

Polyphase merge sort
Encyclopedia
A polyphase merge sort is an algorithm which decreases the number of runs at every iteration of the main loop by merging runs into larger runs. It is used for external sorting.
splits items into sorted runs and then recursively merges each run into larger runs. When there's only one run left, that is the sorted result.
An ordinary merge sort could use four working files organized as a pair of input files and a pair of output files. At each iteration, two input files are read. The odd numbered runs of the two input files are merged to the first output file, and the even numbered runs are merged to the second output file. When the input is exhausted, the new output files are used as the input for the next iteration. The number of runs decreases by a factor of 2 at each iteration. At each iteration, the same level/phase of merge occurs -- a file is either completely read or completely written during an iteration.
If the four files were on four separate tape drives
, watching an ordinary merge sort would show some interesting details. On the first iteration, only one input drive is used -- the other input file is empty. On subsequent iterations, each input drive runs at half speed, while one output drive runs at full speed and the second output drive stands idle waiting for the next run. The situation is even worse when six tape drives are used -- at least two will stand idle. Someone watching the tapes spin would wonder if the idle drives could be more useful.
The polyphase merge found a way to use the idle drives. It can sort using just three sequential files rather than the four required by merge sort.
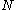 files, but the polyphase merge will read from
files, but the polyphase merge will read from 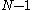 files and write only one output file at a time. The writing to that output file continues until an input file is exhausted, and then that input file becomes the new output file. The number of runs in each file is related to Fibonacci numbers
files and write only one output file at a time. The writing to that output file continues until an input file is exhausted, and then that input file becomes the new output file. The number of runs in each file is related to Fibonacci numbers
and Fibonacci numbers of higher order
.
File 1 just emptied and became the new output file. One run is left on each input tape, and merging those runs together will make the sorted file.
Stepping back to the previous iteration, we were reading from 1 and 2. One run is merged from 1 and 2 before file 1 goes empty. Notice that file 2 is not completely consumed -- it has one run left to match the final merge (above).
Stepping back another iteration, 2 runs are merged from 1 and 3 before file 3 goes empty.
Stepping back another iteration, 3 runs are merged from 2 and 3 before file 2 goes empty.
Stepping back another iteration, 5 runs are merged from 1 and 2 before file 1 goes empty.
Looking at the number of runs merged working backwards: 1, 1, 2, 3, 5, ... reveals a Fibonacci sequence.
For everything to work out right, the initial file to be sorted must be distributed to the proper input files and each input file must have the correct number of runs on it. In the example, that would mean an input file with 13 runs would write 5 runs to file 1 and 8 runs to file 2.
In practice, the input file won't happen to have a Fibonacci number of runs it (and the number of runs won't be known until after the file has been read). The fix is to pad the input files with dummy runs to make the required Fibonacci sequence.
For comparison, the ordinary merge sort will combine 16 runs in 4 passes using 4 files. The polyphase merge will combine 13 runs in 5 passes using only 3 files. Alternatively, a polyphase merge will combine 17 runs in 4 passes using 4 files. (Sequence: 1, 1, 1, 3, 5, 9, 17, 31, 57, ...)
An iteration (or pass) in ordinary merge sort involves reading and writing the entire file. An iteration in a polyphase sort does not read or write the entire file, so a typical polyphase iteration will take less time than a merge sort iteration.
Ordinary merge sort
Typically, a merge sortMerge sort
Merge sort is an O comparison-based sorting algorithm. Most implementations produce a stable sort, meaning that the implementation preserves the input order of equal elements in the sorted output. It is a divide and conquer algorithm...
splits items into sorted runs and then recursively merges each run into larger runs. When there's only one run left, that is the sorted result.
An ordinary merge sort could use four working files organized as a pair of input files and a pair of output files. At each iteration, two input files are read. The odd numbered runs of the two input files are merged to the first output file, and the even numbered runs are merged to the second output file. When the input is exhausted, the new output files are used as the input for the next iteration. The number of runs decreases by a factor of 2 at each iteration. At each iteration, the same level/phase of merge occurs -- a file is either completely read or completely written during an iteration.
If the four files were on four separate tape drives
Tape drive
A tape drive is a data storage device that reads and performs digital recording, writes data on a magnetic tape. Magnetic tape data storage is typically used for offline, archival data storage. Tape media generally has a favorable unit cost and long archival stability.A tape drive provides...
