An artificial neural network , usually called neural network , is a mathematical model or computational model that is inspired by the structure and/or functional aspects of biological neural networks. A neural network consists of an interconnected group of artificial neurons, and it processes...
Calspan Corporation is a science and technology company originally founded in 1943 as part of the Research Laboratory of the Curtiss-Wright Airplane Division at Buffalo, New York. Calspan consists of 5 divisions: Flight Research, Transonic Wind Tunnel, Systems Engineering, Transportation Sciences...
Frank Rosenblatt was a New York City born computer scientist who completed the Perceptron, or MARK 1, computer at Cornell University in 1960...
. It can be seen as the simplest kind of feedforward neural network: a linear classifier
Linear classifier
In the field of machine learning, the goal of statistical classification is to use an object's characteristics to identify which class it belongs to. A linear classifier achieves this by making a classification decision based on the value of a linear combination of the characteristics...
.
Definition
The perceptron is a binary classifier which maps its input (a real-valued vector
Vector space
A vector space is a mathematical structure formed by a collection of vectors: objects that may be added together and multiplied by numbers, called scalars in this context. Scalars are often taken to be real numbers, but one may also consider vector spaces with scalar multiplication by complex...
In mathematics, a binary function, or function of two variables, is a function which takes two inputs.Precisely stated, a function f is binary if there exists sets X, Y, Z such that\,f \colon X \times Y \rightarrow Z...
value):
where is a vector of real-valued weights, is the dot product
Dot product
In mathematics, the dot product or scalar product is an algebraic operation that takes two equal-length sequences of numbers and returns a single number obtained by multiplying corresponding entries and then summing those products...
(which here computes a weighted sum), and is the 'bias', a constant term that does not depend on any input value.
The value of (0 or 1) is used to classify as either a positive or a negative instance, in the case of a binary classification problem. If is negative, then the weighted combination of inputs must produce a positive value greater than in order to push the classifier neuron over the 0 threshold. Spatially, the bias alters the position (though not the orientation) of the decision boundary
Decision boundary
In a statistical-classification problem with two classes, a decision boundary or decision surface is a hypersurface that partitions the underlying vector space into two sets, one for each class...
. The perceptron learning algorithm does not terminate if the learning set is not linearly separable
Linearly separable
In geometry, two sets of points in a two-dimensional space are linearly separable if they can be completely separated by a single line. In general, two point sets are linearly separable in n-dimensional space if they can be separated by a hyperplane....
.
The perceptron is considered the simplest kind of feed-forward neural network.
Learning algorithm
Below is an example of a learning algorithm for a single-layer (no hidden layer) perceptron. For multilayer perceptron
Multilayer perceptron
A multilayer perceptron is a feedforward artificial neural network model that maps sets of input data onto a set of appropriate output. An MLP consists of multiple layers of nodes in a directed graph, with each layer fully connected to the next one. Except for the input nodes, each node is a...
Backpropagation is a common method of teaching artificial neural networks how to perform a given task. Arthur E. Bryson and Yu-Chi Ho described it as a multi-stage dynamic system optimization method in 1969 . It wasn't until 1974 and later, when applied in the context of neural networks and...
must be used. Alternatively, methods such as the delta rule
Delta rule
The delta rule is a gradient descent learning rule for updating the weights of the artificial neurons in a single-layer perceptron. It is a special case of the more general backpropagation algorithm...
can be used if the function is non-linear and differentiable, although the one below will work as well.
The learning algorithm we demonstrate is the same across all the output neurons, therefore everything that follows is applied to a single neuron in isolation. We first define some variables:
denotes the output from the perceptron for an input vector .
is the bias term, which in the example below we take to be 0.
is the training set of samples, where:
is the -dimensional input vector.
is the desired output value of the perceptron for that input.
We show the values of the nodes as follows:
is the value of the th node of the th training input vector.
.
To represent the weights:
is the th value in the weight vector, to be multiplied by the value of the th input node.
An extra dimension, with index , can be added to all input vectors, with , in which case replaces the bias term.
To show the time-dependence of , we use:
is the weight at time .
is the learning rate, where .
