A comparison sort is a type of sorting algorithm that only reads the list elements through a single abstract comparison operation that determines which of two elements should occur first in the final sorted list...
In computer science, a sorting algorithm is an algorithm that puts elements of a list in a certain order. The most-used orders are numerical order and lexicographical order...
Heapsort is a comparison-based sorting algorithm to create a sorted array , and is part of the selection sort family. Although somewhat slower in practice on most machines than a well implemented quicksort, it has the advantage of a more favorable worst-case O runtime...
Edsger Wybe Dijkstra ; ) was a Dutch computer scientist. He received the 1972 Turing Award for fundamental contributions to developing programming languages, and was the Schlumberger Centennial Chair of Computer Sciences at The University of Texas at Austin from 1984 until 2000.Shortly before his...
in 1981. Like heapsort, smoothsort's upper bound is O
Big O notation
In mathematics, big O notation is used to describe the limiting behavior of a function when the argument tends towards a particular value or infinity, usually in terms of simpler functions. It is a member of a larger family of notations that is called Landau notation, Bachmann-Landau notation, or...
A sorting algorithm falls into the adaptive sort family if it takes advantage of existing order in its input. It benefits from the presortedness in the input sequence – or a limited amount of disorder for various definitions of measures of disorder – and sorts faster...
, whereas heapsort averages O(n log n) regardless of the initial sorted state.
Heapsort is a comparison-based sorting algorithm to create a sorted array , and is part of the selection sort family. Although somewhat slower in practice on most machines than a well implemented quicksort, it has the advantage of a more favorable worst-case O runtime...
, smoothsort builds up an implicit heap data structure in the array to be sorted, then sorts the array by continuously extracting the maximum element from that heap. Unlike heapsort, smoothsort does not use a binary heap
Binary heap
A binary heap is a heap data structure created using a binary tree. It can be seen as a binary tree with two additional constraints:*The shape property: the tree is a complete binary tree; that is, all levels of the tree, except possibly the last one are fully filled, and, if the last level of...
, but rather a custom heap based on the Leonardo numbers L(n). The heap structure consists of a string of heaps, the sizes of which are all Leonardo numbers, and whose roots are stored in ascending order. The advantage of this custom heap over binary heaps is that if the sequence is already sorted, it takes only time to construct and deconstruct the heap, hence the better runtime.
Breaking the input up into a sequence of heaps is simple – the leftmost nodes of the array are made into the largest heap possible, and the remainder is likewise divided up. It can be proven that:
Any array of any length can so be divided up into sections of size L(x).
No two heaps will have the same size. The string will therefore be a string of heaps strictly descending in size.
No two heaps will have sizes that are consecutive Leonardo numbers, except for possibly the final two.
Each heap, having a size of L(x), is structured from left to right as a sub-heap of size L(x-1), a sub-heap of size L(x-2), and a root node, with the exception of heaps with a size of L(1) and L(0), which are singleton nodes. Each heap maintains the heap property that a root node is always at least as large as the root nodes of its child heaps (and therefore at least as large as all nodes in its child heaps), and the string of heaps as a whole maintains the string property that the root node of each heap is at least as large as the root node of the heap to the left.
The consequence of this is that the rightmost node in the string will always be the largest of the nodes, and, importantly, an array that is already sorted needs no rearrangement to be made into a valid series of heaps. This is the source of the adaptive qualities of the algorithm.
The algorithm is simple. We start by dividing up our unsorted array into a single heap of one element, followed by an unsorted portion. A one-element array is trivially a valid sequence of heaps. This sequence is then grown by adding one element at a time to the right, performing swaps to keep the sequence property and the heap property, until it fills the entire original array.
From this point on, the rightmost element of the sequence of heaps will be the largest element in any of the heaps, and will therefore be in its correct, final position. We then reduce the series of heaps back down to a single heap of one element by removing the rightmost node (which stays in place) and performing re-arrangements to restore the heap condition. When we are back down to a single heap of one element, the array is sorted.
Operations
Ignoring (for the moment) Dijkstra's optimisations, two operations are necessary – increase the string by adding one element to the right, and decrease the string by removing the right most element (the root of the last heap), preserving the heap and string conditions.
