

Scapegoat tree
Encyclopedia
In computer science
, a scapegoat tree is a self-balancing binary search tree
, discovered by Arne Anderson and again by Igal Galperin and Ronald L. Rivest. It provides worst-case O
(log n) lookup time, and O(log n) amortized
insertion and deletion time.
Unlike most other self-balancing binary search trees that provide worst case O(log n) lookup time, scapegoat trees have no additional per-node memory overhead compared to a regular binary search tree
: a node stores only a key and two pointers to the child nodes. This makes scapegoat trees easier to implement and, due to data structure alignment
, can reduce node overhead by up to one-third.
An α-weight-balanced is therefore defined as meeting the following conditions:
size(left) <= α*size(node)
size(right) <= α*size(node)
Where size can be defined recursively as:
function size(node)
if node = nil
return 0
else
return size(node->left) + size(node->right) + 1
end
An α of 1 therefore would describe a linked list as balanced, whereas an α of 0.5 would only match almost complete binary trees.
A binary search tree that is α-weight-balanced must also be α-height-balanced, that is
height(tree) <= log1/α(NodeCount)
Scapegoat trees are not guaranteed to keep α-weight-balance at all times, but are always loosely α-height-balance in that
height(scapegoat tree) <= log1/α(NodeCount) + 1
This makes scapegoat trees similar to red-black trees in that they both have restrictions on their height. They differ greatly though in their implementations of determining where the rotations (or in the case of scapegoat trees, rebalances) take place. Whereas red-black trees store additional 'color' information in each node to determine the location, scapegoat trees find a scapegoat which isn't α-weight-balanced to perform the rebalance operation on. This is loosely similar to AVL trees, in that the actual rotations depend on 'balances' of nodes, but the means of determining the balance differs greatly. Since AVL trees check the balance value on every insertion/deletion, it is typically stored in each node; scapegoat trees are able to calculate it only as needed, which is only when a scapegoat needs to be found.
Unlike most other self-balancing search trees, scapegoat trees are entirely flexible as to their balancing. They support any α such that 0.5 <= α < 1. A high α value results in fewer balances, making insertion quicker but lookups and deletions slower, and vice versa for a low α. Therefore in practical applications, an α can be chosen depending on how frequently these actions should be performed.
When finding the insertion point, the depth of the new node must also be recorded. This is implemented via a simple counter that gets incremented during each iteration of the lookup, effectively counting the number of edges between the root and the inserted node. If this node violates the α-height-balance property (defined above), a rebalance is required.
To rebalance, an entire subtree rooted at a scapegoat undergoes a balancing operation. The scapegoat is defined as being an ancestor of the inserted node which isn't α-weight-balanced. There will always be at least one such ancestor. Rebalancing any of them will restore the α-height-balanced property.
One way of finding a scapegoat, is to climb from the new node back up to the root and select the first node that isn't α-weight-balanced.
Climbing back up to the root requires O(log n) storage space, usually allocated on the stack, or parent pointers. This can actually be avoided by pointing each child at its parent as you go down, and repairing on the walk back up.
To determine whether a potential node is a viable scapegoat, we need to check its α-weight-balanced property. To do this we can go back to the definition:
size(left) <= α*size(node)
size(right) <= α*size(node)
However a large optimisation can be made by realising that we already know two of the three sizes, leaving only the third having to be calculated.
Consider the following example to demonstrate this. Assuming that we're climbing back up to the root:
size(parent) = size(node) + size(sibling) + 1
But as:
size(inserted node) = 1.
The case is trivialized down to:
size[x+1] = size[x] + size(sibling) + 1
Where x = this node, x + 1 = parent and size(sibling) is the only function call actually required.
Once the scapegoat is found, the subtree rooted at the scapegoat is completely rebuilt to be perfectly balanced. This can be done in O(n) time by traversing the nodes of the subtree to find their values in sorted order and recursively choosing the median as the root of the subtree.
