

Object categorization from image search
Encyclopedia
In computer vision, the problem of object categorization from image search is the problem of training a classifier to recognize categories of objects, using only the images retrieved automatically with an Internet search engine. Ideally, automatic image collection would allow classifiers to be trained with nothing but the category names as input. This problem is closely related to that of content-based image retrieval (CBIR), where the goal is to return better image search results rather than training a classifier for image recognition.
Traditionally, classifiers are trained using sets of images that are labeled by hand. Collecting such a set of images is often a very time-consuming and laborious process. The use of Internet search engines to automate the process of acquiring large sets of labeled images has been described as a potential way of greatly facilitating computer vision research.
and Pascal
. Images of objects can vary widely in a number of important factors, such as scale, pose, lighting, number of objects, and amount of occlusion.
, but has since been applied to computer vision
. It makes the assumption that images are documents that fit the bag of words model
.
pLSA divides documents into topics as well. Just as knowing the topic(s) of an article allows you to make good guesses about the kinds of words that will appear in it, the distribution of words in an image is dependent on the underlying topics. The pLSA model tells us the probability of seeing each word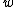 given the category
given the category 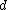 in terms of topics
in terms of topics  :
:
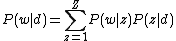
An important assumption made in this model is that and
and 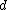 are conditionally independent given
are conditionally independent given  . Given a topic, the probability of a certain word appearing as part of that topic is independent of the rest of the image.
. Given a topic, the probability of a certain word appearing as part of that topic is independent of the rest of the image.
Training this model involves finding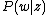 and
and 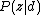 that maximizes the likelihood of the observed words in each document. To do this, the expectation maximization algorithm is used, with the following objective function:
that maximizes the likelihood of the observed words in each document. To do this, the expectation maximization algorithm is used, with the following objective function:
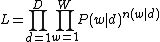
 represents which of the bins the visual word falls into. The new equation is:
represents which of the bins the visual word falls into. The new equation is:
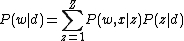
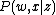 and
and 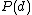 can be solved for in a manner similar to the original pLSA problem, using the EM algorithm
can be solved for in a manner similar to the original pLSA problem, using the EM algorithm
A problem with this model is that it is not translation or scale invariant. Since the positions of the visual words are absolute, changing the size of the object in the image or moving it would have a significant impact on the spatial distribution of the visual words into different bins.
 of a visual word is given relative to this object location, rather than as an absolute position in the image. The new equation is:
of a visual word is given relative to this object location, rather than as an absolute position in the image. The new equation is:
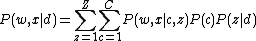
Again, the parameters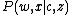 and
and 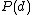 can be solved using the EM algorithm.
can be solved using the EM algorithm. 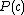 can be assumed to be a uniform distribution.
can be assumed to be a uniform distribution.
Using these 4 detectors, approximately 700 features were detected per image. These features were then encoded as Scale-invariant feature transform
descriptors, and vector quantized to match one of 350 words contained in a codebook. The codebook was precomputed from features extracted from a large number of images spanning numerous object categories.
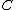 can take on. It is a 4-vector, whose components describe the object抯 centroid as well as x and y scales that define a bounding box around the object, so the space of possible values it can take on is enormous. To limit the number of possible object locations to a reasonable number, normal pLSA is first carried out on the set of images, and for each topic a Gaussian mixture model is fit over the visual words, weighted by
can take on. It is a 4-vector, whose components describe the object抯 centroid as well as x and y scales that define a bounding box around the object, so the space of possible values it can take on is enormous. To limit the number of possible object locations to a reasonable number, normal pLSA is first carried out on the set of images, and for each topic a Gaussian mixture model is fit over the visual words, weighted by 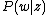 . Up to
. Up to 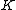 Gaussians are tried (allowing for multiple instances of an object in a single image), where
Gaussians are tried (allowing for multiple instances of an object in a single image), where 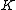 is a constant.
is a constant.
