

Second-order co-occurrence pointwise mutual information
Encyclopedia
Second-order co-occurrence pointwise mutual information is a semantic similarity
measure using pointwise mutual information
to sort lists of important neighbor words of the two target words from a large corpus. PMI-IR used AltaVista
's Advanced Search query syntax to calculate probabilities
. Note that the ``NEAR" search
operator of AltaVista is an essential operator in the PMI-IR method. However, it is no longer in use in AltaVista; this means that, from the implementation point of view, it is not possible to use the PMI-IR method in the same form in new systems. In any case, from the algorithmic point of view, the advantage of using SOC-PMI is that it can calculate the similarity between two words that do not co-occur frequently, because they co-occur with the same neighboring words. For example, the British National Corpus
(BNC) has been used as a source of frequencies and contexts. The method considers the words that are common in both lists and aggregate their PMI values (from the opposite list) to calculate the relative semantic similarity. We define the pointwise mutual information function for only those words having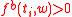 ,
,
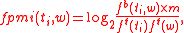
where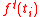 tells us how many times the type
tells us how many times the type 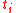 appeared in the entire corpus,
appeared in the entire corpus, 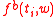 tells us how many times word
tells us how many times word 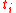 appeared with word
appeared with word  in a context window and
in a context window and  is total number of tokens in the corpus. Now, for word
is total number of tokens in the corpus. Now, for word  , we define a set of words,
, we define a set of words, 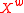 , sorted in descending order by their PMI values with
, sorted in descending order by their PMI values with  and taken the top-most
and taken the top-most 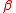 words having
words having 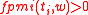 .
.
The set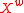 , contains words
, contains words 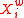 ,
, , where
, where 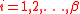 and
and
A rule of thumb
is used to choose the value of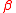 . The
. The 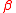 -PMI summation function of a word is defined with respect to another word. For word
-PMI summation function of a word is defined with respect to another word. For word 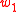 with respect to word
with respect to word 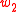 it is:
it is:
Semantic similarity
Semantic similarity or semantic relatedness is a concept whereby a set of documents or terms within term lists are assigned a metric based on the likeness of their meaning / semantic content....
measure using pointwise mutual information
Pointwise Mutual Information
Pointwise mutual information , or point mutual information, is a measure of association used in information theory and statistics.-Definition:...
to sort lists of important neighbor words of the two target words from a large corpus. PMI-IR used AltaVista
AltaVista
AltaVista is a web search engine owned by Yahoo!. AltaVista was once one of the most popular search engines but its popularity declined with the rise of Google...
's Advanced Search query syntax to calculate probabilities
Probability
Probability is ordinarily used to describe an attitude of mind towards some proposition of whose truth we arenot certain. The proposition of interest is usually of the form "Will a specific event occur?" The attitude of mind is of the form "How certain are we that the event will occur?" The...
. Note that the ``NEAR" search
operator of AltaVista is an essential operator in the PMI-IR method. However, it is no longer in use in AltaVista; this means that, from the implementation point of view, it is not possible to use the PMI-IR method in the same form in new systems. In any case, from the algorithmic point of view, the advantage of using SOC-PMI is that it can calculate the similarity between two words that do not co-occur frequently, because they co-occur with the same neighboring words. For example, the British National Corpus
British National Corpus
The British National Corpus is a 100-million-word text corpus of samples of written and spoken English from a wide range of sources. It was compiled as a general corpus in the field of corpus linguistics...
(BNC) has been used as a source of frequencies and contexts. The method considers the words that are common in both lists and aggregate their PMI values (from the opposite list) to calculate the relative semantic similarity. We define the pointwise mutual information function for only those words having
,where
tells us how many times the type appeared in the entire corpus, tells us how many times word appeared with word in a context window and is total number of tokens in the corpus. Now, for word , we define a set of words, , sorted in descending order by their PMI values with and taken the top-most words having .The set
, contains words ,, where andA rule of thumb
Rule of thumb
A rule of thumb is a principle with broad application that is not intended to be strictly accurate or reliable for every situation. It is an easily learned and easily applied procedure for approximately calculating or recalling some value, or for making some determination...
is used to choose the value of
. The -PMI summation function of a word is defined with respect to another word. For word with respect to word it is:-
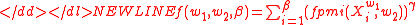
where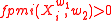 which sums all the positive PMI values of words in the set
which sums all the positive PMI values of words in the set 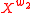 also common to the words in the set
also common to the words in the set 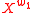 . In other words, this function actually aggregates the positive PMI values of all the semantically close words of
. In other words, this function actually aggregates the positive PMI values of all the semantically close words of 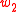 which are also common in
which are also common in 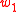 's list.
's list.  should have a value greater than 1. So, the
should have a value greater than 1. So, the 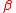 -PMI summation function for word
-PMI summation function for word 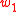 with respect to word
with respect to word 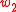 having
having 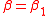 and the
and the 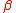 -PMI summation function for word
-PMI summation function for word 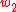 with respect to word
with respect to word 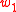 having
having 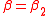 are
are
-
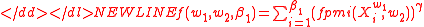
and
-
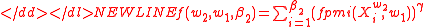
respectively.
Finally, the semantic PMI similarity function between the two words,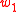 and
and 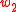 , is defined as
, is defined as
-
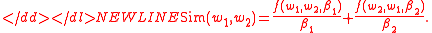
The semantic word similarity is normalized, so that it provides a similarity score between and
and 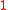 inclusively. The normalization of semantic similarity algorithm returns a normalized score of similarity between two words. It takes as arguments the two words,
inclusively. The normalization of semantic similarity algorithm returns a normalized score of similarity between two words. It takes as arguments the two words, 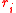 and
and 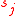 , and a maximum value,
, and a maximum value,  , that is returned by the semantic similarity function, Sim. It returns a similarity score between 0 and 1 inclusively. For example, the algorithm returns 0.986 for words cemetery and graveyard with
, that is returned by the semantic similarity function, Sim. It returns a similarity score between 0 and 1 inclusively. For example, the algorithm returns 0.986 for words cemetery and graveyard with  (for SOC-PMI method).
(for SOC-PMI method).
-
-
-