

Dirichlet process
Encyclopedia
In probability theory
, a Dirichlet process is a stochastic process
that can be thought of as a probability distribution
whose domain is itself a random distribution. That is, given a Dirichlet process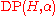 , where
, where  (the base distribution or base measure) is an arbitrary distribution and
(the base distribution or base measure) is an arbitrary distribution and  (the concentration parameter
(the concentration parameter
) is a positive real number, a draw from will return a random distribution (the output distribution) containing values drawn from
will return a random distribution (the output distribution) containing values drawn from  . That is, the support
. That is, the support
of the output distribution is the same as the base distribution. The output distribution will be discrete, meaning that individual values drawn from the distribution will sometimes repeat themselves even if the base distribution is continuous (i.e., if two different draws from the base distribution will be distinct with probability one). The extent to which values will repeat is determined by , with higher values causing less repetition. If the base distribution is continuous, so that separate draws from it always return distinct values, then the infinite set of probabilities corresponding to the frequency of each possible value that the output distribution can return are distributed according to a stick-breaking process.
, with higher values causing less repetition. If the base distribution is continuous, so that separate draws from it always return distinct values, then the infinite set of probabilities corresponding to the frequency of each possible value that the output distribution can return are distributed according to a stick-breaking process.
Note that the Dirichlet process is a stochastic process
, meaning that technically speaking it is an infinite sequence of random variables, rather than a single random distribution. The relation between the two is as follows. Consider the Dirichlet process as defined above, as a distribution over random distributions, and call this process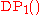 . We can call this the distribution-centered view of the Dirichlet process. First, draw a random output distribution from this process, and then consider an infinite sequence of random variables representing values drawn from this distribution. Note that, conditioned on the output distribution, the variables are independent identically distributed. Now, consider instead the distribution of the random variables that results from marginalizing out (integrating over) the random output distribution. (This makes all the variables dependent on each other. However, they are still exchangeable, meaning that the marginal distribution of one variable is the same as that of all other variables. That is, they are "identically distributed" but not "independent".) The resulting infinite sequence of random variables with the given marginal distributions is another view onto the Dirichlet process, denoted here
. We can call this the distribution-centered view of the Dirichlet process. First, draw a random output distribution from this process, and then consider an infinite sequence of random variables representing values drawn from this distribution. Note that, conditioned on the output distribution, the variables are independent identically distributed. Now, consider instead the distribution of the random variables that results from marginalizing out (integrating over) the random output distribution. (This makes all the variables dependent on each other. However, they are still exchangeable, meaning that the marginal distribution of one variable is the same as that of all other variables. That is, they are "identically distributed" but not "independent".) The resulting infinite sequence of random variables with the given marginal distributions is another view onto the Dirichlet process, denoted here
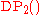 . We can call this the process-centered view of the Dirichlet process. The conditional distribution
. We can call this the process-centered view of the Dirichlet process. The conditional distribution
of one variable given all the others, or given all previous variables, is defined by the Chinese restaurant process (see below).
Another way to think of a Dirichlet process is as an infinite-dimensional generalization of the Dirichlet distribution. The Dirichlet distribution returns a finite-dimensional set of probabilities (for some size , specified by the parameters of the distribution), all of which sum to 1. This can be thought of as a finite-dimensional discrete distribution; i.e. a Dirichlet distribution can be thought of as a distribution over
, specified by the parameters of the distribution), all of which sum to 1. This can be thought of as a finite-dimensional discrete distribution; i.e. a Dirichlet distribution can be thought of as a distribution over  -dimensional discrete distributions. Imagine generalizing a symmetric Dirichlet distribution, defined by a dimension
-dimensional discrete distributions. Imagine generalizing a symmetric Dirichlet distribution, defined by a dimension  and concentration parameter
and concentration parameter 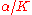 , to an infinite set of probabilities; the resulting distribution over infinite-dimensional discrete distributions is called the stick-breaking process (see below). Imagine then using this set of probabilities to create an infinite-dimensional mixture model
, to an infinite set of probabilities; the resulting distribution over infinite-dimensional discrete distributions is called the stick-breaking process (see below). Imagine then using this set of probabilities to create an infinite-dimensional mixture model
, with each separate probability from the set associated with a mixture component, and the value of each component drawn separately from a base distribution ; then draw an infinite number of samples from this mixture model. The infinite set of random variables corresponding to the marginal distribution of these samples is a Dirichlet process with parameters
; then draw an infinite number of samples from this mixture model. The infinite set of random variables corresponding to the marginal distribution of these samples is a Dirichlet process with parameters  and
and  .
