
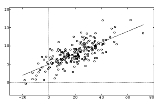
Linear regression
Overview
Statistics
Statistics is the study of the collection, organization, analysis, and interpretation of data. It deals with all aspects of this, including the planning of data collection in terms of the design of surveys and experiments....
, linear regression is an approach to modeling the relationship between a scalar variable y and one or more explanatory variables denoted X. The case of one explanatory variable is called simple regression. More than one explanatory variable is multiple regression.
In linear regression, data
Data
The term data refers to qualitative or quantitative attributes of a variable or set of variables. Data are typically the results of measurements and can be the basis of graphs, images, or observations of a set of variables. Data are often viewed as the lowest level of abstraction from which...
are modeled using linear functions, and unknown model parameters are estimated
Estimation theory
Estimation theory is a branch of statistics and signal processing that deals with estimating the values of parameters based on measured/empirical data that has a random component. The parameters describe an underlying physical setting in such a way that their value affects the distribution of the...
from the data.