As rebalance operations take O(n) time (dependent on the number of nodes of the subtree), insertion has a worst case performance of O(n) time. However, because these worst-case scenarios are spread out, insertion takes O(log n) amortized time.
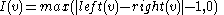
Immediately after rebuilding a subtree rooted at v, I(v) = 0.
Lemma: Immediately before rebuilding the subtree rooted at v,
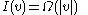
( is Big O Notation
is Big O Notation
.)
Proof of lemma:
Let be the root of a subtree immediately after rebuilding.
be the root of a subtree immediately after rebuilding. 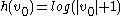 . If there are
. If there are 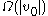 degenerate insertions (that is, where each inserted node increases the height by 1), then
degenerate insertions (that is, where each inserted node increases the height by 1), then
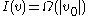 ,
,
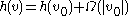 and
and
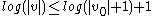 .
.
Since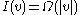 before rebuilding, there were
before rebuilding, there were 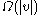 insertions into the subtree rooted at
insertions into the subtree rooted at  that did not result in rebuilding. Each of these insertions can be performed in
that did not result in rebuilding. Each of these insertions can be performed in 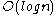 time. The final insertion that causes rebuilding costs
time. The final insertion that causes rebuilding costs 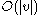 . Using aggregate analysis it becomes clear that the amortized cost of an insertion is
. Using aggregate analysis it becomes clear that the amortized cost of an insertion is 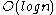 :
:
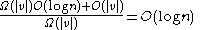
To perform a deletion, we simply remove the node as you would in a simple binary search tree, but if
NodeCount <= MaxNodeCount / 2
then we rebalance the entire tree about the root, remembering to set MaxNodeCount to NodeCount.
This gives deletion its worst case performance of O(n) time, however it is amortized to O(log n) average time.
 elements and has just been rebuilt (in other words, it is a complete binary tree). At most
elements and has just been rebuilt (in other words, it is a complete binary tree). At most 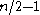 deletions can be performed before the tree must be rebuilt. Each of these deletions take
deletions can be performed before the tree must be rebuilt. Each of these deletions take 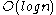 time (the amount of time to search for the element and flag it as deleted). The
time (the amount of time to search for the element and flag it as deleted). The 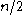 deletion causes the tree to be rebuilt and takes
deletion causes the tree to be rebuilt and takes 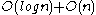 (or just
(or just 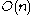 ) time. Using aggregate analysis it becomes clear that the amortized cost of a deletion is
) time. Using aggregate analysis it becomes clear that the amortized cost of a deletion is 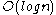 :
:
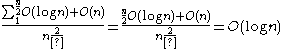
s which have a worst-case time of O(n). The reduced node memory overhead compared to other self-balancing binary search trees can further improve locality of reference and caching.
Computer science
Computer science or computing science is the study of the theoretical foundations of information and computation and of practical techniques for their implementation and application in computer systems...
, a scapegoat tree is a self-balancing binary search tree
Self-balancing binary search tree
In computer science, a self-balancing binary search tree is any node based binary search tree that automatically keeps its height small in the face of arbitrary item insertions and deletions....
, discovered by Arne Anderson and again by Igal Galperin and Ronald L. Rivest. It provides worst-case O
Big O notation
In mathematics, big O notation is used to describe the limiting behavior of a function when the argument tends towards a particular value or infinity, usually in terms of simpler functions. It is a member of a larger family of notations that is called Landau notation, Bachmann-Landau notation, or...
(log n) lookup time, and O(log n) amortized
Amortized analysis
In computer science, amortized analysis is a method of analyzing algorithms that considers the entire sequence of operations of the program. It allows for the establishment of a worst-case bound for the performance of an algorithm irrespective of the inputs by looking at all of the operations...
insertion and deletion time.
Unlike most other self-balancing binary search trees that provide worst case O(log n) lookup time, scapegoat trees have no additional per-node memory overhead compared to a regular binary search tree
Binary search tree
In computer science, a binary search tree , which may sometimes also be called an ordered or sorted binary tree, is a node-based binary tree data structurewhich has the following properties:...
