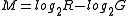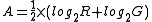Deoxyribonucleic acid is a nucleic acid that contains the genetic instructions used in the development and functioning of all known living organisms . The DNA segments that carry this genetic information are called genes, but other DNA sequences have structural purposes, or are involved in...
(target samples), which can provide data on relative gene expression levels (in the case of RNA) or gene copy number (for DNA). The data obtained from two-color DNA microarrays come in the form of fluorescent Red (Cy5) and Green (Cy3) dye intensities. One-color oligonucleotide arrays use only a single fluorescent dye.
Microarray data is often normalized within arrays to control for systematic biases in dye coupling and hybridization efficiencies, as well as other technical biases in the DNA probes and the print tip used to spot the array. By minimizing these systematic variations, true biological differences can be found. To determine whether normalization is needed, one can plot Cy5 (G) intensities against Cy3 (R) intensities and see whether the slope of the line is around 1. An improved method, which is basically a scaled, 45 degree rotation of the R vs. G plot is an MA-plot. The MA-plot is a plot of the distribution of the red/green intensity ratio ('M') plotted by the average intensity ('A'). M and A are defined by the following equations.
M is, therefore, the intensity ratio and A is the average intensity for a dot in the plot. MA plots are then used to visualize intensity-dependent ratio of raw microarray data. The MA plot uses M as the y-axis and A as the x-axis. The MA plot gives a quick overview of the distribution of the data. In many microarray gene expression experiments, the general assumption is that most of the genes would not see any change in their expression. Therefore the majority of the points on the y axis (M) would be located at 0, since Log(1) is 0. If this is not the case, then a normalization method such as LOESS
Loess
Loess is an aeolian sediment formed by the accumulation of wind-blown silt, typically in the 20–50 micrometre size range, twenty percent or less clay and the balance equal parts sand and silt that are loosely cemented by calcium carbonate...
should be applied to the data before statistical analysis.
The MA plot is the application of a Bland–Altman plot for visual representation of two channel DNA microarray
DNA microarray
A DNA microarray is a collection of microscopic DNA spots attached to a solid surface. Scientists use DNA microarrays to measure the expression levels of large numbers of genes simultaneously or to genotype multiple regions of a genome...
gene expression data which has been transformed onto the M and A scale.
Bioconductor is a free, open source and open development software project for the analysis and comprehension of genomic data generated by wet lab experiments in molecular biology....
R is a programming language and software environment for statistical computing and graphics. The R language is widely used among statisticians for developing statistical software, and R is widely used for statistical software development and data analysis....
, provide the facility for creating MA plots, these include affy (ma.plot, mva.pairs), limma (plotMA) and marray (maPlot)