

Statistical machine translation
Encyclopedia
Statistical machine translation (SMT) is a machine translation
paradigm
where translations are generated on the basis of statistical models whose parameters are derived from the analysis of bilingual text corpora. The statistical approach contrasts with the rule-based approaches to machine translation
as well as with example-based machine translation
.
The first ideas of statistical machine translation were introduced by Warren Weaver
in 1949, including the ideas of applying Claude Shannon's information theory
. Statistical machine translation was re-introduced in 1991 by researchers at IBM
's Thomas J. Watson Research Center
and has contributed to the significant resurgence in interest in machine translation in recent years. Nowadays it is by far the most widely-studied machine translation method.
. A document is translated according to the probability distribution
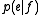 that a string
that a string  in the target language (for example, English) is the translation of a string
in the target language (for example, English) is the translation of a string 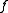 in the source language (for example, French).
in the source language (for example, French).
The problem of modeling the probability distribution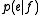 has been approached in a number of ways. One intuitive approach is to apply Bayes Theorem, that is
has been approached in a number of ways. One intuitive approach is to apply Bayes Theorem, that is 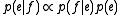 , where the translation model
, where the translation model 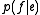 is the probability that the source string is the translation of the target string, and the language model
is the probability that the source string is the translation of the target string, and the language model
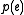 is the probability of seeing that target language string. This decomposition is attractive as it splits the problem into two subproblems. Finding the best translation
is the probability of seeing that target language string. This decomposition is attractive as it splits the problem into two subproblems. Finding the best translation 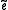 is done by picking up the one that gives the highest probability:
is done by picking up the one that gives the highest probability: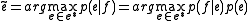 .
.
For a rigorous implementation of this one would have to perform an exhaustive search by going through all strings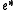 in the native language. Performing the search efficiently is the work of a machine translation decoder that uses the foreign string, heuristics and other methods to limit the search space and at the same time keeping acceptable quality. This trade-off between quality and time usage can also be found in speech recognition
in the native language. Performing the search efficiently is the work of a machine translation decoder that uses the foreign string, heuristics and other methods to limit the search space and at the same time keeping acceptable quality. This trade-off between quality and time usage can also be found in speech recognition
.
As the translation systems are not able to store all native strings and their translations, a document is typically translated sentence by sentence, but even this is not enough. Language models are typically approximated by smoothed n-gram models, and similar approaches have been applied to translation models, but there is additional complexity due to different sentence lengths and word orders in the languages.
The statistical translation models were initially word
based (Models 1-5 from IBM
Hidden Markov model
from Stephan Vogel and Model 6 from Franz-Joseph Och), but significant advances were made with the introduction of phrase
based models. Recent work has incorporated syntax
or quasi-syntactic structures.
Simple word-based translation can't translate between languages with different fertility. Word-based translation systems can relatively simply be made to cope with high fertility, but they could map a single word to multiple words, but not the other way about. For example, if we were translating from French to English, each word in English could produce any number of French words— sometimes none at all. But there's no way to group two English words producing a single French word.
An example of a word-based translation system is the freely available GIZA++ package (GPLed), which includes the training program for IBM
models and HMM model and Model 6.
The word-based translation is not widely used today; phrase-based systems are more common. Most phrase-based system are still using GIZA++ to align the corpus. The alignments are used to extract phrases or deduce syntax rules. And matching words in bi-text is still a problem actively discussed in the community. Because of the predominance of GIZA++, there are now several distributed implementations of it online.
s but phrases found using statistical methods from corpora. It has been shown that restricting the phrases to linguistic phrases (syntactically motivated groups of words, see syntactic categories) decreases the quality of translation
s of sentences/utterances. The idea of syntax-based translation is quite old in MT, though its statistical counterpart did not take off until the advent of strong stochastic parsers in the 1990s. Examples of this approach include DOP
-based MT and, more recently, synchronous context-free grammar
s.
.
In speech recognition
, the speech signal and the corresponding textual representation can be mapped to each other in blocks in order. This is not always the case with the same text in two languages. For SMT, the machine translator can only manage small sequences of words, and word order has to be thought of by the program designer. Attempts at solutions have included re-ordering models, where a distribution of location changes for each item of translation is guessed from aligned bi-text. Different location changes can be ranked with the help of the language model and the best can be selected.
or phrases that were not in the training data cannot be translated. This might be because of the lack of training data, changes in the human domain where the system is used, or differences in morphology.