.
The Dirichlet process was formally introduced by Thomas Ferguson in 1973.
:
Probability theory
Probability theory is the branch of mathematics concerned with analysis of random phenomena. The central objects of probability theory are random variables, stochastic processes, and events: mathematical abstractions of non-deterministic events or measured quantities that may either be single...
, a Dirichlet process is a stochastic process
Stochastic process
In probability theory, a stochastic process , or sometimes random process, is the counterpart to a deterministic process...
that can be thought of as a probability distribution
Probability distribution
In probability theory, a probability mass, probability density, or probability distribution is a function that describes the probability of a random variable taking certain values....
whose domain is itself a random distribution. That is, given a Dirichlet process
, where (the base distribution or base measure) is an arbitrary distribution and (the concentration parameterConcentration parameter
In probability theory and statistics, a concentration parameter is a special kind of numerical parameter of a parametric family of probability distributions...
) is a positive real number, a draw from
will return a random distribution (the output distribution) containing values drawn from . That is, the supportSupport (mathematics)
In mathematics, the support of a function is the set of points where the function is not zero, or the closure of that set . This concept is used very widely in mathematical analysis...
of the output distribution is the same as the base distribution. The output distribution will be discrete, meaning that individual values drawn from the distribution will sometimes repeat themselves even if the base distribution is continuous (i.e., if two different draws from the base distribution will be distinct with probability one). The extent to which values will repeat is determined by
, with higher values causing less repetition. If the base distribution is continuous, so that separate draws from it always return distinct values, then the infinite set of probabilities corresponding to the frequency of each possible value that the output distribution can return are distributed according to a stick-breaking process.Note that the Dirichlet process is a stochastic process
Stochastic process
In probability theory, a stochastic process , or sometimes random process, is the counterpart to a deterministic process...
, meaning that technically speaking it is an infinite sequence of random variables, rather than a single random distribution. The relation between the two is as follows. Consider the Dirichlet process as defined above, as a distribution over random distributions, and call this process
. We can call this the distribution-centered view of the Dirichlet process. First, draw a random output distribution from this process, and then consider an infinite sequence of random variables representing values drawn from this distribution. Note that, conditioned on the output distribution, the variables are independent identically distributed. Now, consider instead the distribution of the random variables that results from marginalizing out (integrating over) the random output distribution. (This makes all the variables dependent on each other. However, they are still exchangeable, meaning that the marginal distribution of one variable is the same as that of all other variables. That is, they are "identically distributed" but not "independent".) The resulting infinite sequence of random variables with the given marginal distributions is another view onto the Dirichlet process, denoted here. We can call this the process-centered view of the Dirichlet process. The conditional distributionConditional distribution
Given two jointly distributed random variables X and Y, the conditional probability distribution of Y given X is the probability distribution of Y when X is known to be a particular value...
of one variable given all the others, or given all previous variables, is defined by the Chinese restaurant process (see below).
Another way to think of a Dirichlet process is as an infinite-dimensional generalization of the Dirichlet distribution. The Dirichlet distribution returns a finite-dimensional set of probabilities (for some size
, specified by the parameters of the distribution), all of which sum to 1. This can be thought of as a finite-dimensional discrete distribution; i.e. a Dirichlet distribution can be thought of as a distribution over -dimensional discrete distributions. Imagine generalizing a symmetric Dirichlet distribution, defined by a dimension and concentration parameter , to an infinite set of probabilities; the resulting distribution over infinite-dimensional discrete distributions is called the stick-breaking process (see below). Imagine then using this set of probabilities to create an infinite-dimensional mixture modelMixture model
In statistics, a mixture model is a probabilistic model for representing the presence of sub-populations within an overall population, without requiring that an observed data-set should identify the sub-population to which an individual observation belongs...