: a node stores only a key and two pointers to the child nodes. This makes scapegoat trees easier to implement and, due to data structure alignment
Data structure alignment
Data structure alignment is the way data is arranged and accessed in computer memory. It consists of two separate but related issues: data alignment and data structure padding. When a modern computer reads from or writes to a memory address, it will do this in word sized chunks...
, can reduce node overhead by up to one-third.
Theory
A binary search tree is said to be weight balanced if half the nodes are on the left of the root, and half on the right.An α-weight-balanced is therefore defined as meeting the following conditions:
size(left) <= α*size(node)
size(right) <= α*size(node)
Where size can be defined recursively as:
function size(node)
if node = nil
return 0
else
return size(node->left) + size(node->right) + 1
end
An α of 1 therefore would describe a linked list as balanced, whereas an α of 0.5 would only match almost complete binary trees.
A binary search tree that is α-weight-balanced must also be α-height-balanced, that is
height(tree) <= log1/α(NodeCount)
Scapegoat trees are not guaranteed to keep α-weight-balance at all times, but are always loosely α-height-balance in that
height(scapegoat tree) <= log1/α(NodeCount) + 1
This makes scapegoat trees similar to red-black trees in that they both have restrictions on their height. They differ greatly though in their implementations of determining where the rotations (or in the case of scapegoat trees, rebalances) take place. Whereas red-black trees store additional 'color' information in each node to determine the location, scapegoat trees find a scapegoat which isn't α-weight-balanced to perform the rebalance operation on. This is loosely similar to AVL trees, in that the actual rotations depend on 'balances' of nodes, but the means of determining the balance differs greatly. Since AVL trees check the balance value on every insertion/deletion, it is typically stored in each node; scapegoat trees are able to calculate it only as needed, which is only when a scapegoat needs to be found.
Unlike most other self-balancing search trees, scapegoat trees are entirely flexible as to their balancing. They support any α such that 0.5 <= α < 1. A high α value results in fewer balances, making insertion quicker but lookups and deletions slower, and vice versa for a low α. Therefore in practical applications, an α can be chosen depending on how frequently these actions should be performed.
Insertion
Insertion is implemented very similarly to an unbalanced binary search tree, however with a few significant changes.When finding the insertion point, the depth of the new node must also be recorded. This is implemented via a simple counter that gets incremented during each iteration of the lookup, effectively counting the number of edges between the root and the inserted node. If this node violates the α-height-balance property (defined above), a rebalance is required.
To rebalance, an entire subtree rooted at a scapegoat undergoes a balancing operation. The scapegoat is defined as being an ancestor of the inserted node which isn't α-weight-balanced. There will always be at least one such ancestor. Rebalancing any of them will restore the α-height-balanced property.
One way of finding a scapegoat, is to climb from the new node back up to the root and select the first node that isn't α-weight-balanced.
Climbing back up to the root requires O(log n) storage space, usually allocated on the stack, or parent pointers. This can actually be avoided by pointing each child at its parent as you go down, and repairing on the walk back up.
To determine whether a potential node is a viable scapegoat, we need to check its α-weight-balanced property. To do this we can go back to the definition:
size(left) <= α*size(node)
size(right) <= α*size(node)
However a large optimisation can be made by realising that we already know two of the three sizes, leaving only the third having to be calculated.
Consider the following example to demonstrate this. Assuming that we're climbing back up to the root:
size(parent) = size(node) + size(sibling) + 1
But as:
size(inserted node) = 1.
The case is trivialized down to:
size[x+1] = size[x] + size(sibling) + 1
Where x = this node, x + 1 = parent and size(sibling) is the only function call actually required.
Once the scapegoat is found, the subtree rooted at the scapegoat is completely rebuilt to be perfectly balanced. This can be done in O(n) time by traversing the nodes of the subtree to find their values in sorted order and recursively choosing the median as the root of the subtree.
