular entity in one source system can be seamlessly compared with information about the same entity from another source system. Data standardization and subsequent record linkage often occur in the "transform" portion of the extract, transform, load
(ETL) process.
and parish registers were recorded long before the invention of National identification number
s. When old sources are digitized, linking of data sets is a prerequisite for longitudinal study
. This process is often further complicated by lack of standard spelling of names, family names that change according to place of dwelling, changing of administrative boundaries, and problems of checking the data against other sources. Record linkage was among the most prominent themes in the History and computing field in the 1980s, but has since been subject to less attention in research.
based in Rochester, Minnesota
.
Entity
An entity is something that has a distinct, separate existence, although it need not be a material existence. In particular, abstractions and legal fictions are usually regarded as entities. In general, there is also no presumption that an entity is animate.An entity could be viewed as a set...
across different data sources (e.g., data files, books, websites, databases). Record linkage is necessary when joining
Join (SQL)
An SQL join clause combines records from two or more tables in a database. It creates a set that can be saved as a table or used as is. A JOIN is a means for combining fields from two tables by using values common to each. ANSI standard SQL specifies four types of JOINs: INNER, OUTER, LEFT, and RIGHT...
data sets based on entities that may or may not share a common identifier (e.g., database key
Relational model
The relational model for database management is a database model based on first-order predicate logic, first formulated and proposed in 1969 by Edgar F...
, URI
Uniform Resource Identifier
In computing, a uniform resource identifier is a string of characters used to identify a name or a resource on the Internet. Such identification enables interaction with representations of the resource over a network using specific protocols...
, National identification number
National identification number
A national identification number, national identity number, or national insurance number is used by the governments of many countries as a means of tracking their citizens, permanent residents, and temporary residents for the purposes of work, taxation, government benefits, health care, and other...
), as may be the case due to differences in record shape, storage location, and/or curator style or preference. A data set that has undergone RL-oriented reconciliation may be referred to as being cross-linked. In mathematical graph theory
Graph theory
In mathematics and computer science, graph theory is the study of graphs, mathematical structures used to model pairwise relations between objects from a certain collection. A "graph" in this context refers to a collection of vertices or 'nodes' and a collection of edges that connect pairs of...
, record linkage can be seen as a technique of resolving bipartite graph
Bipartite graph
In the mathematical field of graph theory, a bipartite graph is a graph whose vertices can be divided into two disjoint sets U and V such that every edge connects a vertex in U to one in V; that is, U and V are independent sets...
s.
History
The initial idea of record linkage goes back to Halbert L. DunnHalbert L. Dunn
Halbert L. Dunn, M.D. was the leading figure in establishing a national vital statistics system in the United States and is known as the "father of the wellness movement".-Early life:...
in his 1946 article titled "Record Linkage" published in the American Journal of Public Health
American Journal of Public Health
The American Journal of Public Health is a monthly peer-reviewed medical journal published by the American Public Health Association covering health policy and public health. The journal was established in 1911 and its stated mission is "to advance public health research, policy, practice, and...
. Howard Borden Newcombe laid the probabilistic foundations of modern record linkage theory in a 1959 article in Science
Science (journal)
Science is the academic journal of the American Association for the Advancement of Science and is one of the world's top scientific journals....
, which were then formalized in 1969 by Ivan Fellegi
Ivan Fellegi
Ivan Peter Fellegi, OC is a Hungarian-Canadian statistician and was the Chief Statistician of Canada from 1985 to 2008.Born in Szeged, Hungary, Ivan Fellegi was in his third year of studying mathematics at the Eötvös Loránd University, when the Hungarian uprising was crushed in 1956...
and Alan Sunter who and proved that the probabilistic decision rule they described was optimal when the comparison attributes are conditionally independent. Their pioneering work "A Theory For Record Linkage" remains the mathematical foundation for many record linkage applications even today.
Since the late 1990s, various machine learning techniques have been developed that can, under favorable conditions, be used to estimate the conditional probabilities required by the Fellegi-Sunter (FS) theory. Several researchers have reported that the conditional independence assumption of the FS algorithm is often violated in practice; however, published efforts to explicitly model the conditional dependencies among the comparison attributes have not resulted in an improvement in record linkage quality.
Record linkage can be done entirely without the aid of a computer, but the primary reasons computers are often used for record linkage are to reduce or eliminate manual review and to make results more easily reproducible. Computer matching has the advantages of allowing central supervision of processing, better quality control, speed, consistency, and better reproducibility of results.