Too high a learning rate makes the perceptron periodically oscillate around the solution unless additional steps are taken.
Learning algorithm steps
1. Initialise weights and threshold.
Note that weights may be initialised by setting each weight node to 0 or to a small random value. In the example below, we choose the former.
2. For each sample in our training set , perform the following steps over the input and desired output :
2a. Calculate the actual output:
2b. Adapt weights:
, for all nodes .
Step 2 is repeated until the iteration error is less than a user-specified error threshold , or a predetermined number of iterations have been completed. Note that the algorithm adapts the weights immediately after steps 2a and 2b are applied to a pair in the training set rather than waiting until all pairs in the training set have undergone these steps.
In geometry, two sets of points in a two-dimensional space are linearly separable if they can be completely separated by a single line. In general, two point sets are linearly separable in n-dimensional space if they can be separated by a hyperplane....
if there exists a positive constant and a weight vector such that for all . That is, if we say that is the weight vector to the perceptron, then the output of the perceptron, , multiplied by the desired output of the perceptron, , must be greater than the positive constant, , for all input-vector/output-value pairs in .
Novikoff (1962) proved that the perceptron algorithm converges after a finite number of iterations if the data set
Data set
A data set is a collection of data, usually presented in tabular form. Each column represents a particular variable. Each row corresponds to a given member of the data set in question. Its values for each of the variables, such as height and weight of an object or values of random numbers. Each...
is linearly separable. The idea of the proof is that the weight vector is always adjusted by a bounded amount in a direction that it has a negative dot product
Dot product
In mathematics, the dot product or scalar product is an algebraic operation that takes two equal-length sequences of numbers and returns a single number obtained by multiplying corresponding entries and then summing those products...
with, and thus can be bounded above by where t is the number of changes to the weight vector. But it can also be bounded below by because if there exists an (unknown) satisfactory weight vector, then every change makes progress in this (unknown) direction by a positive amount that depends only on the input vector.
This can be used to show that the number of updates to the weight vector is bounded by , where is the maximum norm of an input vector.
In geometry, two sets of points in a two-dimensional space are linearly separable if they can be completely separated by a single line. In general, two point sets are linearly separable in n-dimensional space if they can be separated by a hyperplane....
In computer science, an online algorithm is one that can process its input piece-by-piece in a serial fashion, i.e., in the order that the input is fed to the algorithm, without having the entire input available from the start. In contrast, an offline algorithm is given the whole problem data from...
will not converge.
Note that the decision boundary of a perceptron is invariant with respect to scaling of the weight vector, i.e. a perceptron trained with initial weight vector and learning rate is an identical estimator to a perceptron trained with initial weight vector and learning rate 1. Thus, since the initial weights become irrelevant with increasing number of iterations, the learning rate does not matter in the case of the perceptron and is usually just set to one.
Variants
The pocket algorithm with ratchet (Gallant, 1990) solves the stability problem of perceptron learning by keeping the best solution seen so far "in its pocket". The pocket algorithm then returns the solution in the pocket, rather than the last solution. It can be used also for non-separable data sets, where the aim is to find a perceptron with a small number of misclassifications.
In separable problems, perceptron training can also aim at finding the largest separating margin between the classes. The so-called perceptron of optimal stability can be determined by means of iterative training and optimization schemes, e.g. the Min-Over algorithm (Krauth and Mezard, 1987) or the AdaTron (Anlauf and Biehl, 1989))
. The latter exploits the fact that the corresponding
quadratic optimization problem is convex. The perceptron of optimal stability is, together with the kernel trick
Kernel trick
For machine learning algorithms, the kernel trick is a way of mapping observations from a general set S into an inner product space V , without ever having to compute the mapping explicitly, in the hope that the observations will gain meaningful linear structure in V...
A support vector machine is a concept in statistics and computer science for a set of related supervised learning methods that analyze data and recognize patterns, used for classification and regression analysis...
.
The -perceptron further utilised a preprocessing layer of fixed random weights, with thresholded output units. This enabled the perceptron to classify analogue patterns, by projecting them into a binary space. In fact, for a projection space of sufficiently high dimension, patterns can become linearly separable.
