
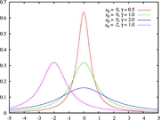
Cauchy distribution
Overview
Hendrik Lorentz
Hendrik Antoon Lorentz was a Dutch physicist who shared the 1902 Nobel Prize in Physics with Pieter Zeeman for the discovery and theoretical explanation of the Zeeman effect...
, is a continuous probability distribution
Probability distribution
In probability theory, a probability mass, probability density, or probability distribution is a function that describes the probability of a random variable taking certain values....
. As a probability distribution, it is known as the Cauchy distribution, while among physicists, it is known as the Lorentz distribution, Lorentz(ian) function, or Breit–Wigner distribution.
Its importance in physics
Physics
Physics is a natural science that involves the study of matter and its motion through spacetime, along with related concepts such as energy and force. More broadly, it is the general analysis of nature, conducted in order to understand how the universe behaves.Physics is one of the oldest academic...
is the result of its being the solution to the differential equation
Differential equation
A differential equation is a mathematical equation for an unknown function of one or several variables that relates the values of the function itself and its derivatives of various orders...
describing forced resonance.
Unanswered Questions