, with each separate probability from the set associated with a mixture component, and the value of each component drawn separately from a base distribution
; then draw an infinite number of samples from this mixture model. The infinite set of random variables corresponding to the marginal distribution of these samples is a Dirichlet process with parameters and .The Dirichlet process was formally introduced by Thomas Ferguson in 1973.
Introduction
Consider a simple mixture modelMixture model
In statistics, a mixture model is a probabilistic model for representing the presence of sub-populations within an overall population, without requiring that an observed data-set should identify the sub-population to which an individual observation belongs...
:
-
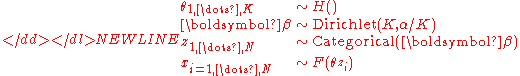
This is a basic generative modelGenerative modelIn probability and statistics, a generative model is a model for randomly generating observable data, typically given some hidden parameters. It specifies a joint probability distribution over observation and label sequences...
where the observations are distributed according to a mixture of
are distributed according to a mixture of  components, where each component is distributed according to a single parametric familyParametric familyIn mathematics and its applications, a parametric family or a parameterized family is a family of objects whose definitions depend on a set of parameters....
components, where each component is distributed according to a single parametric familyParametric familyIn mathematics and its applications, a parametric family or a parameterized family is a family of objects whose definitions depend on a set of parameters....
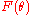 but where different components have different values of
but where different components have different values of 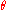 , which is drawn in turn from a distribution
, which is drawn in turn from a distribution  . Typically,
. Typically,  will be the conjugate priorConjugate priorIn Bayesian probability theory, if the posterior distributions p are in the same family as the prior probability distribution p, the prior and posterior are then called conjugate distributions, and the prior is called a conjugate prior for the likelihood...
will be the conjugate priorConjugate priorIn Bayesian probability theory, if the posterior distributions p are in the same family as the prior probability distribution p, the prior and posterior are then called conjugate distributions, and the prior is called a conjugate prior for the likelihood...
distribution of . In addition, the prior probabilityPrior probabilityIn Bayesian statistical inference, a prior probability distribution, often called simply the prior, of an uncertain quantity p is the probability distribution that would express one's uncertainty about p before the "data"...
. In addition, the prior probabilityPrior probabilityIn Bayesian statistical inference, a prior probability distribution, often called simply the prior, of an uncertain quantity p is the probability distribution that would express one's uncertainty about p before the "data"...
of each component is specified by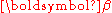 , which is a size-
, which is a size- vector of probabilities, all of which add up to 1.
vector of probabilities, all of which add up to 1.
For example, if the observations are apartment prices and the components represent different neighborhoods, then
components represent different neighborhoods, then  might be a Gaussian distribution with unknown meanMeanIn statistics, mean has two related meanings:* the arithmetic mean .* the expected value of a random variable, which is also called the population mean....
might be a Gaussian distribution with unknown meanMeanIn statistics, mean has two related meanings:* the arithmetic mean .* the expected value of a random variable, which is also called the population mean....
and unknown varianceVarianceIn probability theory and statistics, the variance is a measure of how far a set of numbers is spread out. It is one of several descriptors of a probability distribution, describing how far the numbers lie from the mean . In particular, the variance is one of the moments of a distribution...
, with the mean and variance specifying the distribution of prices in that neighborhood. Then the parameter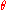 will be a vector of two values, a mean drawn from a Gaussian distribution and a variance drawn from an inverse gamma distribution, which are the conjugate priors of the mean and variance, respectively, of a Gaussian distribution.
will be a vector of two values, a mean drawn from a Gaussian distribution and a variance drawn from an inverse gamma distribution, which are the conjugate priors of the mean and variance, respectively, of a Gaussian distribution.