Naming conventions
"Record linkage" is the term used by statisticians, epidemiologists, and historians, among others, to describe the process of joining records from one data source with another that describe the same entity. Commercial mail and database applications refer to it as "merge/purge processing" or "list washing". Computer scientistsComputer science
Computer science or computing science is the study of the theoretical foundations of information and computation and of practical techniques for their implementation and application in computer systems...
often refer to it as "data matching" or as the "object identity problem". Other names used to describe the same concept include "entity resolution", "identity resolution
Identity resolution
Identity resolution is an operational intelligence process, typically powered by an identity resolution engine or middleware stack, whereby organizations can connect disparate data sources with a view to understanding possible identity matches and non-obvious relationships across multiple data silos...
", "entity disambiguation", "duplicate detection", "record matching", "instance identification", "deduplication", "coreference
Coreference
In linguistics, co-reference occurs when multiple expressions in a sentence or document refer to the same thing; or in linguistic jargon, they have the same "referent."...
resolution", "reference reconciliation", "data alignment", and "database hardening". This profusion of terminology has led to few cross-references between these research communities.
While they share similar names, record linkage and Linked Data
Linked Data
In computing, linked data describes a method of publishing structured data so that it can be interlinked and become more useful. It builds upon standard Web technologies such as HTTP and URIs, but rather than using them to serve web pages for human readers, it extends them to share information in a...
are two separate concepts. Whereas record linkage focuses on the more narrow task of identifying matching entities across different data sets, Linked Data focuses on the broader methods of structuring and publishing data to facilitate the discovery of related information.
Data preprocessing
Record linkage is highly sensitive to the quality of the data being linked, so all data sets under consideration (particularly their key identifier fields) should ideally undergo a data quality assessmentData quality assessment
Data quality assessment is the process of exposing technical and business data issues in order to plan data cleansing and data enrichment strategies...
prior to record linkage. Many key identifiers for the same entity can be presented quite differently between (and even within) data sets, which can greatly complicate record linkage unless understood ahead of time. For example, key identifiers for a man named William J. Smith might appear in three different data sets as so:
| Data set | Name | Date of birth | City of residence |
|---|---|---|---|
| Data set 1 | William J. Smith | 1/2/73 | Berkeley, California |
| Data set 2 | Smith, W. J. | 1973.1.2 | Berkeley, CA |
| Data set 3 | Bill Smith | Jan 2, 1973 | Berkeley, Calif. |
In this example, the different formatting styles lead to records that look different but in fact all refer to the same entity with the same logical identifier values. Most, if not all, record linkage strategies would result in more accurate linkage if these values were first normalized or standardized into a consistent format (e.g., all names are "Surname, Given name", all dates are "YYYY/MM/DD", and all cities are "Name, 2-letter state abbreviation"). Standardization can be accomplished through simple rule-based data transformations or more complex procedures such as lexicon-based tokenization and probabilistic hidden Markov models. Several of the packages listed in the Software Implementations section provide some of these features to simplify the process of data standardization.
Deterministic record linkage
The simplest kind of record linkage, called deterministic or rules-based record linkage, generates links based on the number of individual identifiers that match among the available data sets. Two records are said to match via a deterministic record linkage procedure if all or some identifiers (above a certain threshold) are identical. Deterministic record linkage is a good option when the entities in the data sets are identified by a common identifier, or when there are several representative identifiers (e.g., name, date of birth, and sex when identifying a person) whose quality of data is relatively high.As an example, consider two standardized data sets, Set A and Set B, that contain different bits of information about patients in a hospital system. The two data sets identify patients using a variety of identifiers: Social Security Number
Social Security number
In the United States, a Social Security number is a nine-digit number issued to U.S. citizens, permanent residents, and temporary residents under section 205 of the Social Security Act, codified as . The number is issued to an individual by the Social Security Administration, an independent...
(SSN), name, date of birth (DOB), sex, and ZIP code
ZIP Code
ZIP codes are a system of postal codes used by the United States Postal Service since 1963. The term ZIP, an acronym for Zone Improvement Plan, is properly written in capital letters and was chosen to suggest that the mail travels more efficiently, and therefore more quickly, when senders use the...