, watching an ordinary merge sort would show some interesting details. On the first iteration, only one input drive is used -- the other input file is empty. On subsequent iterations, each input drive runs at half speed, while one output drive runs at full speed and the second output drive stands idle waiting for the next run. The situation is even worse when six tape drives are used -- at least two will stand idle. Someone watching the tapes spin would wonder if the idle drives could be more useful.
The polyphase merge found a way to use the idle drives. It can sort using just three sequential files rather than the four required by merge sort.
Polyphase merge
The polyphase merge changes the game. There might be files, but the polyphase merge will read from files and write only one output file at a time. The writing to that output file continues until an input file is exhausted, and then that input file becomes the new output file. The number of runs in each file is related to Fibonacci numbersFibonacci number
In mathematics, the Fibonacci numbers are the numbers in the following integer sequence:0,\;1,\;1,\;2,\;3,\;5,\;8,\;13,\;21,\;34,\;55,\;89,\;144,\; \ldots\; ....
and Fibonacci numbers of higher order
Generalizations of Fibonacci numbers
In mathematics, the Fibonacci numbers form a sequence defined recursively by:The Fibonacci sequence has been studied extensively and generalized in many ways, for example, by starting with other numbers than 0 and 1, by adding more than two numbers to generate the next number, or by adding objects...
.
Perfect 3 file polyphase merge sort
It is easiest to look at the polyphase merge starting from its ending conditions and working backwards. At the start of each iteration, there will be two input files and one output file. At the end of the iteration, one input file will have been completely consumed and will become the output file for the next iteration. The current output file will become an input file for the next iteration. The remaining files (just one in the 3 file case) have only been partially consumed and their remaining runs will be input for the next iteration.File 1 just emptied and became the new output file. One run is left on each input tape, and merging those runs together will make the sorted file.
File 1 (out): <1 run> * (the sorted file)
File 2 (in ): ... | <1 run> * --> ... <1 run> | * (consumed)
File 3 (in ): | <1 run> * <1 run> | * (consumed)
... possible runs that have already been read
| marks the read pointer of the file
- marks end of file
Stepping back to the previous iteration, we were reading from 1 and 2. One run is merged from 1 and 2 before file 1 goes empty. Notice that file 2 is not completely consumed -- it has one run left to match the final merge (above).
File 1 (in ): ... | <1 run> * ... <1 run> | *
File 2 (in ): | <2 run> * --> <1 run> | <1 run> *
File 3 (out): <1 run> *
Stepping back another iteration, 2 runs are merged from 1 and 3 before file 3 goes empty.
File 1 (in ): | <3 run> ... <2 run> | <1 run> *
File 2 (out): --> <2 run> *
File 3 (in ): ... | <2 run> * <2 run> | *
Stepping back another iteration, 3 runs are merged from 2 and 3 before file 2 goes empty.
File 1 (out): <3 run> *
File 2 (in ): ... | <3 run> * --> ... <3 run> | *
File 3 (in ): | <5 run> * <3 run> | <2 run> *
Stepping back another iteration, 5 runs are merged from 1 and 2 before file 1 goes empty.
File 1 (in ): ... | <5 run> * ... <5 run> | *
File 2 (in ): | <8 run> * --> <5 run> | <3 run> *
File 3 (out): <5 run> *
Looking at the number of runs merged working backwards: 1, 1, 2, 3, 5, ... reveals a Fibonacci sequence.
For everything to work out right, the initial file to be sorted must be distributed to the proper input files and each input file must have the correct number of runs on it. In the example, that would mean an input file with 13 runs would write 5 runs to file 1 and 8 runs to file 2.
In practice, the input file won't happen to have a Fibonacci number of runs it (and the number of runs won't be known until after the file has been read). The fix is to pad the input files with dummy runs to make the required Fibonacci sequence.
For comparison, the ordinary merge sort will combine 16 runs in 4 passes using 4 files. The polyphase merge will combine 13 runs in 5 passes using only 3 files. Alternatively, a polyphase merge will combine 17 runs in 4 passes using 4 files. (Sequence: 1, 1, 1, 3, 5, 9, 17, 31, 57, ...)
An iteration (or pass) in ordinary merge sort involves reading and writing the entire file. An iteration in a polyphase sort does not read or write the entire file, so a typical polyphase iteration will take less time than a merge sort iteration.