

Prefix code
Encyclopedia
A prefix code is a type of code
system (typically a variable-length code
) distinguished by its possession of the "prefix property"; which states that there is no valid code word
in the system that is a prefix (start) of any other valid code word in the set. For example, a code with code words {9, 59, 55} has the prefix property; a code consisting of {9, 5, 59, 55} does not, because "5" is a prefix of both "59" and "55". With a prefix code, a receiver can identify each word without requiring a special marker between words.
Prefix codes are also known as prefix-free codes, prefix condition codes and instantaneous codes. Although Huffman coding
is just one of many algorithms for deriving prefix codes, prefix codes are also widely referred to as "Huffman codes", even when the code was not produced by a Huffman algorithm. The term comma-free code is sometimes also applied as a synonym for prefix-free codes but in most mathematical books and articles (e. g. ) it is used to mean self-synchronizing code
s, a subclass of prefix codes.
Using prefix codes, a message can be transmitted as a sequence of concatenated code words, without any out-of-band
markers to frame the words in the message. The recipient can decode the message unambiguously, by repeatedly finding and removing prefixes that form valid code words. This is not possible with codes that lack the prefix property, for example {0, 1, 10, 11}: a receiver reading a "1" at the start of a code word would not know whether that was the complete code word "1", or merely the prefix of the code word "10" or "11".
The variable-length Huffman codes
, country calling codes, the country and publisher parts of ISBNs, the Secondary Synchronization Codes used in the UMTS W-CDMA
3G Wireless Standard, and the instruction sets
(machine language) of most computer microarchitectures are prefix codes.
Prefix codes are not error-correcting codes. In practice, a message might first be compressed with a prefix code, and then encoded again with channel coding (including error correction) before transmission.
Kraft's inequality
characterizes the sets of code word lengths that are possible in a prefix code.
If every word in the code has the same length, the code is called a fixed-length code, or a block code (though the term block code
is also used for fixed-size error-correcting codes in channel coding). For example, ISO 8859-15 letters are always 8 bits long. UTF-32/UCS-4
letters are always 32 bits long. ATM packets
are always 424 bits long. A block code of fixed length k bits can encode up to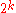 source symbols.
source symbols.
Prefixes cannot exist in a fixed-length code without padding fixed codes to the shorter prefixes in order to meet the length of the longest prefixes (however such padding codes may be selected to introduce redundancy that allows autocorrection and/or synchronisation). However, fixed length encodings are inefficient in situations where some words are much more likely to be transmitted than others (in which case some or all of the redundancy may be eliminated for data compression).
Truncated binary encoding
is a straightforward generalization of block codes to deal with cases where the number of symbols n is not a power of two. Source symbols are assigned codewords of length k and k+1. where .
.
Huffman coding
is a more sophisticated technique for constructing variable-length prefix codes. The Huffman coding algorithm takes as input the frequencies that the code words should have, and constructs a prefix code that minimizes the weighted average of the code word lengths. This is a form of lossless data compression
based on entropy encoding
.
Some codes mark the end of a code word with a special "comma" symbol, different from normal data. This is somewhat analogous to the spaces between words in a sentence; they mark where one word ends and another begins. If every code word ends in a comma, and the comma does not appear elsewhere in a code word, the code is prefix-free. However, modern communication systems send everything as sequences of "1" and "0" – adding a third symbol would be expensive, and using it only at the ends of words would be inefficient. Morse code
is an everyday example of a variable-length code with a comma. The long pauses between letters, and the even longer pauses between words, help people recognize where one letter (or word) ends, and the next begins. Similarly, Fibonacci coding
uses a "11" to mark the end of every code word.
Self-synchronizing code
s are prefix codes that allow frame synchronization
.
and the earlier Shannon-Fano codes, and universal code
s such as:
Code
A code is a rule for converting a piece of information into another form or representation , not necessarily of the same type....
system (typically a variable-length code
Variable-length code
In coding theory a variable-length code is a code which maps source symbols to a variable number of bits.Variable-length codes can allow sources to be compressed and decompressed with zero error and still be read back symbol by symbol...
) distinguished by its possession of the "prefix property"; which states that there is no valid code word
Code word
In communication, a code word is an element of a standardized code or protocol. Each code word is assembled in accordance with the specific rules of the code and assigned a unique meaning...
in the system that is a prefix (start) of any other valid code word in the set. For example, a code with code words {9, 59, 55} has the prefix property; a code consisting of {9, 5, 59, 55} does not, because "5" is a prefix of both "59" and "55". With a prefix code, a receiver can identify each word without requiring a special marker between words.
Prefix codes are also known as prefix-free codes, prefix condition codes and instantaneous codes. Although Huffman coding
Huffman coding
In computer science and information theory, Huffman coding is an entropy encoding algorithm used for lossless data compression. The term refers to the use of a variable-length code table for encoding a source symbol where the variable-length code table has been derived in a particular way based on...
is just one of many algorithms for deriving prefix codes, prefix codes are also widely referred to as "Huffman codes", even when the code was not produced by a Huffman algorithm. The term comma-free code is sometimes also applied as a synonym for prefix-free codes but in most mathematical books and articles (e. g. ) it is used to mean self-synchronizing code
Self-synchronizing code
In telecommunications, a self-synchronizing code is a line code in which the symbol stream formed by a portion of one code word, or by the overlapped portion of any two adjacent code words, is not a valid code word...
s, a subclass of prefix codes.