Machine translation
Machine translation, sometimes referred to by the abbreviation MT is a sub-field of computational linguistics that investigates the use of computer software to translate text or speech from one natural language to another.On a basic...
paradigm
Paradigm
The word paradigm has been used in science to describe distinct concepts. It comes from Greek "παράδειγμα" , "pattern, example, sample" from the verb "παραδείκνυμι" , "exhibit, represent, expose" and that from "παρά" , "beside, beyond" + "δείκνυμι" , "to show, to point out".The original Greek...
where translations are generated on the basis of statistical models whose parameters are derived from the analysis of bilingual text corpora. The statistical approach contrasts with the rule-based approaches to machine translation
Machine translation
Machine translation, sometimes referred to by the abbreviation MT is a sub-field of computational linguistics that investigates the use of computer software to translate text or speech from one natural language to another.On a basic...
as well as with example-based machine translation
Example-based machine translation
The example-based machine translation approach to machine translation is often characterized by its use of a bilingual corpus with parallel texts as its main knowledge base, at run-time...
.
The first ideas of statistical machine translation were introduced by Warren Weaver
Warren Weaver
Warren Weaver was an American scientist, mathematician, and science administrator...
in 1949, including the ideas of applying Claude Shannon's information theory
Information theory
Information theory is a branch of applied mathematics and electrical engineering involving the quantification of information. Information theory was developed by Claude E. Shannon to find fundamental limits on signal processing operations such as compressing data and on reliably storing and...
. Statistical machine translation was re-introduced in 1991 by researchers at IBM
IBM
International Business Machines Corporation or IBM is an American multinational technology and consulting corporation headquartered in Armonk, New York, United States. IBM manufactures and sells computer hardware and software, and it offers infrastructure, hosting and consulting services in areas...
's Thomas J. Watson Research Center
Thomas J. Watson Research Center
The Thomas J. Watson Research Center is the headquarters for the IBM Research Division.The center is on three sites, with the main laboratory in Yorktown Heights, New York, 38 miles north of New York City, a building in Hawthorne, New York, and offices in Cambridge, Massachusetts.- Overview :The...
and has contributed to the significant resurgence in interest in machine translation in recent years. Nowadays it is by far the most widely-studied machine translation method.
Basis
The idea behind statistical machine translation comes from information theoryInformation theory
Information theory is a branch of applied mathematics and electrical engineering involving the quantification of information. Information theory was developed by Claude E. Shannon to find fundamental limits on signal processing operations such as compressing data and on reliably storing and...
. A document is translated according to the probability distribution
Probability distribution
In probability theory, a probability mass, probability density, or probability distribution is a function that describes the probability of a random variable taking certain values....
that a string in the target language (for example, English) is the translation of a string in the source language (for example, French).The problem of modeling the probability distribution
has been approached in a number of ways. One intuitive approach is to apply Bayes Theorem, that is , where the translation model is the probability that the source string is the translation of the target string, and the language modelLanguage model
A statistical language model assigns a probability to a sequence of m words P by means of a probability distribution.Language modeling is used in many natural language processing applications such as speech recognition, machine translation, part-of-speech tagging, parsing and information...
is the probability of seeing that target language string. This decomposition is attractive as it splits the problem into two subproblems. Finding the best translation is done by picking up the one that gives the highest probability:.For a rigorous implementation of this one would have to perform an exhaustive search by going through all strings
in the native language. Performing the search efficiently is the work of a machine translation decoder that uses the foreign string, heuristics and other methods to limit the search space and at the same time keeping acceptable quality. This trade-off between quality and time usage can also be found in speech recognitionSpeech recognition
Speech recognition converts spoken words to text. The term "voice recognition" is sometimes used to refer to recognition systems that must be trained to a particular speaker—as is the case for most desktop recognition software...
.
As the translation systems are not able to store all native strings and their translations, a document is typically translated sentence by sentence, but even this is not enough. Language models are typically approximated by smoothed n-gram models, and similar approaches have been applied to translation models, but there is additional complexity due to different sentence lengths and word orders in the languages.
The statistical translation models were initially word
Word
In language, a word is the smallest free form that may be uttered in isolation with semantic or pragmatic content . This contrasts with a morpheme, which is the smallest unit of meaning but will not necessarily stand on its own...
based (Models 1-5 from IBM
IBM
International Business Machines Corporation or IBM is an American multinational technology and consulting corporation headquartered in Armonk, New York, United States. IBM manufactures and sells computer hardware and software, and it offers infrastructure, hosting and consulting services in areas...
