

Word error rate
Encyclopedia
Word error rate is a common metric of the performance of a speech recognition
or machine translation
system.
The general difficulty of measuring performance lies in the fact that the recognized word sequence can have a different length from the reference word sequence (supposedly the correct one). The WER is derived from the Levenshtein distance
, working at the word level instead of the phoneme level.
This problem is solved by first aligning the recognized word sequence with the reference (spoken) word sequence using dynamic string alignment. The notion of uncertainty of a measurement is the hypothesis that word error rate and perplexity are correlated by a power law.
Word error rate can then be computed as:
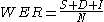
or
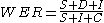
where
When reporting the performance of a speech recognition system, sometimes word accuracy (WAcc) is used instead:
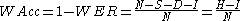
where
Note that since N is the number of words in the reference, the word error rate can be larger than 1.0, and thus, the word accuracy can be smaller than 0.0.
being tested. A further problem is that, even with the best alignment, the formula cannot distinguish a substitution error from a combined deletion plus insertion error.
Hunt (1990) has proposed the use of a weighted measure of performance accuracy where errors of substitution are weighted at unity but errors or deletion and insertion are both weighted only at 0.5, thus:
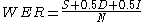
There is some debate, however, as to whether Hunt’s formula may properly be used to assess the performance of a single system, as it was developed as a means of comparing more fairly competing candidate systems. A further complication is added by whether a given syntax allows for error correction and, if it does, how easy that process is for the user. There is thus some merit to the argument that performance metrics should be developed to suit the particular system being measured.
Whichever metric is used, however, one major theoretical problem in assessing the performance of a system, is deciding whether a word has been “mis-pronounced” i.e. does the fault lie with the user or with the recogniser. This may be particularly relevant in a system which is designed to cope with non-native speakers of a given language or with strong regional accents.
The pace at which words should be spoken during the measurement process is also a source of variability between subjects, as is the need for subjects to rest or take a breath. All such factors may need to be controlled in some way.
For text dictation it is generally agreed that performance accuracy at a rate below 95% is not acceptable, but this again may be syntax and/or domain specific, e.g. whether there is time pressure on users to complete the task, whether there are alternative methods of completion, and so on.
The term "Single Word Error Rate" is sometimes referred to as the percentage of incorrect recognitions for each different word in the system vocabulary.
Speech recognition
Speech recognition converts spoken words to text. The term "voice recognition" is sometimes used to refer to recognition systems that must be trained to a particular speaker—as is the case for most desktop recognition software...
or machine translation
Machine translation
Machine translation, sometimes referred to by the abbreviation MT is a sub-field of computational linguistics that investigates the use of computer software to translate text or speech from one natural language to another.On a basic...
system.
The general difficulty of measuring performance lies in the fact that the recognized word sequence can have a different length from the reference word sequence (supposedly the correct one). The WER is derived from the Levenshtein distance
Levenshtein distance
In information theory and computer science, the Levenshtein distance is a string metric for measuring the amount of difference between two sequences...
, working at the word level instead of the phoneme level.
This problem is solved by first aligning the recognized word sequence with the reference (spoken) word sequence using dynamic string alignment. The notion of uncertainty of a measurement is the hypothesis that word error rate and perplexity are correlated by a power law.
Word error rate can then be computed as:
or
where
- S is the number of substitutions,
- D is the number of the deletions,
- I is the number of the insertions,
- C is the number of the corrects,
- N is the number of words in the reference.
When reporting the performance of a speech recognition system, sometimes word accuracy (WAcc) is used instead:
where
- H is N-(S+D), the number of correctly recognised words.
Note that since N is the number of words in the reference, the word error rate can be larger than 1.0, and thus, the word accuracy can be smaller than 0.0.
Other metrics
One problem with using a generic formula such as the one above, however, is that no account is taken of the effect that different types of error may have on the likelihood of successful outcome, e.g. some errors may be more disruptive than others and some may be corrected more easily than others. These factors are likely to be specific to the syntaxSyntax
In linguistics, syntax is the study of the principles and rules for constructing phrases and sentences in natural languages....
being tested. A further problem is that, even with the best alignment, the formula cannot distinguish a substitution error from a combined deletion plus insertion error.
Hunt (1990) has proposed the use of a weighted measure of performance accuracy where errors of substitution are weighted at unity but errors or deletion and insertion are both weighted only at 0.5, thus:
There is some debate, however, as to whether Hunt’s formula may properly be used to assess the performance of a single system, as it was developed as a means of comparing more fairly competing candidate systems. A further complication is added by whether a given syntax allows for error correction and, if it does, how easy that process is for the user. There is thus some merit to the argument that performance metrics should be developed to suit the particular system being measured.
Whichever metric is used, however, one major theoretical problem in assessing the performance of a system, is deciding whether a word has been “mis-pronounced” i.e. does the fault lie with the user or with the recogniser. This may be particularly relevant in a system which is designed to cope with non-native speakers of a given language or with strong regional accents.
The pace at which words should be spoken during the measurement process is also a source of variability between subjects, as is the need for subjects to rest or take a breath. All such factors may need to be controlled in some way.
For text dictation it is generally agreed that performance accuracy at a rate below 95% is not acceptable, but this again may be syntax and/or domain specific, e.g. whether there is time pressure on users to complete the task, whether there are alternative methods of completion, and so on.
The term "Single Word Error Rate" is sometimes referred to as the percentage of incorrect recognitions for each different word in the system vocabulary.
See also
- BLEUBleubleu or BLEU may refer to:* the French word for blue* Three Colors: Blue, a 1993 movie* Bilingual Evaluation Understudy, a machine translation evaluation metric* Belgium–Luxembourg Economic Union...
- F-MeasureF1 ScoreIn statistics, the F1 score is a measure of a test's accuracy. It considers both the precision p and the recall r of the test to compute the score: p is the number of correct results divided by the number of all returned results and r is the number of correct results divided by the number of...
- NIST (metric)NIST (metric)NIST is a method for evaluating the quality of text which has been translated using machine translation. Its name comes from the US National Institute of Standards and Technology....
- METEORMETEORMETEOR is a metric for the evaluation of machine translation output. The metric is based on the harmonic mean of unigram precision and recall, with recall weighted higher than precision...
- ROUGE (metric)ROUGE (metric)ROUGE, or Recall-Oriented Understudy for Gisting Evaluation, is a set of metrics and a software package used for evaluating automatic summarization and machine translation software in natural language processing...
- Noun-Phrase Chunking