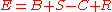Linear Belief Function
Encyclopedia
Linear Belief Function is an extension of the Dempster-Shafer theory
of belief functions to the case when variables of interest are continuous. Examples of such variables include financial asset prices, portfolio performance, and other antecedent and consequent variables. The theory was originally proposed by Arthur P. Dempster
in the context of Kalman Filters and later was reelaborated, refined, and applied to knowledge representation in artificial intelligence and decision making in finance and accounting by Liping Liu.
but we do not know its exact location; along some dimensions of the certainty hyperplane, we believe the true value could be anywhere from –∞ to +∞ and the probability of being at a particular location is described by a normal distribution; along other dimensions, our knowledge is vacuous, i.e., the true value is somewhere from –∞ to +∞ but the associated probability is unknown. As we know, a belief function in general is defined by a mass function over a class of focal elements, which may have nonempty intersections. A linear belief function is a special type of belief functions in the sense that its focal elements are exclusive, parallel sub-hyperplanes over the certainty hyperplane and its mass function is a normal distribution across the sub-hyperplanes.
Based on the above geometrical description, Shafer and Liu propose two mathematical representations of a LBF: a wide-sense inner product and a linear functional in the variable space, and as their duals over a hyperplane in the sample space. Monney proposes a still another structure called Gaussian hints. Although these representations are mathematically neat, they tend to be unsuitable for knowledge representation in expert systems.
In general, assume X is a vector of multiple normal variables with mean μ and covariance Σ. Then, the multivariate normal distribution can be equivalently represented as a moment matrix:
Dempster-Shafer theory
The Dempster–Shafer theory is a mathematical theory of evidence. It allows one to combine evidence from different sources and arrive at a degree of belief that takes into account all the available evidence. The theory was first developed by Arthur P...
of belief functions to the case when variables of interest are continuous. Examples of such variables include financial asset prices, portfolio performance, and other antecedent and consequent variables. The theory was originally proposed by Arthur P. Dempster
Arthur P. Dempster
Arthur Pentland Dempster is a Professor Emeritus in the Harvard University Department of Statistics. He was one of four faculty when the department was founded in 1957.He was a Putnam Fellow in 1951. He obtained his Ph.D. from Princeton University in 1956...
in the context of Kalman Filters and later was reelaborated, refined, and applied to knowledge representation in artificial intelligence and decision making in finance and accounting by Liping Liu.
Concept
A linear belief function intends to represent our belief regarding the location of the true value as follows: We are certain that the truth is on a so-called certainty hyperplaneHyperplane
A hyperplane is a concept in geometry. It is a generalization of the plane into a different number of dimensions.A hyperplane of an n-dimensional space is a flat subset with dimension n − 1...
but we do not know its exact location; along some dimensions of the certainty hyperplane, we believe the true value could be anywhere from –∞ to +∞ and the probability of being at a particular location is described by a normal distribution; along other dimensions, our knowledge is vacuous, i.e., the true value is somewhere from –∞ to +∞ but the associated probability is unknown. As we know, a belief function in general is defined by a mass function over a class of focal elements, which may have nonempty intersections. A linear belief function is a special type of belief functions in the sense that its focal elements are exclusive, parallel sub-hyperplanes over the certainty hyperplane and its mass function is a normal distribution across the sub-hyperplanes.
Based on the above geometrical description, Shafer and Liu propose two mathematical representations of a LBF: a wide-sense inner product and a linear functional in the variable space, and as their duals over a hyperplane in the sample space. Monney proposes a still another structure called Gaussian hints. Although these representations are mathematically neat, they tend to be unsuitable for knowledge representation in expert systems.
Knowledge Representation
A linear belief function can represent both logical and probabilistic knowledge for three types of variables: deterministic such as an observable or controllable, random whose distribution is normal, and vacuous on which no knowledge bears. Logical knowledge is represented by linear equations, or geometrically, a certainty hyperplane. Probabilistic knowledge is represented by a normal distribution across all parallel focal elements.In general, assume X is a vector of multiple normal variables with mean μ and covariance Σ. Then, the multivariate normal distribution can be equivalently represented as a moment matrix:
-
 .
.
If the distribution is non-degenerate, i.e., Σ has a full rank and its inverse exists, the moment matrix can be fully swept:
-

Except for normalization constant, the above equation completely determines the normal density function for X. Therefore,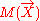 represents the probability distribution of X in the potential form.
represents the probability distribution of X in the potential form.