Using prefix codes, a message can be transmitted as a sequence of concatenated code words, without any out-of-band
Out-of-band
The term out-of-band has different uses in communications and telecommunication. In case of out-of-band control signaling, signaling bits are sent in special order in a dedicated signaling frame...
markers to frame the words in the message. The recipient can decode the message unambiguously, by repeatedly finding and removing prefixes that form valid code words. This is not possible with codes that lack the prefix property, for example {0, 1, 10, 11}: a receiver reading a "1" at the start of a code word would not know whether that was the complete code word "1", or merely the prefix of the code word "10" or "11".
The variable-length Huffman codes
Huffman coding
In computer science and information theory, Huffman coding is an entropy encoding algorithm used for lossless data compression. The term refers to the use of a variable-length code table for encoding a source symbol where the variable-length code table has been derived in a particular way based on...
, country calling codes, the country and publisher parts of ISBNs, the Secondary Synchronization Codes used in the UMTS W-CDMA
W-CDMA
W-CDMA , UMTS-FDD, UTRA-FDD, or IMT-2000 CDMA Direct Spread is an air interface standard found in 3G mobile telecommunications networks. It is the basis of Japan's NTT DoCoMo's FOMA service and the most-commonly used member of the UMTS family and sometimes used as a synonym for UMTS...
3G Wireless Standard, and the instruction sets
Instruction set
An instruction set, or instruction set architecture , is the part of the computer architecture related to programming, including the native data types, instructions, registers, addressing modes, memory architecture, interrupt and exception handling, and external I/O...
(machine language) of most computer microarchitectures are prefix codes.
Prefix codes are not error-correcting codes. In practice, a message might first be compressed with a prefix code, and then encoded again with channel coding (including error correction) before transmission.
Kraft's inequality
Kraft's inequality
In coding theory, Kraft's inequality, named after Leon Kraft, gives a necessary and sufficient condition for the existence of a uniquely decodable code for a given set of codeword lengths...
characterizes the sets of code word lengths that are possible in a prefix code.
Techniques
Techniques for constructing a prefix code can be simple, or quite complicated.If every word in the code has the same length, the code is called a fixed-length code, or a block code (though the term block code
Block code
In coding theory, block codes refers to the large and important family of error-correcting codes that encode data in blocks.There is a vast number of examples for block codes, many of which have a wide range of practical applications...
is also used for fixed-size error-correcting codes in channel coding). For example, ISO 8859-15 letters are always 8 bits long. UTF-32/UCS-4
UTF-32/UCS-4
UTF-32 is a protocol to encode Unicode characters that uses exactly 32 bits per Unicode code point. All other Unicode transformation formats use variable-length encodings. The UTF-32 form of a character is a direct representation of its codepoint.The main advantage of UTF-32, versus variable...
letters are always 32 bits long. ATM packets
Asynchronous Transfer Mode
Asynchronous Transfer Mode is a standard switching technique designed to unify telecommunication and computer networks. It uses asynchronous time-division multiplexing, and it encodes data into small, fixed-sized cells. This differs from approaches such as the Internet Protocol or Ethernet that...
are always 424 bits long. A block code of fixed length k bits can encode up to
source symbols.Prefixes cannot exist in a fixed-length code without padding fixed codes to the shorter prefixes in order to meet the length of the longest prefixes (however such padding codes may be selected to introduce redundancy that allows autocorrection and/or synchronisation). However, fixed length encodings are inefficient in situations where some words are much more likely to be transmitted than others (in which case some or all of the redundancy may be eliminated for data compression).
Truncated binary encoding
Truncated binary encoding
Truncated binary encoding is an entropy encoding typically used for uniform probability distributions with a finite alphabet. It is parameterized by an alphabet with total size of number n. It is a slightly more general form of binary encoding when n is not a power of two.Let n = 2k+b, for 0 ≤ b ≤ 2k...
is a straightforward generalization of block codes to deal with cases where the number of symbols n is not a power of two. Source symbols are assigned codewords of length k and k+1. where
.Huffman coding
Huffman coding
In computer science and information theory, Huffman coding is an entropy encoding algorithm used for lossless data compression. The term refers to the use of a variable-length code table for encoding a source symbol where the variable-length code table has been derived in a particular way based on...
is a more sophisticated technique for constructing variable-length prefix codes. The Huffman coding algorithm takes as input the frequencies that the code words should have, and constructs a prefix code that minimizes the weighted average of the code word lengths. This is a form of lossless data compression
Lossless data compression
Lossless data compression is a class of data compression algorithms that allows the exact original data to be reconstructed from the compressed data. The term lossless is in contrast to lossy data compression, which only allows an approximation of the original data to be reconstructed, in exchange...
based on entropy encoding
Entropy encoding
In information theory an entropy encoding is a lossless data compression scheme that is independent of the specific characteristics of the medium....