Meanwhile, if the observations are words and the components represent different topics, then
components represent different topics, then  might be a categorical distributionCategorical distributionIn probability theory and statistics, a categorical distribution is a probability distribution that describes the result of a random event that can take on one of K possible outcomes, with the probability of each outcome separately specified...
might be a categorical distributionCategorical distributionIn probability theory and statistics, a categorical distribution is a probability distribution that describes the result of a random event that can take on one of K possible outcomes, with the probability of each outcome separately specified...
over a vocabulary of size , with unknown frequencies of each word in the vocabulary, specifying the distribution of words in each particular topic. Then the parameter
, with unknown frequencies of each word in the vocabulary, specifying the distribution of words in each particular topic. Then the parameter 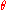 will be a vector of
will be a vector of  values, each representing a probability and all summing to one, drawn from a Dirichlet distribution, which is the conjugate prior of the categorical distribution.
values, each representing a probability and all summing to one, drawn from a Dirichlet distribution, which is the conjugate prior of the categorical distribution.
Now imagine we consider the limit as . Conceptually this means that we have no idea how many components are present. The result will be as follows:
. Conceptually this means that we have no idea how many components are present. The result will be as follows:
-
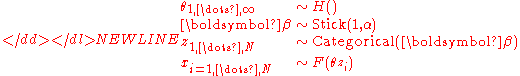
In this model, conceptually speaking there are an infinite number of components, each with a separate parameter value, and a correspondingly infinite number of prior probabilities for each component, drawn from a stick-breaking process (see section below). Note that a practical application of such a model would not actually store an infinite number of components. Instead, it would generate the component prior probabilities one at a time from the stick-breaking process, which by construction tends to return the largest probability values first. As each component probability is drawn, a corresponding parameter value is also drawn. At any one time, some of the prior probability mass will be assigned to components and some unassigned. To generate a new observation, a random number between 0 and 1 is drawn uniformly, and if it lands in the unassigned mass, new components are drawn as necessary (each one reducing the amount of unassigned mass) until enough mass has been allocated to place this number in an existing component. Each time a new component probability is generated by the stick-breaking process, a corresponding parameter value is drawn from .
.
Sometimes, the stick-breaking process is denoted as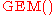 , after the authors of this process, instead of
, after the authors of this process, instead of 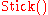 .
.
Another view of this model comes from looking back at the finite-dimensional mixture model with mixing probabilities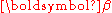 drawn from a Dirichlet distribution and considering the distribution of a particular component assignment
drawn from a Dirichlet distribution and considering the distribution of a particular component assignment  conditioned on all previous components, with the mixing probabilities integrated outMarginal distributionIn probability theory and statistics, the marginal distribution of a subset of a collection of random variables is the probability distribution of the variables contained in the subset. The term marginal variable is used to refer to those variables in the subset of variables being retained...
conditioned on all previous components, with the mixing probabilities integrated outMarginal distributionIn probability theory and statistics, the marginal distribution of a subset of a collection of random variables is the probability distribution of the variables contained in the subset. The term marginal variable is used to refer to those variables in the subset of variables being retained...
. Note that, conditioned on a particular value of , each
, each  is independent of the others, but marginalizing over
is independent of the others, but marginalizing over 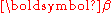 introduces dependencies among the component assignments. It can be shown that
introduces dependencies among the component assignments. It can be shown that

where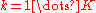 is a particular value of
is a particular value of  and
and 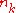 is the number of times a topic assignment in the set
is the number of times a topic assignment in the set  has the value
has the value 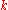 , i.e. probability of assigning an observation to a particular component is roughly proportional to the number of previous observations already assigned to this component.
, i.e. probability of assigning an observation to a particular component is roughly proportional to the number of previous observations already assigned to this component.
Now consider the limit as . For a particular previously observed component
. For a particular previously observed component 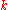 ,
,
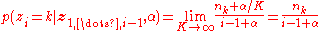
That is, the probability of seeing an previously observed component is directly proportional to the number of times the component has already been seen. This is often expressed as the rich get richer.
For an unseen component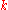 ,
,  , and as
, and as  the probability of seeing this component goes to 0. However, the number of unseen components approaches infinity. Consider instead the set of all unseen components
the probability of seeing this component goes to 0. However, the number of unseen components approaches infinity. Consider instead the set of all unseen components . Note that, if there are
. Note that, if there are 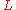 components seen so far,
components seen so far, 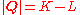 . Then, consider the probability of seeing any of these components:
. Then, consider the probability of seeing any of these components:
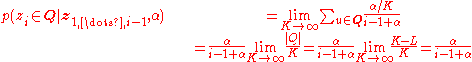
In other words:
- The probability of seeing an already-seen component is proportional to the number of times that component has been seen.