Grow the string by adding an element to the right
If the last two heaps are of size L(x+1) and L(x) (i.e.: consecutive leonardo numbers), the new element becomes the root node of a bigger heap of size L(x+2). This heap will not necessarily have the heap property.
If the last two heaps of the string are not consecutive Leonardo numbers, then the rightmost element becomes a new heap of size 1. This 1 is taken to be L(1), unless the rightmost heap already has size L(1), in which case the new one-element heap is taken to be of size L(0).
After this, the heap and string properties must be restored, which is usually done via a variant of insertion sort
Insertion sort
Insertion sort is a simple sorting algorithm: a comparison sort in which the sorted array is built one entry at a time. It is much less efficient on large lists than more advanced algorithms such as quicksort, heapsort, or merge sort...
. This is done as follows:
The rightmost heap (the one that has just been created) becomes the "current" heap
While there is a heap to the left of the current heap and its root is larger than the current root and both of its child heap roots
Then swap the new root with the root on the heap to the left (this will not disturb the heap property of the current heap). That heap then becomes the current heap.
Perform a "filter" operation on the current heap to establish the heap property:
While the current heap has a size greater than 1 and either child heap of the current heap has a root node greater than the root of the current heap
Swap the greater child root with the current root. That child heap becomes the current heap.
The filter operation is greatly simplified by the use of Leonardo numbers, as a heap will always either be a single node, or will have two children. One does not need to manage the condition of one of the child heaps not being present.
Optimisation
If the new heap is going to become part of a larger heap by the time we are done, then don't bother establishing the string property: it only needs to be done when a heap has reached its final size.
To do this, look at how many elements are left after the new heap of size L(x). If there are more than L(x-1)+1, then this new heap is going to be merged.
Do not maintain the heap property of the rightmost heap. If that heap becomes one of the final heaps of the string, then maintaining the string property will restore the heap property. Of course, whenever a new heap is created, then the rightmost heap is no longer the rightmost and the heap property needs to be restored.
Shrink the string by removing the rightmost element
If the rightmost heap has a size of 1 (i.e., L(1) or L(0)), then nothing needs to be done. Simply remove that rightmost heap.
If the rightmost heap does not have a size of 1, then remove the root, exposing the two sub-heaps as members of the string. Restore the string property first on the left one and then on the right one.
Optimisation
When restoring the string property, we do not need to compare the root of the heap to the left with the two child nodes of the heaps that have just been exposed, because we know that these newly exposed heaps have the heap property. Just compare it to the root.
Memory usage
The smoothsort algorithm needs to be able to hold in memory the sizes of all of the heaps in the string. Since all these values are distinct, this is usually done using a bit vector. Moreover, since there are at most O(log n) numbers in the sequence, these bits can be encoded in O(1) machine words, assuming a transdichotomous machine model
Transdichotomous model
In computational complexity theory, and more specifically in the analysis of algorithms with integer data, the transdichotomous model is a variation of the random access machine in which the machine word size is assumed to match the problem size. The model was proposed by Michael Fredman and Dan E...
.
Java implementation
This code uses lo and hi as the bounds of the array inclusive. Note that this is not the usual convention. Further note, that this implementation is a little flawed: The bitmap p only holds 32 bits and therefore limits the maximum number of heaps in the entire string to 32 (not counting the right-most heap of size LP[0]), which will eventually overflow if you try to sort an array of more than LP[32]+1 = 7049156 elements. This can be solved by using a long-bitmap wide enough to hold a single bit for every Leonardo-number that could be used as an array index in Java, which is exactly one more than the index of the largest such number (i.e. the largest one that fits into a 32-bit signed integer, as commented on LP) and is therefore equal to the length of LP which is 43.
// by keeping these constants, we can avoid the tiresome business
// of keeping track of Dijkstra's b and c. Instead of keeping
// b and c, I will keep an index into this array.
static final int LP[] = { 1, 1, 3, 5, 9, 15, 25, 41, 67, 109,
177, 287, 465, 753, 1219, 1973, 3193, 5167, 8361, 13529, 21891,
35421, 57313, 92735, 150049, 242785, 392835, 635621, 1028457,
1664079, 2692537, 4356617, 7049155, 11405773, 18454929, 29860703,
48315633, 78176337, 126491971, 204668309, 331160281, 535828591,
866988873 // the next number is > 31 bits.