.
Some codes mark the end of a code word with a special "comma" symbol, different from normal data. This is somewhat analogous to the spaces between words in a sentence; they mark where one word ends and another begins. If every code word ends in a comma, and the comma does not appear elsewhere in a code word, the code is prefix-free. However, modern communication systems send everything as sequences of "1" and "0" – adding a third symbol would be expensive, and using it only at the ends of words would be inefficient. Morse code
Morse code
Morse code is a method of transmitting textual information as a series of on-off tones, lights, or clicks that can be directly understood by a skilled listener or observer without special equipment...
is an everyday example of a variable-length code with a comma. The long pauses between letters, and the even longer pauses between words, help people recognize where one letter (or word) ends, and the next begins. Similarly, Fibonacci coding
Fibonacci coding
In mathematics, Fibonacci coding is a universal code which encodes positive integers into binary code words. Each code word ends with "11" and contains no other instances of "11" before the end.-Definition:...
uses a "11" to mark the end of every code word.
Self-synchronizing code
Self-synchronizing code
In telecommunications, a self-synchronizing code is a line code in which the symbol stream formed by a portion of one code word, or by the overlapped portion of any two adjacent code words, is not a valid code word...
s are prefix codes that allow frame synchronization
Frame synchronization
While receiving a stream of framed data, frame synchronization is the process by which incoming frame alignment signals, i.e., distinctive bit sequences , are identified, i.e., distinguished from data bits, permitting the data bits within the frame to be extracted for decoding or retransmission...
.
Prefix codes in use today
Examples of prefix codes include:- country calling codes
- the country and publisher parts of ISBNs
- the Secondary Synchronization Codes used in the UMTS W-CDMAW-CDMAW-CDMA , UMTS-FDD, UTRA-FDD, or IMT-2000 CDMA Direct Spread is an air interface standard found in 3G mobile telecommunications networks. It is the basis of Japan's NTT DoCoMo's FOMA service and the most-commonly used member of the UMTS family and sometimes used as a synonym for UMTS...
3G Wireless Standard - VCR Plus+ codes
- the UTF-8UTF-8UTF-8 is a multibyte character encoding for Unicode. Like UTF-16 and UTF-32, UTF-8 can represent every character in the Unicode character set. Unlike them, it is backward-compatible with ASCII and avoids the complications of endianness and byte order marks...
system for encoding UnicodeUnicodeUnicode is a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world's writing systems...
characters - the instruction setsInstruction setAn instruction set, or instruction set architecture , is the part of the computer architecture related to programming, including the native data types, instructions, registers, addressing modes, memory architecture, interrupt and exception handling, and external I/O...
(machine language) of most computer microarchitectures
Techniques
Commonly used techniques for constructing prefix codes include Huffman codesHuffman coding
In computer science and information theory, Huffman coding is an entropy encoding algorithm used for lossless data compression. The term refers to the use of a variable-length code table for encoding a source symbol where the variable-length code table has been derived in a particular way based on...
and the earlier Shannon-Fano codes, and universal code
Universal code (data compression)
In data compression, a universal code for integers is a prefix code that maps the positive integers onto binary codewords, with the additional property that whatever the true probability distribution on integers, as long as the distribution is monotonic , the expected lengths of the codewords are...
s such as:
- Elias delta codingElias delta codingElias delta code is a universal code encoding the positive integers developed by Peter Elias. To code a number:#Write it in binary.#Count the bits and write down that number of bits in binary ....
- Elias gamma codingElias gamma codingElias gamma code is a universal code encoding positive integers developed by Peter Elias. It is used most commonly when coding integers whose upper-bound cannot be determined beforehand.-Encoding:To code a number:#Write it in binary....
- Elias omega codingElias omega codingElias omega coding is a universal code encoding the positive integers developed by Peter Elias. Like Elias gamma coding and Elias delta coding, it works by prefixing the integer with a representation of its order of magnitude in a universal code...
- Fibonacci codingFibonacci codingIn mathematics, Fibonacci coding is a universal code which encodes positive integers into binary code words. Each code word ends with "11" and contains no other instances of "11" before the end.-Definition:...
- Levenshtein codingLevenshtein codingLevenstein coding, or Levenshtein coding, is a universal code encoding the non-negative integers developed by Vladimir Levenshtein.The code of zero is "0"; to code a positive number:#Initialize the step count variable C to 1....
- Unary codingUnary codingUnary coding, sometimes called thermometer code, is an entropy encoding that represents a natural number, n, with n ones followed by a zero or with n − 1 ones followed by a zero...
- Golomb Rice code
- Straddling checkerboardStraddling checkerboardIn cryptography, a straddling checkerboard is a device for converting an alphabetic plaintext into digits whilst simultaneously achieving fractionation and data compression relative to other schemes using digits...
(simple cryptography technique which produces prefix codes)
External links
- Codes, trees and the prefix property by Kona Macphee