As an example, consider the case of having to classify data into two classes. Here is a small such data set, consisting of two points coming from two Gaussian distributions.
A linear classifier can only separate things with a hyperplane
Hyperplane
A hyperplane is a concept in geometry. It is a generalization of the plane into a different number of dimensions.A hyperplane of an n-dimensional space is a flat subset with dimension n − 1...
, so it's not possible to classify all the examples perfectly. On the other hand, we may project the data into a large number of dimensions. In this case a random matrix
Random matrix
In probability theory and mathematical physics, a random matrix is a matrix-valued random variable. Many important properties of physical systems can be represented mathematically as matrix problems...
was used to project the data linearly to a 1000-dimensional space; then each resulting data point was transformed through the hyperbolic tangent function
Hyperbolic function
In mathematics, hyperbolic functions are analogs of the ordinary trigonometric, or circular, functions. The basic hyperbolic functions are the hyperbolic sine "sinh" , and the hyperbolic cosine "cosh" , from which are derived the hyperbolic tangent "tanh" and so on.Just as the points form a...
. A linear classifier can then separate the data, as shown in the third figure. However the data may still not be completely separable in this space, in which the perceptron algorithm would not converge. In the example shown, stochastic steepest gradient descent
Stochastic gradient descent
Stochastic gradient descent is an optimization method for minimizing an objective function that is written as a sum of differentiable functions.- Background :...
was used to adapt the parameters.
Furthermore, by adding nonlinear layers between the input and output, one can separate all data and indeed, with enough training data, model any well-defined function to arbitrary precision. This model is a generalization known as a multilayer perceptron
Multilayer perceptron
A multilayer perceptron is a feedforward artificial neural network model that maps sets of input data onto a set of appropriate output. An MLP consists of multiple layers of nodes in a directed graph, with each layer fully connected to the next one. Except for the input nodes, each node is a...
.
Another way to solve nonlinear problems without the need of multiple layers is the use of higher order networks (sigma-pi unit). In this type of network each element in the input vector is extended with each pairwise combination of multiplied inputs (second order). This can be extended to n-order network.
It should be kept in mind, however, that the best classifier is not necessarily that which classifies all the training data perfectly. Indeed, if we had the prior constraint that the data come from equi-variant Gaussian distributions, the linear separation in the input space is optimal.
Other training algorithms for linear classifiers are possible: see, e.g., support vector machine
Support vector machine
A support vector machine is a concept in statistics and computer science for a set of related supervised learning methods that analyze data and recognize patterns, used for classification and regression analysis...
In statistics, logistic regression is used for prediction of the probability of occurrence of an event by fitting data to a logit function logistic curve. It is a generalized linear model used for binomial regression...
NAND may stand for:*Nand , an Indian classical raga.*Logical NAND , a binary operation in logic.**NAND gate, an electronic gate that implements a logical NAND....
function on inputs and .
Inputs: , , , with input held constant at 1.
Threshold: 0.5
Bias: 0
Learning rate: 0.1
Training set, consisting of four samples:
In the following, the final weights of one iteration become the initial weights of the next. Each cycle over all the samples in the training set is demarcated with heavy lines.