(ZIP). The records in two data sets (identified by the "#" column) are shown below:
| Data Set | # | SSN | Name | DOB | Sex | ZIP |
|---|---|---|---|---|---|---|
| Set A | 1 | 000956723 | Smith, William | 1973/01/02 | Male | 94701 |
| 2 | 000956723 | Smith, William | 1973/01/02 | Male | 94703 | |
| 3 | 000005555 | Jones, Robert | 1942/08/14 | Male | 94701 | |
| 4 | 123001234 | Sue, Mary | 1972/11/19 | Female | 94109 | |
| Set B | 1 | 000005555 | Jones, Bob | 1942/08/14 | ||
| 2 | Smith, Bill | 1973/01/02 | Male | 94701 |
The most simple deterministic record linkage strategy would be to pick a single identifier that is assumed to be uniquely identifying, say SSN, and declare that records sharing the same value identify the same person while records not sharing the same value identify different people. In this example, deterministic linkage based on SSN would create entities based on A1 and A2; A3 and B1; and A4. While A1, A2, and B2 appear to represent the same entity, B2 would not be included into the match because it is missing a value for SSN.
Handling exceptions such as missing identifiers involves the creation of additional record linkage rules. One such rule in the case of missing SSN might be to compare name, date of birth, sex, and ZIP code with other records in hopes of finding a match. In the above example, this rule would still not match A1/A2 with B2 because the names are still slightly different: standardization put the names into the proper (Surname, Given name) format but could not discern "Bill" as a nickname for "William". Running names through a phonetic algorithm
Phonetic algorithm
A phonetic algorithm is an algorithm for indexing of words by their pronunciation. Most phonetic algorithms were developed for use with the English language; consequently, applying the rules to words in other languages might not give a meaningful result....
such as Soundex
Soundex
Soundex is a phonetic algorithm for indexing names by sound, as pronounced in English. The goal is for homophones to be encoded to the same representation so that they can be matched despite minor differences in spelling. The algorithm mainly encodes consonants; a vowel will not be encoded unless...
, NYSIIS, or metaphone
Metaphone
Metaphone is a phonetic algorithm, an algorithm published in 1990 for indexing words by their English pronunciation. It fundamentally improves on the Soundex algorithm by using information about variations and inconsistencies in English spelling and pronunciation to produce a more accurate...
, can help to resolve these types of problems (though it may still stumble over surname changes as the result of marriage or divorce), but then B2 would be matched only with A1 since the ZIP code in A2 is different. Thus, another rule would need to be created to determine whether differences in particular identifiers are acceptable (such as ZIP code) and which are not (such as date of birth).
As this example demonstrates, even a small decrease in data quality or small increase in the complexity of the data can result in a very large increase in the number of rules necessary to link records properly. Eventually, these linkage rules will become too numerous and interrelated to to built without the aid of specialized software tools. In addition, linkage rules are often specific to the nature of the data sets they are designed to link together. One study was able to link the Social Security Death Master File
Death Master File
The Death Master File is a computer database file made available by the United States Social Security Administration since 1980. It is known commercially as the Social Security Death Index...
with two hospital registries from the Midwestern United States
Midwestern United States
The Midwestern United States is one of the four U.S. geographic regions defined by the United States Census Bureau, providing an official definition of the American Midwest....
using SSN, NYSIIS-encoded first name, birth month, and sex, but these rules may not work as well with data sets from other geographic regions or with data collected on younger populations. Thus, continuous maintenance testing of these rules is necessary to ensure they continue to function as expected as new data enter the system and need to be linked. New data that exhibit different characteristics than was initially expected could require a complete rebuilding of the record linkage rule set, which could be a very time-consuming and expensive endeavor.
Probabilistic record linkage
Probabilistic record linkage, sometimes called fuzzy matchingFuzzy matching
Fuzzy matching is a technique used in computer-assisted translation and some other information technology applications such as record linkage. It works with matches that may be less than 100% perfect when finding correspondences between segments of a text and entries in a database of previous...
, takes a different approach to the record linkage problem by taking into account a wider range of potential identifiers, computing weights for each identifier based on its estimated ability to correctly identify a match or a non-match, and using these weights to calculate the probability that two given records refer to the same entity. Record pairs with probabilities above a certain threshold are considered to be matches, while pairs with probabilities below another threshold are considered to be non-matches; pairs that fall between these two thresholds are considered to be "possible matches" and can be dealt with accordingly (e.g., human reviewed, linked, or not linked, depending on the requirements). Whereas deterministic record linkage requires a series of potentially complex rules to be programmed ahead of time, probabilistic record linkage methods can be "trained" to perform well with much less human intervention.
