

Okapi BM25
Encyclopedia
In information retrieval
, Okapi BM25 is a ranking function
used by search engine
s to rank matching documents according to their relevance
to a given search query. It is based on the probabilistic retrieval framework developed in the 1970s and 1980s by Stephen E. Robertson, Karen Spärck Jones
, and others.
The name of the actual ranking function is BM25. To set the right context, however, it usually referred to as "Okapi BM25", since the Okapi information retrieval system, implemented at London
's City University
in the 1980s and 1990s, was the first system to implement this function.
BM25, and its newer variants, e.g. BM25F (a version of BM25 that can take document structure and anchor text into account), represent state-of-the-art TF-IDF-like retrieval functions used in document retrieval, such as Web search.
Given a query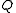 , containing keywords
, containing keywords 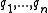 , the BM25 score of a document
, the BM25 score of a document 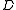 is:
is:
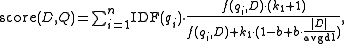
where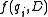 is
is 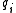 's term frequency in the document
's term frequency in the document 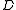 ,
, 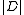 is the length of the document
is the length of the document 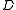 in words, and
in words, and 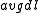 is the average document length in the text collection from which documents are drawn.
is the average document length in the text collection from which documents are drawn. 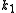 and
and 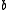 are free parameters, usually chosen, in absence of an advanced optimization, as
are free parameters, usually chosen, in absence of an advanced optimization, as 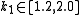 and
and 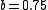 .
. 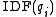 is the IDF (inverse document frequency) weight of the query term
is the IDF (inverse document frequency) weight of the query term 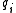 . It is usually computed as:
. It is usually computed as:
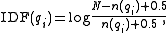
where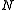 is the total number of documents in the collection, and
is the total number of documents in the collection, and 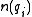 is the number of documents containing
is the number of documents containing 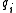 .
.
There are several interpretations for IDF and slight variations on its formula. In the original BM25 derivation, the IDF component is derived from the Binary Independence Model
.
Please note that the above formula for IDF shows potentially major drawbacks when using it for terms appearing in more than half of the corpus documents. These terms' IDF is negative, so for any two almost-identical documents, one which contains the term and one which does not contain it, the latter will possibly get a larger score.
This means that terms appearing in more than half of the corpus will provide negative contributions to the final document score. This is often an undesirable behavior, so many real-world applications would deal with this IDF formula in a different way:
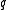 appears in
appears in 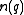 documents. Then a randomly picked document
documents. Then a randomly picked document 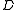 will contain the term with probability
will contain the term with probability 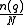 (where
(where 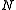 is again the cardinality of the set of documents in the collection). Therefore, the information
is again the cardinality of the set of documents in the collection). Therefore, the information
content of the message "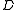 contains
contains 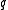 " is:
" is:
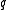
Now suppose we have two query terms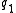 and
and 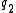 . If the two terms occur in documents entirely independently of each other, then the probability of seeing both
. If the two terms occur in documents entirely independently of each other, then the probability of seeing both 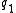 and
and 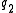 in a randomly picked document
in a randomly picked document 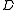 is:
is:
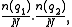
and the information content of such an event is:
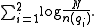
With a small variation, this is exactly what is expressed by the IDF component of BM25.
Information retrieval
Information retrieval is the area of study concerned with searching for documents, for information within documents, and for metadata about documents, as well as that of searching structured storage, relational databases, and the World Wide Web...
, Okapi BM25 is a ranking function
Ranking function
In information retrieval, a ranking function is a function used by search engines to rank matching documents according to their relevance to a given search query....
used by search engine
Search engine
A search engine is an information retrieval system designed to help find information stored on a computer system. The search results are usually presented in a list and are commonly called hits. Search engines help to minimize the time required to find information and the amount of information...
s to rank matching documents according to their relevance
Relevance (information retrieval)
In information science and information retrieval, relevance denotes how well a retrieved document or set of documents meets the information need of the user.-Types:...
to a given search query. It is based on the probabilistic retrieval framework developed in the 1970s and 1980s by Stephen E. Robertson, Karen Spärck Jones
Karen Spärck Jones
Karen Spärck Jones FBA was a British computer scientist.Karen Spärck Jones was born in Huddersfield, Yorkshire, England. Her father was Owen Jones, a lecturer in chemistry, and her mother was Ida Spärck, a Norwegian who moved to Britain during World War II...