generated with :de:Wikipedia:Helferlein/VBA-Macro for EXCEL tableconversion V1.7 - - Edited in native ascii code by FabioVeronese, pgan002<\hiddentext>>
Input
Initial weights
Output
Error
Correction
Final weights
Sensor values
Desired output
Per sensor
Sum
Network
x0
x1
x2
z
w0
w1
w2
c0
c1
c2
s
n
e
d
w0
w1
w2
x0 * w0
x1 * w1
x2 * w2
c0 +c1 +c2
if s>t then 1, else 0
z-n
r * e
1
0
0
1
0
0
0
0
0
0
0
0
1
+0.1
0.1
0
0
1
0
1
1
0.1
0
0
0.1
0
0
0.1
0
1
+0.1
0.2
0
0.1
1
1
0
1
0.2
0
0.1
0.2
0
0
0.2
0
1
+0.1
0.3
0.1
0.1
1
1
1
0
0.3
0.1
0.1
0.3
0.1
0.1
0.5
0
0
0
0.3
0.1
0.1
1
0
0
1
0.3
0.1
0.1
0.3
0
0
0.3
0
1
+0.1
0.4
0.1
0.1
1
0
1
1
0.4
0.1
0.1
0.4
0
0.1
0.5
0
1
+0.1
0.5
0.1
0.2
1
1
0
1
0.5
0.1
0.2
0.5
0.1
0
0.6
1
0
0
0.5
0.1
0.2
1
1
1
0
0.5
0.1
0.2
0.5
0.1
0.2
0.8
1
-1
-0.1
0.4
0
0.1
1
0
0
1
0.4
0
0.1
0.4
0
0
0.4
0
1
+0.1
0.5
0
0.1
1
0
1
1
0.5
0
0.1
0.5
0
0.1
0.6
1
0
0
0.5
0
0.1
1
1
0
1
0.5
0
0.1
0.5
0
0
0.5
0
1
+0.1
0.6
0.1
0.1
1
1
1
0
0.6
0.1
0.1
0.6
0.1
0.1
0.8
1
-1
-0.1
0.5
0
0
1
0
0
1
0.5
0
0
0.5
0
0
0.5
0
1
+0.1
0.6
0
0
1
0
1
1
0.6
0
0
0.6
0
0
0.6
1
0
0
0.6
0
0
1
1
0
1
0.6
0
0
0.6
0
0
0.6
1
0
0
0.6
0
0
1
1
1
0
0.6
0
0
0.6
0
0
0.6
1
-1
-0.1
0.5
-0.1
-0.1
1
0
0
1
0.5
-0.1
-0.1
0.5
0
0
0.5
0
1
+0.1
0.6
-0.1
-0.1
1
0
1
1
0.6
-0.1
-0.1
0.6
0
-0.1
0.5
0
1
+0.1
0.7
-0.1
0
1
1
0
1
0.7
-0.1
0
0.7
-0.1
0
0.6
1
0
0
0.7
-0.1
0
1
1
1
0
0.7
-0.1
0
0.7
-0.1
0
0.6
1
-1
-0.1
0.6
-0.2
-0.1
1
0
0
1
0.6
-0.2
-0.1
0.6
0
0
0.6
1
0
0
0.6
-0.2
-0.1
1
0
1
1
0.6
-0.2
-0.1
0.6
0
-0.1
0.5
0
1
+0.1
0.7
-0.2
0
1
1
0
1
0.7
-0.2
0
0.7
-0.2
0
0.5
0
1
+0.1
0.8
-0.1
0
1
1
1
0
0.8
-0.1
0
0.8
-0.1
0
0.7
1
-1
-0.1
0.7
-0.2
-0.1
1
0
0
1
0.7
-0.2
-0.1
0.7
0
0
0.7
1
0
0
0.7
-0.2
-0.1
1
0
1
1
0.7
-0.2
-0.1
0.7
0
-0.1
0.6
1
0
0
0.7
-0.2
-0.1
1
1
0
1
0.7
-0.2
-0.1
0.7
-0.2
0
0.5
0
1
+0.1
0.8
-0.1
-0.1
1
1
1
0
0.8
-0.1
-0.1
0.8
-0.1
-0.1
0.6
1
-1
-0.1
0.7
-0.2
-0.2
1
0
0
1
0.7
-0.2
-0.2
0.7
0
0
0.7
1
0
0
0.7
-0.2
-0.2
1
0
1
1
0.7
-0.2
-0.2
0.7
0
-0.2
0.5
0
1
+0.1
0.8
-0.2
-0.1
1
1
0
1
0.8
-0.2
-0.1
0.8
-0.2
0
0.6
1
0
0
0.8
-0.2
-0.1
1
1
1
0
0.8
-0.2
-0.1
0.8
-0.2
-0.1
0.5
0
0
0
0.8
-0.2
-0.1
1
0
0
1
0.8
-0.2
-0.1
0.8
0
0
0.8
1
0
0
0.8
-0.2
-0.1
1
0
1
1
0.8
-0.2
-0.1
0.8
0
-0.1
0.7
1
0
0
0.8
-0.2
-0.1
This example can be implemented in the following Python
Python (programming language)
Python is a general-purpose, high-level programming language whose design philosophy emphasizes code readability. Python claims to "[combine] remarkable power with very clear syntax", and its standard library is large and comprehensive...