As rebalance operations take O(n) time (dependent on the number of nodes of the subtree), insertion has a worst case performance of O(n) time. However, because these worst-case scenarios are spread out, insertion takes O(log n) amortized time.
Sketch of proof for cost of insertion
Define the Imbalance of a node v to be the absolute value of the difference in size between its left node and right node minus 1, or 0, whichever is greater. In other words:Immediately after rebuilding a subtree rooted at v, I(v) = 0.
Lemma: Immediately before rebuilding the subtree rooted at v,
(
is Big O NotationBig O notation
In mathematics, big O notation is used to describe the limiting behavior of a function when the argument tends towards a particular value or infinity, usually in terms of simpler functions. It is a member of a larger family of notations that is called Landau notation, Bachmann-Landau notation, or...
.)
Proof of lemma:
Let
be the root of a subtree immediately after rebuilding. . If there are degenerate insertions (that is, where each inserted node increases the height by 1), then , and.Since
before rebuilding, there were insertions into the subtree rooted at that did not result in rebuilding. Each of these insertions can be performed in time. The final insertion that causes rebuilding costs . Using aggregate analysis it becomes clear that the amortized cost of an insertion is :Deletion
Scapegoat trees are unusual in that deletion is easier than insertion. To enable deletion, scapegoat trees need to store an additional value with the tree data structure. This property, which we will call MaxNodeCount simply represents the highest achieved NodeCount. It is set to NodeCount whenever the entire tree is rebalanced, and after insertion is set to max(MaxNodeCount, NodeCount).To perform a deletion, we simply remove the node as you would in a simple binary search tree, but if
NodeCount <= MaxNodeCount / 2
then we rebalance the entire tree about the root, remembering to set MaxNodeCount to NodeCount.
This gives deletion its worst case performance of O(n) time, however it is amortized to O(log n) average time.
Sketch of proof for cost of deletion
Suppose the scapegoat tree has elements and has just been rebuilt (in other words, it is a complete binary tree). At most deletions can be performed before the tree must be rebuilt. Each of these deletions take time (the amount of time to search for the element and flag it as deleted). The deletion causes the tree to be rebuilt and takes (or just ) time. Using aggregate analysis it becomes clear that the amortized cost of a deletion is :Lookup
Lookup is not modified from a standard binary search tree, and has a worst-case time of O(log n). This is in contrast to splay treeSplay tree
A splay tree is a self-adjusting binary search tree with the additional property that recently accessed elements are quick to access again. It performs basic operations such as insertion, look-up and removal in O amortized time. For many sequences of nonrandom operations, splay trees perform...
s which have a worst-case time of O(n). The reduced node memory overhead compared to other self-balancing binary search trees can further improve locality of reference and caching.
See also
- Splay treeSplay treeA splay tree is a self-adjusting binary search tree with the additional property that recently accessed elements are quick to access again. It performs basic operations such as insertion, look-up and removal in O amortized time. For many sequences of nonrandom operations, splay trees perform...
- Trees
- Tree rotationTree rotationA tree rotation is an operation on a binary tree that changes the structure without interfering with the order of the elements. A tree rotation moves one node up in the tree and one node down...
- AVL treeAVL treeIn computer science, an AVL tree is a self-balancing binary search tree, and it was the first such data structure to be invented. In an AVL tree, the heights of the two child subtrees of any node differ by at most one. Lookup, insertion, and deletion all take O time in both the average and worst...
- B-treeB-treeIn computer science, a B-tree is a tree data structure that keeps data sorted and allows searches, sequential access, insertions, and deletions in logarithmic time. The B-tree is a generalization of a binary search tree in that a node can have more than two children...
- T-treeT-treeIn computer science a T-tree is a type of binary treedata structure that is used by main-memory databases, such asDatablitz, eXtremeDB, MySQL Cluster, Oracle TimesTen and MobileLite....
- List of data structures