- The probability of seeing any unseen component is proportional to the concentration parameter
 .
.
This process is termed a Chinese restaurant process (CRP). In terms of the CRP, the infinite-dimensional model can equivalently be written:
-
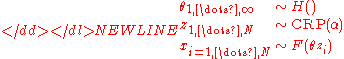
Note that we have marginalized out the mixing probabilities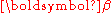 , and thereby produced a more compact representation of the model.
, and thereby produced a more compact representation of the model.
Now imagine further that we also marginalize out the component assignments , and instead we look directly at the distribution of
, and instead we look directly at the distribution of 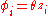 . Then, we can write the model directly in terms of the Dirichlet process:
. Then, we can write the model directly in terms of the Dirichlet process:
-
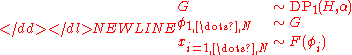
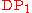 represents one view (the distribution-centered view) of the Dirichlet process as producing a random, infinite-dimensional discrete distribution
represents one view (the distribution-centered view) of the Dirichlet process as producing a random, infinite-dimensional discrete distribution  with values drawn from
with values drawn from  .
.
An alternative view of the Dirichlet process (the process-centered view), adhering more closely to its definition as a stochastic processStochastic processIn probability theory, a stochastic process , or sometimes random process, is the counterpart to a deterministic process...
, sees it as directly producing an infinite stream of values. Notating this view as
values. Notating this view as 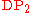 , we can write the model as
, we can write the model as
-
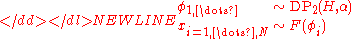
In this view, although the Dirichet process generates an infinite stream of parameter values, we only care about the first N values. Note that some of these values will be the same as previously seen values, in a "rich get richer" scheme, as determined by the Chinese restaurant process.
Formal definition
A Dirichlet process over a set S is a stochastic processStochastic processIn probability theory, a stochastic process , or sometimes random process, is the counterpart to a deterministic process...
whose sample path (i.e. an infinite-dimensional set of random variates drawn from the process) is a probability distribution on S. The finite dimensional distributions are from the Dirichlet distribution: If H is a finite measureMeasure (mathematics)In mathematical analysis, a measure on a set is a systematic way to assign to each suitable subset a number, intuitively interpreted as the size of the subset. In this sense, a measure is a generalization of the concepts of length, area, and volume...
on S, is a positive real number and X is a sample path drawn from a Dirichlet process, written as
is a positive real number and X is a sample path drawn from a Dirichlet process, written as
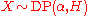
then for any partitionPartition of a setIn mathematics, a partition of a set X is a division of X into non-overlapping and non-empty "parts" or "blocks" or "cells" that cover all of X...
of S, say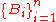 , we have that
, we have that

The Chinese restaurant process
As shown above, a simple distribution, the so-called Chinese restaurant process, results from considering the conditional distribution of one component assignment given all previous ones in a Dirichlet distribution mixture modelMixture modelIn statistics, a mixture model is a probabilistic model for representing the presence of sub-populations within an overall population, without requiring that an observed data-set should identify the sub-population to which an individual observation belongs...
with components, and then taking the limit as
components, and then taking the limit as  goes to infinity. It can be shown, using the above formal definition of the Dirichlet process and considering the process-centered view of the process, that the conditional distribution of the component assignment of one sample from the process given all previous samples follows a Chinese restaurant process.
goes to infinity. It can be shown, using the above formal definition of the Dirichlet process and considering the process-centered view of the process, that the conditional distribution of the component assignment of one sample from the process given all previous samples follows a Chinese restaurant process.