def sum_function(values):
return sum(value * weights[index] for index, value in enumerate(values))
while True:
print '-' * 60
error_count = 0
for input_vector, desired_output in training_set:
print weights
result = 1 if sum_function(input_vector) > threshold else 0
error = desired_output - result
if error != 0:
error_count += 1
for index, value in enumerate(input_vector):
weights[index] += learning_rate * error * value
if error_count
0:
break
Multiclass perceptron
Like most other techniques for training linear classifiers, the perceptron generalizes naturally to multiclass classification
Multiclass classification
In machine learning, multiclass or multinomial classification is the problem of classifying instances into more than two classes.While some classification algorithms naturally permit the use of more than two classes, others are by nature binary algorithms; these can, however, be turned into...
. Here, the input and the output are drawn from arbitrary sets. A feature representation function maps each possible input/output pair to a finite-dimensional real-valued feature vector. As before, the feature vector is multiplied by a weight vector , but now the resulting score is used to choose among many possible outputs:
Learning again iterates over the examples, predicting an output for each, leaving the weights unchanged when the predicted output matches the target, and changing them when it does not. The update becomes:
This multiclass formulation reduces to the original perceptron when is a real-valued vector, is chosen from , and .
For certain problems, input/output representations and features can be chosen so that can be found efficiently even though is chosen from a very large or even infinite set.
Natural language processing is a field of computer science and linguistics concerned with the interactions between computers and human languages; it began as a branch of artificial intelligence....
In corpus linguistics, part-of-speech tagging , also called grammatical tagging or word-category disambiguation, is the process of marking up a word in a text as corresponding to a particular part of speech, based on both its definition, as well as its context—i.e...
and syntactic parsing (Collins, 2002).
History
See also: History of artificial intelligence, AI winter and Frank Rosenblatt
Frank Rosenblatt
Frank Rosenblatt was a New York City born computer scientist who completed the Perceptron, or MARK 1, computer at Cornell University in 1960...
Although the perceptron initially seemed promising, it was eventually proved that perceptrons could not be trained to recognise many classes of patterns. This led to the field of neural network research stagnating for many years, before it was recognised that a feedforward neural network with two or more layers (also called a multilayer perceptron) had far greater processing power than perceptrons with one layer (also called a single layer perceptron).
Single layer perceptrons are only capable of learning linearly separable
Linearly separable
In geometry, two sets of points in a two-dimensional space are linearly separable if they can be completely separated by a single line. In general, two point sets are linearly separable in n-dimensional space if they can be separated by a hyperplane....
patterns; in 1969 a famous book entitled Perceptrons
Perceptrons (book)
Perceptrons: an introduction to computational geometry is a book authored by Marvin Minsky and Seymour Papert, published in 1969. An edition with handwritten corrections and additions was released in the early 1970s...
Marvin Lee Minsky is an American cognitive scientist in the field of artificial intelligence , co-founder of Massachusetts Institute of Technology's AI laboratory, and author of several texts on AI and philosophy.-Biography:...
Seymour Papert is an MIT mathematician, computer scientist, and educator. He is one of the pioneers of artificial intelligence, as well as an inventor of the Logo programming language....
showed that it was impossible for these classes of network to learn an XOR function. It is often believed that they also conjectured (incorrectly) that a similar result would hold for a multi-layer perceptron network. However, this is not true, as both Minsky and Papert already knew that multi-layer perceptrons were capable of producing an XOR Function. (See the page on Perceptrons
Perceptrons (book)
Perceptrons: an introduction to computational geometry is a book authored by Marvin Minsky and Seymour Papert, published in 1969. An edition with handwritten corrections and additions was released in the early 1970s...