Many probabilistic record linkage algorithms assign match/non-match weights to identifiers by means of u probabilities and m probabilities. The u probability is the probability that an identifier in two non-matching records will agree purely by chance. For example, the u probability for birth month (where there are twelve values that are approximately uniformly distributed) is 1/12 ≈ 0.083; identifiers with values that are not uniformly distributed will have different u probabilities for different values (possibly including missing values). The m probability is the probability that an identifier in matching pairs will agree (or be sufficiently similar, such as strings with high Jaro-Winkler distance or low Levenshtein distance
Levenshtein distance
In information theory and computer science, the Levenshtein distance is a string metric for measuring the amount of difference between two sequences...
). This value would be 1.0 in the case of perfect data, but given that this is rarely (if ever) true, it can instead be estimated. This estimation may be done based on prior knowledge of the data sets, by manually identifying a large number of matching and non-matching pairs to "train" the probabilistic record linkage algorithm, or by iteratively running the algorithm to obtain closer estimations of the m probability. If a value of 0.95 were to be estimated for the m probability, then the match/non-match weights for the birth month identifier would be:
| Outcome | Proportion of links | Proportion of non-links | Frequency ratio | Weight |
|---|---|---|---|---|
| Match | m = 0.95 | u ≈ 0.083 | m/u ≈ 11.4 | ln(m/u)/ln(2) ≈ 3.51 |
| Non-match | 1−m = 0.05 | 1-u ≈ 0.917 | (1-m)/(1-u) ≈ 0.0545 | ln((1-m)/(1-u))/ln(2) ≈ -4.20 |
The same calculations would be done for all other identifiers under consideration to find their match/non-match weights. Then, the identifiers of one record would be compared with the identifiers with every other record to compute the total weight: the match weight is added to the running total whenever a pair of identifiers agree, while the non-match weight is added (i.e. the runnin total decreases) whenever the pair of identifiers disagrees. The resulting total weight is then compared to the aforementioned thresholds to determine whether the pair should be linked, non-linked, or set aside for special consideration (e.g. manual validation).
Determining where to set the match/non-match thresholds is a balancing act between obtaining an acceptable sensitivity (or recall, the proportion of truly matching records that are linked by the algorithm) and positive predictive value
Positive predictive value
In statistics and diagnostic testing, the positive predictive value, or precision rate is the proportion of subjects with positive test results who are correctly diagnosed. It is a critical measure of the performance of a diagnostic method, as it reflects the probability that a positive test...
(or precision, the proportion of records linked by the algorithm that truly do match). Various manual and automated methods are available to predict the best thresholds, and some record linkage software packages have built-in tools to help the user find the most acceptable values. Because this can be a very computationally demanding task, particularly for large data sets, a technique known as blocking is often used to improve efficiency. Blocking attempts to restrict comparisons to just those records for which one or more particularly discriminating identifiers agree, which has the effect of increasing the positive predictive value (precision) at the expense of sensitivity (recall). For example, blocking based on a phonetically coded surname and ZIP code would reduce the total number of comparisons required and would improve the chances that linked records would be correct (since two identifiers already agree), but would potentially miss records referring to the same person whose surname or ZIP code was different (due to marriage or relocation, for instance). Blocking based on birth month, a more stable identifier that would be expected to change only in the case of data error, would provide a more modest gain in positive predictive value and loss in sensitivity, but would create only twelve distinct groups which, for extremely large data sets, may not provide much net improvement in computation speed. Thus, robust record linkage systems often use multiple blocking passes to group data in various ways in order to come up with groups of records that should be compared to each other.
In recent years, a variety of machine learning techniques have been used in record linkage. It has been recognized that probabilistic record linkage is equivalent to the "Naive Bayes" algorithm in the field of machine learning, and suffers from the same assumption of the independence of its features (an assumption that is typically not true). Higher accuracy can often be achieved by using various other machine learning techniques, including a single-layer perceptron
Perceptron
The perceptron is a type of artificial neural network invented in 1957 at the Cornell Aeronautical Laboratory by Frank Rosenblatt. It can be seen as the simplest kind of feedforward neural network: a linear classifier.- Definition :...
.
Mathematical model
In an application with two files, A and B, denote the rows (records) by in file A and in file B. Assign characteristics to each record. The set of records that represent identical entities is defined byand the complement of set
, namely set representing different entities is defined as.A vector,
is defined, that contains the coded agreements and disagreements on each characteristic:where
is a subscript for the characteristics (sex, age, marital status, etc.) in the files. The conditional probabilities of observing a specific vector given , are defined asand
respectively.