As expected, training directly on Google data gives higher error rates than training on prepared data.? In about half of the object categories tested do ABS-pLSA and TSI-pLSA perform significantly better than regular pLSA, and in only 2 categories out of 7 does TSI-pLSA perform better than the other two models.
Note that only the most recently added images are used in each round of learning. This allows the algorithm to run on an arbitrarily large number of input images.
. HDP models the distributions of an unspecified number of topics across images in a category, and across categories. The distribution of topics among images in a single category is modeled as a Dirichlet process
(a type of non-parametric
probability distribution
). To allow the sharing of topics across classes, each of these Dirichlet processes is modeled as a sample from another 損arent?Dirichlet process. HDP was first described by Teh et al. in 2005.
is used over the latent variables. It is carried out after each new set of images is incorporated into the dataset. Gibbs sampling involves repeatedly sampling from a set of random variables in order to approximate their distributions. Sampling involves generating a value for the random variable in question, based on the state of the other random variables on which it is dependent. Given sufficient samples, a reasonable approximation of the value can be achieved.
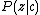 and
and  can be obtained from model learned after the previous round of Gibbs sampling, where
can be obtained from model learned after the previous round of Gibbs sampling, where  is a topic,
is a topic,  is a category, and
is a category, and  is a single visual word. The likelihood of an image being in a certain class, then, is:
is a single visual word. The likelihood of an image being in a certain class, then, is:
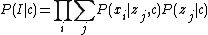
This is computed for each new candidate image per iteration. The image is classified as belonging to the category with the highest likelihood.
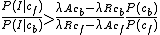
Where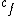 and
and 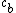 are foreground (object) and background categories, respectively, and the ratio of constants describes the risk of accepting false positives and false negatives. They are adjusted automatically at every iteration, with the cost of a false positive set higher than that of a false negative. This ensures that a better dataset is collected.
are foreground (object) and background categories, respectively, and the ratio of constants describes the risk of accepting false positives and false negatives. They are adjusted automatically at every iteration, with the cost of a false positive set higher than that of a false negative. This ensures that a better dataset is collected.
Once an image is accepted by meeting the above criterion and incorporated into the dataset, however, it needs to meet another criterion before it is incorporated into the 揷ache set敆the set of images to be used for training. This set is intended to be a diverse subset of the set of accepted images. If the model were trained on all accepted images, it might become more and more highly specialized, only accepting images very similar to previous ones.
is that of improving search results by taking into account visual information contained in the images themselves. Several CBIR methods make use of classifiers trained on image search results, to refine the search. In other words, object categorization from image search is one component of the system. OPTIMOL, for example, uses a classifier trained on images collected during previous iterations to select additional images for the returned dataset.
Examples of CBIR methods that model object categories from image search are:
Traditionally, classifiers are trained using sets of images that are labeled by hand. Collecting such a set of images is often a very time-consuming and laborious process. The use of Internet search engines to automate the process of acquiring large sets of labeled images has been described as a potential way of greatly facilitating computer vision research.
Unrelated images
One problem with using Internet image search results as a training set for a classifier is the high percentage of unrelated images within the results. It has been estimated that, when a search engine such as Google images is queried with the name of an object category (such as airplane?, up to 85% of the returned images are unrelated to the category.Intra-class variability
Another challenge posed by using Internet image search results as training sets for classifiers is that there is a high amount of variability within object categories, when compared with categories found in hand-labeled datasets such as Caltech 101Caltech 101
Caltech 101 is a dataset of digital images created in September, 2003, compiled by Fei-Fei Li, Marco Andreetto, Marc 'Aurelio Ranzato and Pietro Perona at the California Institute of Technology. It is intended to facilitate Computer Vision research and techniques. It is most applicable to...
and Pascal
Pascal (programming language)
Pascal is an influential imperative and procedural programming language, designed in 1968/9 and published in 1970 by Niklaus Wirth as a small and efficient language intended to encourage good programming practices using structured programming and data structuring.A derivative known as Object Pascal...