};
public static > void sort(C[] m,
int lo, int hi) {
int head = lo; // the offset of the first element of the prefix into m
// These variables need a little explaining. If our string of heaps
// is of length 38, then the heaps will be of size 25+9+3+1, which are
// Leonardo numbers 6, 4, 2, 1.
// Turning this into a binary number, we get b01010110 = 0x56. We represent
// this number as a pair of numbers by right-shifting all the zeros and
// storing the mantissa and exponent as "p" and "pshift".
// This is handy, because the exponent is the index into L[] giving the
// size of the rightmost heap, and because we can instantly find out if
// the rightmost two heaps are consecutive Leonardo numbers by checking
// (p&3)
3
int p = 1; // the bitmap of the current standard concatenation >> pshift
int pshift = 1;
while (head < hi) {
if ((p & 3)
3) {
// Add 1 by merging the first two blocks into a larger one.
// The next Leonardo number is one bigger.
sift(m, pshift, head);
p >>>= 2;
pshift += 2;
} else {
// adding a new block of length 1
if (LP[pshift - 1] >= hi - head) {
// this block is its final size.
trinkle(m, p, pshift, head, false);
} else {
// this block will get merged. Just make it trusty.
sift(m, pshift, head);
}
if (pshift 1) {
// LP[1] is being used, so we add use LP[0]
p <<= 1;
pshift--;
} else {
// shift out to position 1, add LP[1]
p <<= (pshift - 1);
pshift = 1;
}
}
p |= 1;
head++;
}
trinkle(m, p, pshift, head, false);
while (pshift != 1 || p != 1) {
if (pshift <= 1) {
// block of length 1. No fiddling needed
int trail = Integer.numberOfTrailingZeros(p & ~1);
p >>>= trail;
pshift += trail;
} else {
p <<= 2;
p ^= 7;
pshift -= 2;
// This block gets broken into three bits. The rightmost
// bit is a block of length 1. The left hand part is split into
// two, a block of length LP[pshift+1] and one of LP[pshift].
// Both these two are appropriately heapified, but the root
// nodes are not necessarily in order. We therefore semitrinkle
// both of them
trinkle(m, p >>> 1, pshift + 1, head - LP[pshift] - 1, true);
trinkle(m, p, pshift, head - 1, true);
}
head--;
}
}
private static > void sift(C[] m, int pshift,
int head) {
// we do not use Floyd's improvements to the heapsort sift, because we
// are not doing what heapsort does - always moving nodes from near
// the bottom of the tree to the root.
C val = m[head];
while (pshift > 1) {
int rt = head - 1;
int lf = head - 1 - LP[pshift - 2];
if (val.compareTo(m[lf]) >= 0 && val.compareTo(m[rt]) >= 0)
break;
if (m[lf].compareTo(m[rt]) >= 0) {
m[head] = m[lf];
head = lf;
pshift -= 1;
} else {
m[head] = m[rt];
head = rt;
pshift -= 2;
}
}
m[head] = val;
}
private static > void trinkle(C[] m, int p,
int pshift, int head, boolean isTrusty) {
C val = m[head];
while (p != 1) {
int stepson = head - LP[pshift];
if (m[stepson].compareTo(val) <= 0)
break; // current node is greater than head. Sift.
// no need to check this if we know the current node is trusty,
// because we just checked the head (which is val, in the first
// iteration)
if (!isTrusty && pshift > 1) {
int rt = head - 1;
int lf = head - 1 - LP[pshift - 2];
if (m[rt].compareTo(m[stepson]) >= 0
|| m[lf].compareTo(m[stepson]) >= 0)
break;
}
m[head] = m[stepson];
head = stepson;
int trail = Integer.numberOfTrailingZeros(p & ~1);
p >>>= trail;
pshift += trail;
isTrusty = false;
}


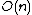 time to construct and deconstruct the heap, hence the better runtime.
time to construct and deconstruct the heap, hence the better runtime.