

F1 Score
Encyclopedia
In statistics
, the F1 score (also F-score or F-measure) is a measure of a test's accuracy. It considers both the precision p and the recall r of the test to compute the score: p is the number of correct results divided by the number of all returned results and r is the number of correct results divided by the number of results that should have been returned. The F1 score can be interpreted as a weighted average of the precision and recall, where an F1 score reaches its best value at 1 and worst score at 0.
The traditional F-measure or balanced F-score (F1 score) is the harmonic mean of precision and recall:
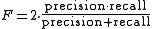 .
.
The general formula for positive real β is: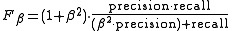 .
.
The formula in terms of Type I and type II errors
:
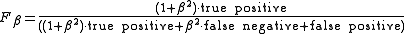 .
.
Two other commonly used F measures are the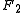 measure, which weights recall higher than precision, and the
measure, which weights recall higher than precision, and the 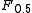 measure, which puts more emphasis on precision than recall.
measure, which puts more emphasis on precision than recall.
The F-measure was derived so that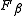 "measures the effectiveness of retrieval with respect to a user who attaches β times as much importance to recall as precision" . It is based on van Rijsbergen's effectiveness measure
"measures the effectiveness of retrieval with respect to a user who attaches β times as much importance to recall as precision" . It is based on van Rijsbergen's effectiveness measure
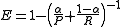 .
.
Their relationship is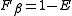 where
where 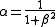 .
.
for measuring search, document classification
, and query classification performance. Earlier works focused primarily on the F1 score, but with the proliferation of large scale search engines, performance goals changed to place more emphasis on either precision or recall and so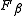 is seen in wide application.
is seen in wide application.
The F-score is also used in machine learning. Note, however, that the F-measures do not take the true negative rate into account, and that measures such as the Matthews correlation coefficient
may be preferable to assess the performance of a binary classifier.
Statistics
Statistics is the study of the collection, organization, analysis, and interpretation of data. It deals with all aspects of this, including the planning of data collection in terms of the design of surveys and experiments....
, the F1 score (also F-score or F-measure) is a measure of a test's accuracy. It considers both the precision p and the recall r of the test to compute the score: p is the number of correct results divided by the number of all returned results and r is the number of correct results divided by the number of results that should have been returned. The F1 score can be interpreted as a weighted average of the precision and recall, where an F1 score reaches its best value at 1 and worst score at 0.
The traditional F-measure or balanced F-score (F1 score) is the harmonic mean of precision and recall:
.The general formula for positive real β is:
.The formula in terms of Type I and type II errors
Type I and type II errors
In statistical test theory the notion of statistical error is an integral part of hypothesis testing. The test requires an unambiguous statement of a null hypothesis, which usually corresponds to a default "state of nature", for example "this person is healthy", "this accused is not guilty" or...
:
.Two other commonly used F measures are the
measure, which weights recall higher than precision, and the measure, which puts more emphasis on precision than recall.The F-measure was derived so that
"measures the effectiveness of retrieval with respect to a user who attaches β times as much importance to recall as precision" . It is based on van Rijsbergen's effectiveness measure.Their relationship is
where .Applications
The F-score is often used in the field of information retrievalInformation retrieval
Information retrieval is the area of study concerned with searching for documents, for information within documents, and for metadata about documents, as well as that of searching structured storage, relational databases, and the World Wide Web...
for measuring search, document classification
Document classification
Document classification or document categorization is a problem in both library science, information science and computer science. The task is to assign a document to one or more classes or categories. This may be done "manually" or algorithmically...
, and query classification performance. Earlier works focused primarily on the F1 score, but with the proliferation of large scale search engines, performance goals changed to place more emphasis on either precision or recall and so
is seen in wide application.The F-score is also used in machine learning. Note, however, that the F-measures do not take the true negative rate into account, and that measures such as the Matthews correlation coefficient
Matthews Correlation Coefficient
The Matthews correlation coefficient is used in machine learning as a measure of the quality of binary classifications. It takes into account true and false positives and negatives and is generally regarded as a balanced measure which can be used even if the classes are of very different sizes...
may be preferable to assess the performance of a binary classifier.
See also
- BLEUBleubleu or BLEU may refer to:* the French word for blue* Three Colors: Blue, a 1993 movie* Bilingual Evaluation Understudy, a machine translation evaluation metric* Belgium–Luxembourg Economic Union...
- NIST (metric)NIST (metric)NIST is a method for evaluating the quality of text which has been translated using machine translation. Its name comes from the US National Institute of Standards and Technology....
- METEORMETEORMETEOR is a metric for the evaluation of machine translation output. The metric is based on the harmonic mean of unigram precision and recall, with recall weighted higher than precision...
- ROUGE (metric)ROUGE (metric)ROUGE, or Recall-Oriented Understudy for Gisting Evaluation, is a set of metrics and a software package used for evaluating automatic summarization and machine translation software in natural language processing...
- Word Error Rate (WER)Word error rateWord error rate is a common metric of the performance of a speech recognition or machine translation system.The general difficulty of measuring performance lies in the fact that the recognized word sequence can have a different length from the reference word sequence...
- Noun phrase chunking
- Receiver operating characteristicReceiver operating characteristicIn signal detection theory, a receiver operating characteristic , or simply ROC curve, is a graphical plot of the sensitivity, or true positive rate, vs. false positive rate , for a binary classifier system as its discrimination threshold is varied...
- Matthews correlation coefficientMatthews Correlation CoefficientThe Matthews correlation coefficient is used in machine learning as a measure of the quality of binary classifications. It takes into account true and false positives and negatives and is generally regarded as a balanced measure which can be used even if the classes are of very different sizes...