

Multilayer perceptron
Encyclopedia
A multilayer perceptron is a feedforward artificial neural network
model that maps sets of input data onto a set of appropriate output. An MLP consists of multiple layers of nodes in a directed graph, with each layer fully connected to the next one. Except for the input nodes, each node is a neuron (or processing element) with a nonlinear activation function
. MLP utilizes a supervised learning
technique called backpropagation
for training the network. MLP is a modification of the standard linear perceptron
, which can distinguish data that is not linearly separable.
in all neurons, that is, a simple on-off mechanism to determine whether or not a neuron fires, then it is easily proved with linear algebra
that any number of layers can be reduced to the standard two-layer input-output model (see perceptron
). What makes a multilayer perceptron different is that each neuron uses a nonlinear activation function which was developed to model the frequency of action potentials, or firing, of biological neurons in the brain. This function is modeled in several ways, but must always be normalizable
and differentiable
.
The two main activation functions used in current applications are both sigmoids, and are described by
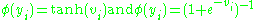 ,
,
in which the former function is a hyperbolic tangent which ranges from -1 to 1, and the latter, the logistic function
, is similar in shape but ranges from 0 to 1. Here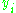 is the output of the
is the output of the 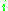 th node (neuron) and
th node (neuron) and 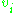 is the weighted sum of the input synapses. More specialized activation functions include radial basis functions which are used in another class of supervised neural network models.
is the weighted sum of the input synapses. More specialized activation functions include radial basis functions which are used in another class of supervised neural network models.
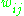 to every node in the following layer.
to every node in the following layer.
, and is carried out through backpropagation
, a generalization of the least mean squares algorithm in the linear perceptron.
We represent the error in output node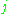 in the
in the  th data point by
th data point by 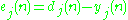 , where
, where 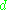 is the target value and
is the target value and 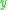 is the value produced by the perceptron. We then make corrections to the weights of the nodes based on those corrections which minimize the error in the entire output, given by
is the value produced by the perceptron. We then make corrections to the weights of the nodes based on those corrections which minimize the error in the entire output, given by
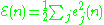 .
.
Using gradient descent
, we find our change in each weight to be
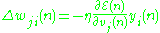
where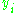 is the output of the previous neuron and
is the output of the previous neuron and 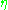 is the learning rate, which is carefully selected to ensure that the weights converge to a response fast enough, without producing oscillations. In programming applications, this parameter typically ranges from 0.2 to 0.8.
is the learning rate, which is carefully selected to ensure that the weights converge to a response fast enough, without producing oscillations. In programming applications, this parameter typically ranges from 0.2 to 0.8.
The derivative to be calculated depends on the induced local field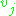 , which itself varies. It is easy to prove that for an output node this derivative can be simplified to
, which itself varies. It is easy to prove that for an output node this derivative can be simplified to
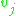
where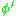 is the derivative of the activation function described above, which itself does not vary. The analysis is more difficult for the change in weights to a hidden node, but it can be shown that the relevant derivative is
is the derivative of the activation function described above, which itself does not vary. The analysis is more difficult for the change in weights to a hidden node, but it can be shown that the relevant derivative is
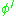 .
.
This depends on the change in weights of the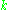 th nodes, which represent the output layer. So to change the hidden layer weights, we must first change the output layer weights according to the derivative of the activation function, and so this algorithm represents a backpropagation of the activation function.
th nodes, which represent the output layer. So to change the hidden layer weights, we must first change the output layer weights according to the derivative of the activation function, and so this algorithm represents a backpropagation of the activation function.
and parallel distributed processing. They are useful in research in terms of their ability to solve problems stochastically, which often allows one to get approximate solutions for extremely complex
problems like fitness approximation
.
Currently, they are most commonly seen in speech recognition
, image recognition, and machine translation
software, but they have also seen applications in other fields such as cyber security. In general, their most important use has been in the growing field of artificial intelligence
, although the multilayer perceptron does not have connections with biological neural networks as initial neural based networks have.
Artificial neural network
An artificial neural network , usually called neural network , is a mathematical model or computational model that is inspired by the structure and/or functional aspects of biological neural networks. A neural network consists of an interconnected group of artificial neurons, and it processes...
model that maps sets of input data onto a set of appropriate output. An MLP consists of multiple layers of nodes in a directed graph, with each layer fully connected to the next one. Except for the input nodes, each node is a neuron (or processing element) with a nonlinear activation function
Activation function
In computational networks, the activation function of a node defines the output of that node given an input or set of inputs. A standard computer chip circuit can be seen as a digital network of activation functions that can be "ON" or "OFF" , depending on input. This is similar to the behavior of...
. MLP utilizes a supervised learning
Supervised learning
Supervised learning is the machine learning task of inferring a function from supervised training data. The training data consist of a set of training examples. In supervised learning, each example is a pair consisting of an input object and a desired output value...
technique called backpropagation
Backpropagation
Backpropagation is a common method of teaching artificial neural networks how to perform a given task. Arthur E. Bryson and Yu-Chi Ho described it as a multi-stage dynamic system optimization method in 1969 . It wasn't until 1974 and later, when applied in the context of neural networks and...
for training the network. MLP is a modification of the standard linear perceptron
Perceptron
The perceptron is a type of artificial neural network invented in 1957 at the Cornell Aeronautical Laboratory by Frank Rosenblatt. It can be seen as the simplest kind of feedforward neural network: a linear classifier.- Definition :...
, which can distinguish data that is not linearly separable.