. Images of objects can vary widely in a number of important factors, such as scale, pose, lighting, number of objects, and amount of occlusion.
pLSA approach
In a 2005 paper by Fergus et al., pLSA (probabilistic latent semantic analysis) and extensions of this model were applied to the problem of object categorization from image search. pLSA was originally developed for document classificationDocument classification
Document classification or document categorization is a problem in both library science, information science and computer science. The task is to assign a document to one or more classes or categories. This may be done "manually" or algorithmically...
, but has since been applied to computer vision
Computer vision
Computer vision is a field that includes methods for acquiring, processing, analysing, and understanding images and, in general, high-dimensional data from the real world in order to produce numerical or symbolic information, e.g., in the forms of decisions...
. It makes the assumption that images are documents that fit the bag of words model
Bag of words model
The bag-of-words model is a simplifying assumption used in natural language processing and information retrieval. In this model, a text is represented as an unordered collection of words, disregarding grammar and even word order.The bag-of-words model is used in some methods of document...
.
Model
Just as text documents are made up of words, each of which may be repeated within the document and across documents, images can be modeled as combinations of visual words. Just as the entire set of text words are defined by a dictionary, the entire set of visual words is defined in a codeword dictionary.pLSA divides documents into topics as well. Just as knowing the topic(s) of an article allows you to make good guesses about the kinds of words that will appear in it, the distribution of words in an image is dependent on the underlying topics. The pLSA model tells us the probability of seeing each word
given the category in terms of topics :An important assumption made in this model is that
and are conditionally independent given . Given a topic, the probability of a certain word appearing as part of that topic is independent of the rest of the image.Training this model involves finding
and that maximizes the likelihood of the observed words in each document. To do this, the expectation maximization algorithm is used, with the following objective function:ABS-pLSA
Absolute position pLSA (ABS-pLSA) attaches location information to each visual word by localizing it to one of X 揵ins?in the image. Here, represents which of the bins the visual word falls into. The new equation is: and can be solved for in a manner similar to the original pLSA problem, using the EM algorithmA problem with this model is that it is not translation or scale invariant. Since the positions of the visual words are absolute, changing the size of the object in the image or moving it would have a significant impact on the spatial distribution of the visual words into different bins.
TSI-pLSA
Translation and scale invariant pLSA (TSI-pLSA). This model extends pLSA by adding another latent variable, which describes the spatial location of the target object in an image. Now, the position of a visual word is given relative to this object location, rather than as an absolute position in the image. The new equation is:Again, the parameters
and can be solved using the EM algorithm. can be assumed to be a uniform distribution.Selecting words
Words in an image were selected using 4 different feature detectors:- Kadir brady saliency detectorKadir brady saliency detectorThe Kadir–Brady saliency detector extracts features of objects in images that are distinct and representative. It was invented by Timor Kadir and Michael Brady in 2001 and an affine invariant version was introduced by Kadir and Brady in 2004....
- Multi-scale Harris detectorCorner detectionCorner detection is an approach used within computer vision systems to extract certain kinds of features and infer the contents of an image. Corner detection is frequently used in motion detection, image registration, video tracking, image mosaicing, panorama stitching, 3D modelling and object...
- Difference of GaussiansDifference of GaussiansIn computer vision, Difference of Gaussians is a grayscale image enhancement algorithm that involves the subtraction of one blurred version of an original grayscale image from another, less blurred version of the original. The blurred images are obtained by convolving the original grayscale image...
- Edge based operator, described in the study
Using these 4 detectors, approximately 700 features were detected per image. These features were then encoded as Scale-invariant feature transform
SIFT
SIFT may refer to:* Shanghai Institute of Foreign Trade, a public university in Shanghai, China* Scale-invariant feature transform, an algorithm in computer vision to detect and describe local features in images...
descriptors, and vector quantized to match one of 350 words contained in a codebook. The codebook was precomputed from features extracted from a large number of images spanning numerous object categories.