Hidden Markov model
Hidden Markov model
A hidden Markov model is a statistical Markov model in which the system being modeled is assumed to be a Markov process with unobserved states. An HMM can be considered as the simplest dynamic Bayesian network. The mathematics behind the HMM was developed by L. E...
from Stephan Vogel and Model 6 from Franz-Joseph Och), but significant advances were made with the introduction of phrase
Phrase
In everyday speech, a phrase may refer to any group of words. In linguistics, a phrase is a group of words which form a constituent and so function as a single unit in the syntax of a sentence. A phrase is lower on the grammatical hierarchy than a clause....
based models. Recent work has incorporated syntax
Syntax
In linguistics, syntax is the study of the principles and rules for constructing phrases and sentences in natural languages....
or quasi-syntactic structures.
Benefits
The most frequently cited benefits of statistical machine translation over traditional paradigms are:- Better use of resources
- There is a great deal of natural language in machine-readable format.
- Generally, SMT systems are not tailored to any specific pair of languages.
- Rule-based translation systems require the manual development of linguistic rules, which can be costly, and which often do not generalize to other languages.
- More natural translations
- Rule-based translation systems are likely to result in Literal translation. While it appears that SMT should avoid this problem and result in natural translations, this is negated by the fact that using statistical matching to translate rather than a dictionary/grammar rules approach can often result in text that include apparently nonsensical and obvious errors.
Word-based translation
In word-based translation, the fundamental unit of translation is a word in some natural language. Typically, the number of words in translated sentences are different, because of compound words, morphology and idioms. The ratio of the lengths of sequences of translated words is called fertility, which tells how many foreign words each native word produces. Necessarily it is assumed by information theory that each covers the same concept. In practice this is not really true. For example, the English word corner can be translated in Spanish by either rincón or esquina, depending on whether it is to mean its internal or external angle.Simple word-based translation can't translate between languages with different fertility. Word-based translation systems can relatively simply be made to cope with high fertility, but they could map a single word to multiple words, but not the other way about. For example, if we were translating from French to English, each word in English could produce any number of French words— sometimes none at all. But there's no way to group two English words producing a single French word.
An example of a word-based translation system is the freely available GIZA++ package (GPLed), which includes the training program for IBM
IBM
International Business Machines Corporation or IBM is an American multinational technology and consulting corporation headquartered in Armonk, New York, United States. IBM manufactures and sells computer hardware and software, and it offers infrastructure, hosting and consulting services in areas...
models and HMM model and Model 6.
The word-based translation is not widely used today; phrase-based systems are more common. Most phrase-based system are still using GIZA++ to align the corpus. The alignments are used to extract phrases or deduce syntax rules. And matching words in bi-text is still a problem actively discussed in the community. Because of the predominance of GIZA++, there are now several distributed implementations of it online.
Phrase-based translation
In phrase-based translation, the aim is to reduce the restrictions of word-based translation by translating whole sequences of words, where the lengths may differ. The sequences of words are called blocks or phrases, but typically are not linguistic phrasePhrase
In everyday speech, a phrase may refer to any group of words. In linguistics, a phrase is a group of words which form a constituent and so function as a single unit in the syntax of a sentence. A phrase is lower on the grammatical hierarchy than a clause....
s but phrases found using statistical methods from corpora. It has been shown that restricting the phrases to linguistic phrases (syntactically motivated groups of words, see syntactic categories) decreases the quality of translation
Syntax-based translation
Syntax-based translation is based on the idea of translating syntactic units, rather than single words or strings of words (as in phrase-based MT), i.e. (partial) parse treeParse tree
A concrete syntax tree or parse tree or parsing treeis an ordered, rooted tree that represents the syntactic structure of a string according to some formal grammar. In a parse tree, the interior nodes are labeled by non-terminals of the grammar, while the leaf nodes are labeled by terminals of the...
s of sentences/utterances. The idea of syntax-based translation is quite old in MT, though its statistical counterpart did not take off until the advent of strong stochastic parsers in the 1990s. Examples of this approach include DOP
Data-oriented parsing
Data-oriented parsing is a probabilistic grammar formalism in computational linguistics. DOP was conceived by Remko Scha in 1990 with the aim of developing a performance-oriented grammar framework...