, and others.
The name of the actual ranking function is BM25. To set the right context, however, it usually referred to as "Okapi BM25", since the Okapi information retrieval system, implemented at London
London
London is the capital city of :England and the :United Kingdom, the largest metropolitan area in the United Kingdom, and the largest urban zone in the European Union by most measures. Located on the River Thames, London has been a major settlement for two millennia, its history going back to its...
's City University
City University, London
City University London , is a public research university located in London, United Kingdom. It was founded in 1894 as the Northampton Institute and became a university in 1966, when it adopted its present name....
in the 1980s and 1990s, was the first system to implement this function.
BM25, and its newer variants, e.g. BM25F (a version of BM25 that can take document structure and anchor text into account), represent state-of-the-art TF-IDF-like retrieval functions used in document retrieval, such as Web search.
The ranking function
BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms appearing in each document, regardless of the inter-relationship between the query terms within a document (e.g., their relative proximity). It is not a single function, but actually a whole family of scoring functions, with slightly different components and parameters. One of the most prominent instantiations of the function is as follows.Given a query
, containing keywords , the BM25 score of a document is:where
is 's term frequency in the document , is the length of the document in words, and is the average document length in the text collection from which documents are drawn. and are free parameters, usually chosen, in absence of an advanced optimization, as and . is the IDF (inverse document frequency) weight of the query term . It is usually computed as:where
is the total number of documents in the collection, and is the number of documents containing .There are several interpretations for IDF and slight variations on its formula. In the original BM25 derivation, the IDF component is derived from the Binary Independence Model
Binary Independence Model
The Binary Independence Model is a probabilistic information retrieval technique that makes some simple assumptions to make the estimation of document/query similarity probability feasible.-Definitions:...
.
Please note that the above formula for IDF shows potentially major drawbacks when using it for terms appearing in more than half of the corpus documents. These terms' IDF is negative, so for any two almost-identical documents, one which contains the term and one which does not contain it, the latter will possibly get a larger score.
This means that terms appearing in more than half of the corpus will provide negative contributions to the final document score. This is often an undesirable behavior, so many real-world applications would deal with this IDF formula in a different way:
- Each summand can be given a floor of 0, to trim out common terms;
- The IDF function can be given a floor of a constant
 , to avoid common terms being ignored at all;
, to avoid common terms being ignored at all; - The IDF function can be replaced with a similarly shaped one which is non-negative, or strictly positive to avoid terms being ignored at all.
IDF Information Theoretic Interpretation
Here is an interpretation from information theory. Suppose a query term appears in documents. Then a randomly picked document will contain the term with probability (where is again the cardinality of the set of documents in the collection). Therefore, the informationInformation
Information in its most restricted technical sense is a message or collection of messages that consists of an ordered sequence of symbols, or it is the meaning that can be interpreted from such a message or collection of messages. Information can be recorded or transmitted. It can be recorded as...
content of the message "
contains " is:Now suppose we have two query terms
and . If the two terms occur in documents entirely independently of each other, then the probability of seeing both and in a randomly picked document is:and the information content of such an event is:
With a small variation, this is exactly what is expressed by the IDF component of BM25.
Modifications
- At the extreme values of the coefficient
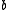 BM25 turns into ranking functions known as BM11 (for
BM25 turns into ranking functions known as BM11 (for 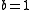 ) and BM15 (for
) and BM15 (for 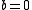 ).
). - BM25F is a modification of BM25 in which the document is considered to be composed from several fields (such as headlines, main text, anchor text) with possibly different degrees of importance.