Possible object locations
One important question in the TSI-pLSA model is how to determine the values that the random variable can take on. It is a 4-vector, whose components describe the object抯 centroid as well as x and y scales that define a bounding box around the object, so the space of possible values it can take on is enormous. To limit the number of possible object locations to a reasonable number, normal pLSA is first carried out on the set of images, and for each topic a Gaussian mixture model is fit over the visual words, weighted by . Up to Gaussians are tried (allowing for multiple instances of an object in a single image), where is a constant.Performance
The authors of the Fergus et al. paper compared performance of the three pLSA algorithms (pLSA, ABS-pLSA, and TSI-pLSA) on handpicked datasets and images returned from Google searches. Performance was measured as the error rate when classifying images in a test set as either containing the image or containing only background.As expected, training directly on Google data gives higher error rates than training on prepared data.? In about half of the object categories tested do ABS-pLSA and TSI-pLSA perform significantly better than regular pLSA, and in only 2 categories out of 7 does TSI-pLSA perform better than the other two models.
OPTIMOL
OPTIMOL (automatic Online Picture collection via Incremental MOdel Learning) approaches the problem of learning object categories from online image searches by addressing model learning and searching simultaneously. OPTIMOL is an iterative model that updates its model of the target object category while concurrently retrieving more relevant images.General framework
OPTIMOL was presented as a general iterative framework that is independent of the specific model used for category learning. The algorithm is as follows:- Download a large set of images from the Internet by searching for a keyword
- Initialize the dataset with seed images
- While more images needed in the dataset:
- Learn the model with most recently added dataset images
- Classify downloaded images using the updated model
- Add accepted images to the dataset
Note that only the most recently added images are used in each round of learning. This allows the algorithm to run on an arbitrarily large number of input images.
Model
The two categories (target object and background) are modeled as Hierarchical Dirichlet processes (HDPs). As in the pLSA approach, it is assumed that the images can be described with the bag of words modelBag of words model
The bag-of-words model is a simplifying assumption used in natural language processing and information retrieval. In this model, a text is represented as an unordered collection of words, disregarding grammar and even word order.The bag-of-words model is used in some methods of document...
. HDP models the distributions of an unspecified number of topics across images in a category, and across categories. The distribution of topics among images in a single category is modeled as a Dirichlet process
Dirichlet process
In probability theory, a Dirichlet process is a stochastic process that can be thought of as a probability distribution whose domain is itself a random distribution...
(a type of non-parametric
Non-parametric statistics
In statistics, the term non-parametric statistics has at least two different meanings:The first meaning of non-parametric covers techniques that do not rely on data belonging to any particular distribution. These include, among others:...
probability distribution
Probability distribution
In probability theory, a probability mass, probability density, or probability distribution is a function that describes the probability of a random variable taking certain values....
). To allow the sharing of topics across classes, each of these Dirichlet processes is modeled as a sample from another 損arent?Dirichlet process. HDP was first described by Teh et al. in 2005.
Initialization
The dataset must be initialized, or seeded with an original batch of images which serve as good exemplars of the object category to be learned. These can be gathered automatically, using the first page or so of images returned by the search engine (which tend to be better than the subsequent images). Alternatively, the initial images can be gathered by hand.Model learning
To learn the various parameters of the HDP in an incremental manner, Gibbs samplingGibbs sampling
In statistics and in statistical physics, Gibbs sampling or a Gibbs sampler is an algorithm to generate a sequence of samples from the joint probability distribution of two or more random variables...
is used over the latent variables. It is carried out after each new set of images is incorporated into the dataset. Gibbs sampling involves repeatedly sampling from a set of random variables in order to approximate their distributions. Sampling involves generating a value for the random variable in question, based on the state of the other random variables on which it is dependent. Given sufficient samples, a reasonable approximation of the value can be achieved.
Classification
At each iteration, and can be obtained from model learned after the previous round of Gibbs sampling, where is a topic, is a category, and is a single visual word. The likelihood of an image being in a certain class, then, is:This is computed for each new candidate image per iteration. The image is classified as belonging to the category with the highest likelihood.