Data warehousing and business intelligence
Record linkage plays a key role in data warehousing and business intelligenceBusiness intelligence
Business intelligence mainly refers to computer-based techniques used in identifying, extracting, and analyzing business data, such as sales revenue by products and/or departments, or by associated costs and incomes....
. Data warehouses serve to combine data from many different operational source systems into one logical data model, which can then be subsequently fed into a business intelligence system for reporting and analytics. Each operational source system may have its own method of identifying the same entities used in the logical data model, so record linkage between the different sources becomes necessary to ensure that the information about a particular entity in one source system can be seamlessly compared with information about the same entity from another source system. Data standardization and subsequent record linkage often occur in the "transform" portion of the extract, transform, load
Extract, transform, load
Extract, transform and load is a process in database usage and especially in data warehousing that involves:* Extracting data from outside sources* Transforming it to fit operational needs...
(ETL) process.
Historical research
Record linkage is important to social history research since most data sets, such as census recordsCensus
A census is the procedure of systematically acquiring and recording information about the members of a given population. It is a regularly occurring and official count of a particular population. The term is used mostly in connection with national population and housing censuses; other common...
and parish registers were recorded long before the invention of National identification number
National identification number
A national identification number, national identity number, or national insurance number is used by the governments of many countries as a means of tracking their citizens, permanent residents, and temporary residents for the purposes of work, taxation, government benefits, health care, and other...
s. When old sources are digitized, linking of data sets is a prerequisite for longitudinal study
Longitudinal study
A longitudinal study is a correlational research study that involves repeated observations of the same variables over long periods of time — often many decades. It is a type of observational study. Longitudinal studies are often used in psychology to study developmental trends across the...
. This process is often further complicated by lack of standard spelling of names, family names that change according to place of dwelling, changing of administrative boundaries, and problems of checking the data against other sources. Record linkage was among the most prominent themes in the History and computing field in the 1980s, but has since been subject to less attention in research.
Medical practice and research
Record linkage is an important tool in creating data required for examining the health of the public and of the health care system itself. It can be used to improve data holdings, data collection, quality assessment, and the dissemination of information. Data sources can be examined to eliminate duplicate records, to identify under-reporting and missing cases (e.g., census population counts), to create person-oriented health statistics, and to generate disease registries and health surveillance systems. Some cancer registries link various data sources (e.g., hospital admissions, pathology and clinical reports, and death registrations) to generate their registries. Record linkage is also used to create health indicators. For example, fetal and infant mortality is a general indicator of a country's socioeconomic development, public health, and maternal and child services. If infant death records are matched to birth records, it is possible to use birth variables, such as birth weight and gestational age, along with mortality data, such as cause of death, in analyzing the data. Linkages can help in follow-up studies of cohorts or other groups to determine factors such as vital status, residential status, or health outcomes. Tracing is often needed for follow-up of industrial cohorts, clinical trials, and longitudinal surveys to obtain the cause of death and/or cancer. An example of a successful and long-standing record linkage system allowing for population-based medical research is the Rochester Epidemiology ProjectRochester Epidemiology Project
The Rochester Epidemiology Project is a unique research infrastructure that has existed since 1966, and allows for population-based medical research in Olmsted County, Minnesota. The project has been continually funded by the National Institutes of Health since 1966...
based in Rochester, Minnesota
Rochester, Minnesota
Rochester is a city in the U.S. state of Minnesota and is the county seat of Olmsted County. Located on both banks of the Zumbro River, The city has a population of 106,769 according to the 2010 United States Census, making it Minnesota's third-largest city and the largest outside of the...
.
Software implementations
- Duke - small and fast Java deduplication and record linkage engine (open source)
- Data Deduplication and Integration - developed by the CS department at University of MarylandUniversity of MarylandWhen the term "University of Maryland" is used without any qualification, it generally refers to the University of Maryland, College Park.University of Maryland may refer to the following:...
- DataCleaner - by eobjects.org
- Daurum - Deduplication and Integration tool & services - by Sparsity Technologies
- Febrl - Open source software application for RL - by the Australian National UniversityAustralian National UniversityThe Australian National University is a teaching and research university located in the Australian capital, Canberra.As of 2009, the ANU employs 3,945 administrative staff who teach approximately 10,000 undergraduates, and 7,500 postgraduate students...