Activation function
If a multilayer perceptron has a linear activation functionActivation function
In computational networks, the activation function of a node defines the output of that node given an input or set of inputs. A standard computer chip circuit can be seen as a digital network of activation functions that can be "ON" or "OFF" , depending on input. This is similar to the behavior of...
in all neurons, that is, a simple on-off mechanism to determine whether or not a neuron fires, then it is easily proved with linear algebra
Linear algebra
Linear algebra is a branch of mathematics that studies vector spaces, also called linear spaces, along with linear functions that input one vector and output another. Such functions are called linear maps and can be represented by matrices if a basis is given. Thus matrix theory is often...
that any number of layers can be reduced to the standard two-layer input-output model (see perceptron
Perceptron
The perceptron is a type of artificial neural network invented in 1957 at the Cornell Aeronautical Laboratory by Frank Rosenblatt. It can be seen as the simplest kind of feedforward neural network: a linear classifier.- Definition :...
). What makes a multilayer perceptron different is that each neuron uses a nonlinear activation function which was developed to model the frequency of action potentials, or firing, of biological neurons in the brain. This function is modeled in several ways, but must always be normalizable
Normalization
Normalization may refer to:- Mathematics and statistics:* Normalization property , term in mathematical logic and theoretical computer science* Noether normalization lemma, result of commutative algebra...
and differentiable
Differentiable function
In calculus , a differentiable function is a function whose derivative exists at each point in its domain. The graph of a differentiable function must have a non-vertical tangent line at each point in its domain...
.
The two main activation functions used in current applications are both sigmoids, and are described by
,in which the former function is a hyperbolic tangent which ranges from -1 to 1, and the latter, the logistic function
Logistic function
A logistic function or logistic curve is a common sigmoid curve, given its name in 1844 or 1845 by Pierre François Verhulst who studied it in relation to population growth. It can model the "S-shaped" curve of growth of some population P...
, is similar in shape but ranges from 0 to 1. Here
is the output of the th node (neuron) and is the weighted sum of the input synapses. More specialized activation functions include radial basis functions which are used in another class of supervised neural network models.Layers
The multilayer perceptron consists of three or more layers (an input and an output layer with one or more hidden layers) of nonlinearly-activating nodes. Each node in one layer connects with a certain weight to every node in the following layer.Learning through backpropagation
Learning occurs in the perceptron by changing connection weights after each piece of data is processed, based on the amount of error in the output compared to the expected result. This is an example of supervised learningSupervised learning
Supervised learning is the machine learning task of inferring a function from supervised training data. The training data consist of a set of training examples. In supervised learning, each example is a pair consisting of an input object and a desired output value...
, and is carried out through backpropagation
Backpropagation
Backpropagation is a common method of teaching artificial neural networks how to perform a given task. Arthur E. Bryson and Yu-Chi Ho described it as a multi-stage dynamic system optimization method in 1969 . It wasn't until 1974 and later, when applied in the context of neural networks and...
, a generalization of the least mean squares algorithm in the linear perceptron.
We represent the error in output node
in the th data point by , where is the target value and is the value produced by the perceptron. We then make corrections to the weights of the nodes based on those corrections which minimize the error in the entire output, given by.Using gradient descent
Gradient descent
Gradient descent is a first-order optimization algorithm. To find a local minimum of a function using gradient descent, one takes steps proportional to the negative of the gradient of the function at the current point...
, we find our change in each weight to be
where
is the output of the previous neuron and is the learning rate, which is carefully selected to ensure that the weights converge to a response fast enough, without producing oscillations. In programming applications, this parameter typically ranges from 0.2 to 0.8.The derivative to be calculated depends on the induced local field
, which itself varies. It is easy to prove that for an output node this derivative can be simplified towhere
is the derivative of the activation function described above, which itself does not vary. The analysis is more difficult for the change in weights to a hidden node, but it can be shown that the relevant derivative is.This depends on the change in weights of the
th nodes, which represent the output layer. So to change the hidden layer weights, we must first change the output layer weights according to the derivative of the activation function, and so this algorithm represents a backpropagation of the activation function. Applications
Multilayer perceptrons using a backpropagation algorithm are the standard algorithm for any supervised-learning pattern recognition process and the subject of ongoing research in computational neuroscienceComputational neuroscience
Computational neuroscience is the study of brain function in terms of the information processing properties of the structures that make up the nervous system...
and parallel distributed processing. They are useful in research in terms of their ability to solve problems stochastically, which often allows one to get approximate solutions for extremely complex
Computational complexity theory
Computational complexity theory is a branch of the theory of computation in theoretical computer science and mathematics that focuses on classifying computational problems according to their inherent difficulty, and relating those classes to each other...
problems like fitness approximation
Fitness approximation
In function optimization, fitness approximation is a method for decreasing the number of fitness function evaluations to reach a target solution...
.
Currently, they are most commonly seen in speech recognition
Speech recognition
Speech recognition converts spoken words to text. The term "voice recognition" is sometimes used to refer to recognition systems that must be trained to a particular speaker—as is the case for most desktop recognition software...
, image recognition, and machine translation
Machine translation
Machine translation, sometimes referred to by the abbreviation MT is a sub-field of computational linguistics that investigates the use of computer software to translate text or speech from one natural language to another.On a basic...
software, but they have also seen applications in other fields such as cyber security. In general, their most important use has been in the growing field of artificial intelligence
Artificial intelligence
Artificial intelligence is the intelligence of machines and the branch of computer science that aims to create it. AI textbooks define the field as "the study and design of intelligent agents" where an intelligent agent is a system that perceives its environment and takes actions that maximize its...
, although the multilayer perceptron does not have connections with biological neural networks as initial neural based networks have.