Addition to the dataset and "cache set"
In order to qualify for incorporation into the dataset, however, an image must satisfy a stronger condition:Where
and are foreground (object) and background categories, respectively, and the ratio of constants describes the risk of accepting false positives and false negatives. They are adjusted automatically at every iteration, with the cost of a false positive set higher than that of a false negative. This ensures that a better dataset is collected.Once an image is accepted by meeting the above criterion and incorporated into the dataset, however, it needs to meet another criterion before it is incorporated into the 揷ache set敆the set of images to be used for training. This set is intended to be a diverse subset of the set of accepted images. If the model were trained on all accepted images, it might become more and more highly specialized, only accepting images very similar to previous ones.
Performance
Performance of the OPTIMOL method is defined by three factors:- Ability to collect images: OPTIMOL, it is found, can automatically collect large numbers of good images from the web. The size of the OPTIMOL-retrieved image sets surpass that of large human-labeled image sets for the same categories, such as those found in Caltech 101Caltech 101Caltech 101 is a dataset of digital images created in September, 2003, compiled by Fei-Fei Li, Marco Andreetto, Marc 'Aurelio Ranzato and Pietro Perona at the California Institute of Technology. It is intended to facilitate Computer Vision research and techniques. It is most applicable to...
.
- Classification accuracy: Classification accuracy was compared to the accuracy displayed by the classifier yielded by the pLSA methods discussed earlier. It was discovered that OPTIMOL achieved slightly higher accuracy, obtaining 74.8% accuracy on 7 object categories, as compared to 72.0%.
- Comparison with batch learning: An important question to address is whether OPTIMOL's incremental learning gives it an advantage over traditional batch learning methods, when everything else about the model is held constant. When the classifier learns incrementally, by selecting the next images based on what it learned from the previous ones, three important results are observed:
- Incremental learning allows OPTIMOL to collect a better dataset
- Incremental learning allows OPTIMOL to learn faster (by discarding irrelevant images)
- Incremental learning does not negatively affect the ROC curve of the classifier; in fact, incremental learning yielded an improvement
Object categorization in content-based image retrieval
Typically, image searches only make use of text associated with images. The problem of content-based image retrievalContent-based image retrieval
Content-based image retrieval , also known as query by image content and content-based visual information retrieval is the application of computer vision techniques to the image retrieval problem, that is, the problem of searching for digital images in large databases....
is that of improving search results by taking into account visual information contained in the images themselves. Several CBIR methods make use of classifiers trained on image search results, to refine the search. In other words, object categorization from image search is one component of the system. OPTIMOL, for example, uses a classifier trained on images collected during previous iterations to select additional images for the returned dataset.
Examples of CBIR methods that model object categories from image search are:
- Fergus et al., 2004
- Berg and Forsyth, 2006
- Yanai and Barnard, 2006
See also
- Probabilistic latent semantic analysisProbabilistic latent semantic analysisProbabilistic latent semantic analysis , also known as probabilistic latent semantic indexing is a statistical technique for the analysis of two-mode and co-occurrence data. PLSA evolved from latent semantic analysis, adding a sounder probabilistic model...
- Latent Dirichlet allocationLatent Dirichlet allocationIn statistics, latent Dirichlet allocation is a generative model that allows sets of observations to be explained by unobserved groups that explain why some parts of the data are similar...
- Machine learningMachine learningMachine learning, a branch of artificial intelligence, is a scientific discipline concerned with the design and development of algorithms that allow computers to evolve behaviors based on empirical data, such as from sensor data or databases...
- Bag of words modelBag of words modelThe bag-of-words model is a simplifying assumption used in natural language processing and information retrieval. In this model, a text is represented as an unordered collection of words, disregarding grammar and even word order.The bag-of-words model is used in some methods of document...
- Content-based image retrievalContent-based image retrievalContent-based image retrieval , also known as query by image content and content-based visual information retrieval is the application of computer vision techniques to the image retrieval problem, that is, the problem of searching for digital images in large databases....