. - FRIL - Fine-Grained Record Integration and Linkage Tool - developed at the Emory UniversityEmory UniversityEmory University is a private research university in metropolitan Atlanta, located in the Druid Hills section of unincorporated DeKalb County, Georgia, United States. The university was founded as Emory College in 1836 in Oxford, Georgia by a small group of Methodists and was named in honor of...
and US Centers For Disease Control and PreventionCenters for Disease Control and PreventionThe Centers for Disease Control and Prevention are a United States federal agency under the Department of Health and Human Services headquartered in Druid Hills, unincorporated DeKalb County, Georgia, in Greater Atlanta... - Link Plus Probabilistic record linkage program - developed at the US Centers For Disease Control and PreventionCenters for Disease Control and PreventionThe Centers for Disease Control and Prevention are a United States federal agency under the Department of Health and Human Services headquartered in Druid Hills, unincorporated DeKalb County, Georgia, in Greater Atlanta...
- MTB - Merge ToolBox - by the University of Duisburg-EssenUniversity of Duisburg-EssenThe University Duisburg-Essen is a public university in Duisburg and Essen, North Rhine-Westphalia, Germany and a member of the new founded University Alliance Metropolis Ruhr....
- Open Source ChoiceMaker Technology - released by ChoiceMaker Technologies
- OpenDQ Massively scalable record linkage / Data Matching - by Infosolve Technologies
- Silk - open source RDF-based record linkage framework from Freie Universität Berlin
- SimMetrics Open source library of String Similarity techniques - by Sam Chapman at the University of SheffieldUniversity of SheffieldThe University of Sheffield is a research university based in the city of Sheffield in South Yorkshire, England. It is one of the original 'red brick' universities and is a member of the Russell Group of leading research intensive universities...
- DataQualityTools - by DataQualityApps
- The Link King - SAS System application - developed at Washington State's Division of Alcohol and Substance Abuse (DASA) by Kevin M. Campbell
- MatchMetrix EMPI - Enterprise Master Patient Index - developed by NextGate
- Data Match - DataMatch 2011 for record linkage - developed by Dataladder
- Oyster Entity Resolution - Oyster Entity Resolution - Developed by The University of Arkansas at Little Rock, John Talburt Ph.D.
See also
- Identity resolutionIdentity resolutionIdentity resolution is an operational intelligence process, typically powered by an identity resolution engine or middleware stack, whereby organizations can connect disparate data sources with a view to understanding possible identity matches and non-obvious relationships across multiple data silos...
- Linked DataLinked DataIn computing, linked data describes a method of publishing structured data so that it can be interlinked and become more useful. It builds upon standard Web technologies such as HTTP and URIs, but rather than using them to serve web pages for human readers, it extends them to share information in a...
- Entity-attribute-value modelEntity-Attribute-Value modelEntity–attribute–value model is a data model to describe entities where the number of attributes that can be used to describe them is potentially vast, but the number that will actually apply to a given entity is relatively modest. In mathematics, this model is known as a sparse matrix...
- Open DataOpen DataOpen data is the idea that certain data should be freely available to everyone to use and republish as they wish, without restrictions from copyright, patents or other mechanisms of control. The goals of the open data movement are similar to those of other "Open" movements such as open source, open...
- Delta encodingDelta encodingDelta encoding is a way of storing or transmitting data in the form of differences between sequential data rather than complete files; more generally this is known as data differencing...
- Identity resolutionIdentity resolutionIdentity resolution is an operational intelligence process, typically powered by an identity resolution engine or middleware stack, whereby organizations can connect disparate data sources with a view to understanding possible identity matches and non-obvious relationships across multiple data silos...
- Data deduplicationData deduplicationIn computing, data deduplication is a specialized data compression technique for eliminating coarse-grained redundant data. The technique is used to improve storage utilization and can also be applied to network data transfers to reduce the number of bytes that must be sent across a link...
- Capacity optimizationCapacity optimizationCapacity optimization is a general term for technologies used to improve storage utilization by shrinking stored data. The primary technologies used for capacity optimization are deduplication and data compression. These solutions are delivered as software or hardware solution, integrated with...
- Single-instance storageSingle-instance storageSingle-instance storage is a system's ability to keep one copy of content that multiple users or computers share. It is a means to eliminate data duplication and to increase efficiency...
- Content-addressable storageContent-addressable storageContent-addressable storage, also referred to as associative storage or abbreviated CAS, is a mechanism for storing information that can be retrieved based on its content, not its storage location. It is typically used for high-speed storage and retrieval of fixed content, such as documents stored...