Stephen Grossberg is a cognitive scientist, neuroscientist, biomedical engineer, mathematician, and neuromorphic technologist. He is the Wang Professor of Cognitive and Neural Systems and a Professor of Mathematics, Psychology, and Biomedical Engineering at Boston University.Grossberg's work...
published a series of papers introducing networks capable of modelling differential, contrast-enhancing and XOR functions. (The papers were published in 1972 and 1973, see e.g.: Grossberg, Contour enhancement, short-term memory, and constancies in reverberating neural networks. Studies in Applied Mathematics, 52 (1973), 213-257, online http://cns.bu.edu/Profiles/Grossberg/Gro1973StudiesAppliedMath.pdf). Nevertheless the often-miscited Minsky/Papert text caused a significant decline in interest and funding of neural network research. It took ten more years until neural network
Neural network
The term neural network was traditionally used to refer to a network or circuit of biological neurons. The modern usage of the term often refers to artificial neural networks, which are composed of artificial neurons or nodes...
research experienced a resurgence in the 1980s. This text was reprinted in 1987 as "Perceptrons - Expanded Edition" where some errors in the original text are shown and corrected.
More recently, interest in the perceptron learning algorithm increased again after Freund
Yoav Freund
Yoav Freund is a researcher and professor at the University of California, San Diego who mainly works on machine learning, probability theory and related fields and applications.From his homepage:...
Robert Elias Schapire is a professor and researcher in the computer science department at Princeton University. His primary specialty is theoretical and applied machine learning....
(1998) showed that presented a voted formulation of the original algorithm (attaining a large margin) to which the kernel trick
Kernel trick
For machine learning algorithms, the kernel trick is a way of mapping observations from a general set S into an inner product space V , without ever having to compute the mapping explicitly, in the hope that the observations will gain meaningful linear structure in V...
can be applied. Subsequent studies have shown its applicability to a class of more complex tasks, later called as structured learning
Structured learning
Structured learning is the subfield of machine learning concerned with computer programs that learn to map inputs to arbitrarily complex outputs. This stands in contrast to the simpler approaches of classification, where input data are mapped to "atomic" labels, i.e...
, than binary classification (Collins, 2002), and to large-scale machine learning problems in a distributed computing
Distributed computing
Distributed computing is a field of computer science that studies distributed systems. A distributed system consists of multiple autonomous computers that communicate through a computer network. The computers interact with each other in order to achieve a common goal...
setting (McDonald, Hall and Mann, 2010).
External links
Raúl Rojas González is a professor of Computer Science and Mathematics at the Free University of Berlin and a renowned specialist in artificial neural networks. The FU-Fighters, football-playing robots he helped build, were world champions in 2004 and 2005...


 (a real-valued vector
(a real-valued vector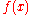 (a single binary
(a single binary
 is a vector of real-valued weights,
is a vector of real-valued weights,  is the dot product
is the dot product is the 'bias', a constant term that does not depend on any input value.
is the 'bias', a constant term that does not depend on any input value.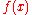 (0 or 1) is used to classify
(0 or 1) is used to classify  as either a positive or a negative instance, in the case of a binary classification problem. If
as either a positive or a negative instance, in the case of a binary classification problem. If  is negative, then the weighted combination of inputs must produce a positive value greater than
is negative, then the weighted combination of inputs must produce a positive value greater than  in order to push the classifier neuron over the 0 threshold. Spatially, the bias alters the position (though not the orientation) of the decision boundary
in order to push the classifier neuron over the 0 threshold. Spatially, the bias alters the position (though not the orientation) of the decision boundary , can be added to all input vectors, with
, can be added to all input vectors, with 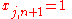 , in which case
, in which case  replaces the bias term.
replaces the bias term. , we use:
, we use:
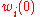 to 0 or to a small random value. In the example below, we choose the former.
to 0 or to a small random value. In the example below, we choose the former. in our training set
in our training set  , perform the following steps over the input
, perform the following steps over the input 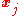 and desired output
and desired output 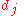 :
: is less than a user-specified error threshold
is less than a user-specified error threshold  , or a predetermined number of iterations have been completed. Note that the algorithm adapts the weights immediately after steps 2a and 2b are applied to a pair in the training set rather than waiting until all pairs in the training set have undergone these steps.