-based MT and, more recently, synchronous context-free grammar
Synchronous context-free grammar
Synchronous context-free grammars Synchronous context-free grammars Synchronous context-free grammars (SynCFG or SCFG; not to be confused with stochastic CFGs constitute a formal model of natural language syntax, developed in the area of statistical machine translation (MT)....
s.
Challenges with statistical machine translation
Problems that statistical machine translation have to deal with includeSentence alignment
In parallel corpora single sentences in one language can be found translated into several sentences in the other and vice versa. Sentence aligning can be performed through the Gale-Church alignment algorithmGale-Church alignment algorithm
In computational linguistics, the Gale–Church algorithm is a method for aligning corresponding sentences in a parallel corpus. It works on the principle that equivalent sentences should roughly correspond in length—that is, longer sentences in one language should correspond to longer...
.
Idioms
Depending on the corpora used, idioms may not translate "idiomatically". For example, using Canadian Hansard as the bilingual corpus, "hear" may almost invariably be translated to "Bravo!" since in Parliament "Hear, Hear!" becomes "Bravo!".Different word orders
Word order in languages differ. Some classification can be done by naming the typical order of subject (S), verb (V) and object (O) in a sentence and one can talk, for instance, of SVO or VSO languages. There are also additional differences in word orders, for instance, where modifiers for nouns are located, or where the same words are used as a question or a statement.In speech recognition
Speech recognition
Speech recognition converts spoken words to text. The term "voice recognition" is sometimes used to refer to recognition systems that must be trained to a particular speaker—as is the case for most desktop recognition software...
, the speech signal and the corresponding textual representation can be mapped to each other in blocks in order. This is not always the case with the same text in two languages. For SMT, the machine translator can only manage small sequences of words, and word order has to be thought of by the program designer. Attempts at solutions have included re-ordering models, where a distribution of location changes for each item of translation is guessed from aligned bi-text. Different location changes can be ranked with the help of the language model and the best can be selected.
Out of vocabulary (OOV) words
SMT systems store different word forms as separate symbols without any relation to each other and word formsor phrases that were not in the training data cannot be translated. This might be because of the lack of training data, changes in the human domain where the system is used, or differences in morphology.
See also
- AppTekApptekApplications Technology is a U.S. software company specializing in human language technology, headquartered in McLean, Virginia.AppTek's primary focus is on machine translation and automatic speech recognition...
- Asia OnlineAsia OnlineAsia Online is a privately owned company backed by individual investors and institutional venture capital. Its corporate headquarters are in Singapore, and it has significant operations in Bangkok, Thailand, with R&D activities throughout Asia and expanding sales operations in Europe and North...
- Cache language modelCache language modelA cache language model is a type of statistical language model. These occur in the natural language processing subfield of computer science and assign probabilities to given sequences of words by means of a probability distribution...
- Example-based machine translationExample-based machine translationThe example-based machine translation approach to machine translation is often characterized by its use of a bilingual corpus with parallel texts as its main knowledge base, at run-time...
- Google TranslateGoogle TranslateGoogle Translate is a free statistical machine translation service provided by Google Inc. to translate a section of text, document or webpage, into another language.The service was introduced in April 28, 2006 for the Arabic language...
- SDL Language WeaverLanguage WeaverSDL Language Weaver is a Los Angeles, California–based company that was founded in 2002 by the University of Southern California's Kevin Knight and Daniel Marcu, to commercialize a statistical approach to automatic language translation and natural language processing - now known globally as...
- Machine translationMachine translationMachine translation, sometimes referred to by the abbreviation MT is a sub-field of computational linguistics that investigates the use of computer software to translate text or speech from one natural language to another.On a basic...
External links
- Statistical Machine Translation — includes introduction to research, conference, corpus and software listings.
- Moses: a state-of-the-art open source SMT system
- Annotated list of statistical natural language processing resources — Includes links to freely available statistical machine translation software.
- GIZA++: Word Alignment Tool
- MGIZA++/PGIZA++ Parallel Implementations of GIZA++
- Cunei — an open source platform for data-driven machine translation that combines the approaches of SMTSMTSMT may refer to:* Satisfiability Modulo Theories* Statistical machine translation* Scottish Mortgage Investment Trust PLC * Scottish Motor Traction, a former bus company in Scotland...
and EBMT - Thot — a toolkit to train phrase-based models for statistical machine translation]
- SiShiTra — A hybrid machine translation engine for Spanish-Catalan translation]
- GREAT — Giati and Refx Enhanced via Annotation Techniques]