Suppose that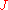 samples,
samples, 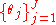 have already been obtained. According to the Chinese Restaurant Process, the
have already been obtained. According to the Chinese Restaurant Process, the  sample should be drawn from
sample should be drawn from

where is an atomic distribution centered on
is an atomic distribution centered on  . Interpreting this, two properties are clear:
. Interpreting this, two properties are clear:
- Even if
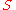 is a countable set, there is a finite probability that two samples will have exactly the same value. Samples from a Dirichlet process are therefore discrete.
is a countable set, there is a finite probability that two samples will have exactly the same value. Samples from a Dirichlet process are therefore discrete. - The Dirichlet process exhibits a self-reinforcing property; the more often a given value has been sampled in the past, the more likely it is to be sampled again.
The name "Chinese restaurant process" is derived from the following analogy: imagine an infinitely large restaurant containing an infinite number of tables, and able to serve an infinite number of dishes. The restaurant in question operates a somewhat unusual seating policy whereby new diners are seated either at a currently occupied table with probability proportional to the number of guests already seated there, or at an empty table with probability proportional to a constant. Guests who sit at an occupied table must order the same dish as those currently seated, whereas guests allocated a new table are served a dish at random according to the chef's taste. The distribution of dishes after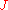 guests are served is a sample drawn as described above. The Chinese Restaurant Process is related to the Polya UrnUrn problemIn probability and statistics, an urn problem is an idealized mental exercise in which some objects of real interest are represented as colored balls in an urn or other container....
guests are served is a sample drawn as described above. The Chinese Restaurant Process is related to the Polya UrnUrn problemIn probability and statistics, an urn problem is an idealized mental exercise in which some objects of real interest are represented as colored balls in an urn or other container....
sampling scheme for finite Dirichlet distributions.
The stick-breaking process
A third approach to the Dirichlet process is provided by the so-called stick-breaking process, which can be used to provide a constructive algorithm (the stick-breaking construction) for generating a Dirichlet process. Let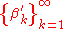 be a set of random variables such that
be a set of random variables such that

where is the normalisation constant for the measure
is the normalisation constant for the measure  , so that
, so that  . Define
. Define 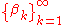 according to
according to
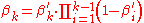
and let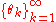 be a set of samples from
be a set of samples from  . The distribution given by the density
. The distribution given by the density 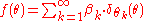 (where
(where 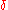 is the Dirac delta functionDirac delta functionThe Dirac delta function, or δ function, is a generalized function depending on a real parameter such that it is zero for all values of the parameter except when the parameter is zero, and its integral over the parameter from −∞ to ∞ is equal to one. It was introduced by theoretical...
is the Dirac delta functionDirac delta functionThe Dirac delta function, or δ function, is a generalized function depending on a real parameter such that it is zero for all values of the parameter except when the parameter is zero, and its integral over the parameter from −∞ to ∞ is equal to one. It was introduced by theoretical...
), is then a sample from the corresponding Dirichlet process. This method provides an explicit construction of the non-parametric sample, and makes clear the fact that the samples are discrete.
The name 'stick-breaking' comes from the interpretation of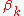 as the length of the piece of a unit-length stick assigned to the kth value. After the first k − 1 values have their portions assigned, the length of the remainder of the stick,
as the length of the piece of a unit-length stick assigned to the kth value. After the first k − 1 values have their portions assigned, the length of the remainder of the stick, 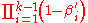 ,
,
is broken according to a sample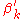 from a beta distribution. In this analogy,
from a beta distribution. In this analogy, 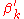 indicates the portion of the remainder to be assigned to the k-th value.
indicates the portion of the remainder to be assigned to the k-th value.
The smaller is, the less of the stick will be left for subsequent values (on average).
is, the less of the stick will be left for subsequent values (on average).
The Polya urn scheme
Yet another way to visualize the Dirichlet process and Chinese restaurant process is as a modified Polya urn scheme. Imagine that we start with an urn filled with black balls. Then we proceed as follows:
black balls. Then we proceed as follows:
- Each time we need an observation, we draw a ball from the urn.
- If the ball is black, we generate a new (non-black) color uniformly, label a new ball this color, drop the new ball into the urn along with the ball we drew, and return the color we generated.
- Otherwise, label a new ball with the color of the ball we drew, drop the new ball into the urn along with the ball we drew, and return the color we observed.