, or a predetermined number of iterations have been completed. Note that the algorithm adapts the weights immediately after steps 2a and 2b are applied to a pair in the training set rather than waiting until all pairs in the training set have undergone these steps. is said to be linearly separable
is said to be linearly separable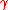 and a weight vector
and a weight vector  such that
such that 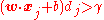 for all
for all  . That is, if we say that
. That is, if we say that  is the weight vector to the perceptron, then the output of the perceptron,
is the weight vector to the perceptron, then the output of the perceptron, 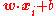 , multiplied by the desired output of the perceptron,
, multiplied by the desired output of the perceptron, 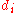 , must be greater than the positive constant,
, must be greater than the positive constant, 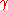 , for all input-vector/output-value pairs
, for all input-vector/output-value pairs 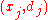 in
in 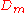 .
.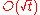 where t is the number of changes to the weight vector. But it can also be bounded below by
where t is the number of changes to the weight vector. But it can also be bounded below by 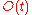 because if there exists an (unknown) satisfactory weight vector, then every change makes progress in this (unknown) direction by a positive amount that depends only on the input vector.
because if there exists an (unknown) satisfactory weight vector, then every change makes progress in this (unknown) direction by a positive amount that depends only on the input vector. of updates to the weight vector is bounded by
of updates to the weight vector is bounded by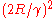 , where
, where  is the maximum norm of an input vector.
is the maximum norm of an input vector. and learning rate
and learning rate  is an identical estimator to a perceptron trained with initial weight vector
is an identical estimator to a perceptron trained with initial weight vector  and learning rate 1. Thus, since the initial weights become irrelevant with increasing number of iterations, the learning rate does not matter in the case of the perceptron and is usually just set to one.
and learning rate 1. Thus, since the initial weights become irrelevant with increasing number of iterations, the learning rate does not matter in the case of the perceptron and is usually just set to one. -perceptron further utilised a preprocessing layer of fixed random weights, with thresholded output units. This enabled the perceptron to classify analogue patterns, by projecting them into a binary space. In fact, for a projection space of sufficiently high dimension, patterns can become linearly separable.
-perceptron further utilised a preprocessing layer of fixed random weights, with thresholded output units. This enabled the perceptron to classify analogue patterns, by projecting them into a binary space. In fact, for a projection space of sufficiently high dimension, patterns can become linearly separable.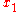 and
and 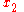 .
. ,
, 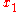 ,
, 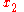 , with input
, with input  held constant at 1.
held constant at 1.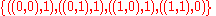
 and the output
and the output  are drawn from arbitrary sets. A feature representation function
are drawn from arbitrary sets. A feature representation function 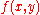 maps each possible input/output pair to a finite-dimensional real-valued feature vector. As before, the feature vector is multiplied by a weight vector
maps each possible input/output pair to a finite-dimensional real-valued feature vector. As before, the feature vector is multiplied by a weight vector  , but now the resulting score is used to choose among many possible outputs:
, but now the resulting score is used to choose among many possible outputs: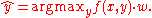
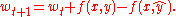
 is a real-valued vector,
is a real-valued vector,  is chosen from
is chosen from 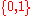 , and
, and 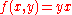 .
.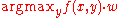 can be found efficiently even though
can be found efficiently even though 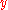 is chosen from a very large or even infinite set.
is chosen from a very large or even infinite set.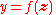 denotes the output from the perceptron for an input vector
denotes the output from the perceptron for an input vector  .
. is the bias term, which in the example below we take to be 0.
is the bias term, which in the example below we take to be 0.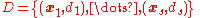 is the training set of
is the training set of  samples, where:
samples, where:
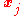 is the
is the  -dimensional input vector.
-dimensional input vector. is the desired output value of the perceptron for that input.
is the desired output value of the perceptron for that input.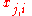 is the value of the
is the value of the 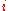 th node of the
th node of the 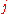 th training input vector.
th training input vector. .
.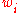 is the
is the 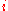 th value in the weight vector, to be multiplied by the value of the
th value in the weight vector, to be multiplied by the value of the 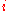 th input node.
th input node.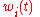 is the weight
is the weight 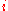 at time
at time  .
. is the learning rate, where
is the learning rate, where  .
.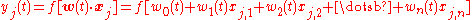
 , for all nodes
, for all nodes 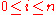 .
.