The resulting distribution over colors is the same as the distribution over tables in the Chinese restaurant process. Furthermore, when we draw a black ball, if rather than generating a new color, we instead pick a random value from a base distribution and use that value to label the new ball, the resulting distribution over labels will be the same as the distribution over values in a Dirichlet process.
and use that value to label the new ball, the resulting distribution over labels will be the same as the distribution over values in a Dirichlet process.
Applications of the Dirichlet process
Dirichlet processes are frequently used in Bayesian nonparametric statisticsNon-parametric statisticsIn statistics, the term non-parametric statistics has at least two different meanings:The first meaning of non-parametric covers techniques that do not rely on data belonging to any particular distribution. These include, among others:...
. "Nonparametric" here does not mean a parameter-less model, rather a model in which representations grow as more data are observed. Bayesian nonparametric models have gained considerable popularity in the field of machine learning because of the above-mentioned flexibility, especially in unsupervised learningUnsupervised learningIn machine learning, unsupervised learning refers to the problem of trying to find hidden structure in unlabeled data. Since the examples given to the learner are unlabeled, there is no error or reward signal to evaluate a potential solution...
. In a Bayesian nonparametric model, the prior and posterior distributions are not parametric distributions, but stochastic processes. The fact that the Dirichlet distribution is a probability distribution on the simplexSimplexIn geometry, a simplex is a generalization of the notion of a triangle or tetrahedron to arbitrary dimension. Specifically, an n-simplex is an n-dimensional polytope which is the convex hull of its n + 1 vertices. For example, a 2-simplex is a triangle, a 3-simplex is a tetrahedron,...
of non-negative numbers that sum to one makes it a good candidate to model distributions of distributions or distributions of functions. Additionally, the non-parametric nature of this model makes it an ideal candidate for clustering problems where the distinct number of clusters is unknown beforehand.
As draws from a Dirichlet process are discrete, an important use is as a prior probabilityPrior probabilityIn Bayesian statistical inference, a prior probability distribution, often called simply the prior, of an uncertain quantity p is the probability distribution that would express one's uncertainty about p before the "data"...
in infinite mixture models. In this case,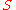 is the parametric set of component distributions. The generative process is therefore that a sample is drawn from a Dirichlet process, and for each data point in turn a value is drawn from this sample distribution and used as the component distribution for that data point. The fact that there is no limit to the number of distinct components which may be generated makes this kind of model appropriate for the case when the number of mixture components is not well-defined in advance. For example, the infinite mixture of Gaussians model .
is the parametric set of component distributions. The generative process is therefore that a sample is drawn from a Dirichlet process, and for each data point in turn a value is drawn from this sample distribution and used as the component distribution for that data point. The fact that there is no limit to the number of distinct components which may be generated makes this kind of model appropriate for the case when the number of mixture components is not well-defined in advance. For example, the infinite mixture of Gaussians model .
The infinite nature of these models also lends them to natural language processingNatural language processingNatural language processing is a field of computer science and linguistics concerned with the interactions between computers and human languages; it began as a branch of artificial intelligence....
applications, where it is often desirable to treat the vocabulary as an infinite, discrete set.
Related distributions
- The Pitman–Yor distribution (also known as the 'two-parameter Poisson-Dirichlet process') is a generalisation of the Dirichlet process.
- The hierarchical Dirichlet process extends the ordinary Dirichlet process for modelling grouped data.
External links
- Introduction to the Dirichlet Distribution and Related Processes by Frigyik, Kapila and Gupta
- Yee Whye Teh's overview of Dirichlet processes
- Webpage for the NIPS 2003 workshop on non-parametric Bayesian methods
- Michael Jordan's NIPS 2005 tutorial: Nonparametric Bayesian Methods: Dirichlet Processes, Chinese Restaurant Processes and All That
- Peter Green's summary of construction of Dirichlet Processes
- Peter Green's paper on probabilistic models of Dirichlet Processes with implications for statistical modelling and analysis
- Zoubin Ghahramani's UAI 2005 tutorial on Nonparametric Bayesian methods
- GIMM software for performing cluster analysis using Infinite Mixture Models
- A Toy Example of Clustering using Dirichlet Process. by Zhiyuan Weng
- Even if
-
-
-