These two simple matrices allow us to represent three special cases of linear belief functions. First, for an ordinary normal probability distribution M(X) represents it. Second, suppose one makes a direct observation on X and obtains a value μ. In this case, since there is no uncertainty, both variance and covariance vanish, i.e., Σ = 0. Thus, a direct observation can be represented as:
-

Third, suppose one is completely ignorant about X. This is a very thorny case in Bayesian statistics since the density function does not exist. By using the fully swept moment matrix, we represent the vacuous linear belief functions as a zero matrix in the swept form follows:
-
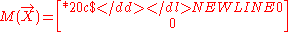
One way to understand the representation is to imagine complete ignorance as the limiting case when the variance of X approaches to ∞, where one can show that Σ−1 = 0 and hence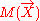 vanishes. However, the above equation is not the same as an improper prior or normal distribution with infinite variance. In fact, it does not correspond to any unique probability distribution. For this reason, a better way is to understand the vacuous linear belief functions as the neutral element for combination (see later).
vanishes. However, the above equation is not the same as an improper prior or normal distribution with infinite variance. In fact, it does not correspond to any unique probability distribution. For this reason, a better way is to understand the vacuous linear belief functions as the neutral element for combination (see later).
To represent the remaining three special cases, we need the concept of partial sweeping. Unlike a full sweeping, a partial sweeping is a transformation on a subset of variables. Suppose X and Y are two vectors of normal variables with the joint moment matrix:
-
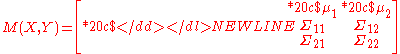
Then M(X, Y) may be partially swept. For example, we can define the partial sweeping on X as follows:
-
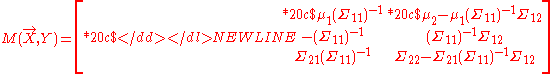
If X is one-dimensional, a partial sweeping replaces the variance of X by its negative inverse and multiplies the inverse with other elements. If X is multidimensional, the operation involves the inverse of the covariance matrix of X and other multiplications. A swept matrix obtained from a partial sweeping on a subset of variables can be equivalently obtained by a sequence of partial sweepings on each individual variable in the subset and the order of the sequence does not matter. Similarly, a fully swept matrix is the result of partial sweepings on all variables.
We can make two observations. First, after the partial sweeping on X, the mean vector and covariance matrix of X are respectively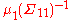 and
and 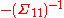 , which are the same as that of a full sweeping of the marginal moment matrix of X. Thus, the elements corresponding to X in the above partial sweeping equation represent the marginal distribution of X in potential form. Second, according to statistics,
, which are the same as that of a full sweeping of the marginal moment matrix of X. Thus, the elements corresponding to X in the above partial sweeping equation represent the marginal distribution of X in potential form. Second, according to statistics, 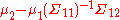 is the conditional mean of Y given X = 0;
is the conditional mean of Y given X = 0; 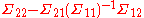 is the conditional covariance matrix of Y given X = 0; and
is the conditional covariance matrix of Y given X = 0; and 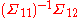 is the slope of the regression model of Y on X. Therefore, the elements corresponding to Y indices and the intersection of X and Y in
is the slope of the regression model of Y on X. Therefore, the elements corresponding to Y indices and the intersection of X and Y in 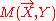 represents the conditional distribution of Y given X = 0.
represents the conditional distribution of Y given X = 0.
These semantics render the partial sweeping operation a useful method for manipulating multivariate normal distributions. They also form the basis of the moment matrix representations for the three remaining important cases of linear belief functions, including proper belief functions, linear equations, and linear regression models.
Proper Linear Belief Functions
For variables X and Y, assume there exists a piece of evidence justifying a normal distribution for variables Y while bearing no opinions for variables X. Also, assume that X and Y are not perfectly linearly related, i.e., their correlation is less than 1. This case involves a mix of an ordinary normal distribution for Y and a vacuous belief function for X. Thus, we represent it using a partially swept matrix as follows:
-
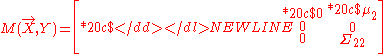
This is how we could understand the representation. Since we are ignorant on X, we use its swept form and set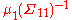 = 0 and
= 0 and 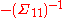 = 0. Since the correlation between X and Y is less than 1, the regression coefficient of X on Y approaches to 0 when the variance of X approaches to ∞. Therefore,
= 0. Since the correlation between X and Y is less than 1, the regression coefficient of X on Y approaches to 0 when the variance of X approaches to ∞. Therefore, 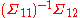 = 0. Similarly, one can prove that
= 0. Similarly, one can prove that 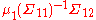 = 0 and
= 0 and 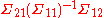 = 0.
= 0.
Linear Equations
Suppose X and Y are two row vectors, and Y = XA + b, where A and b are the coefficient matrices. We represent the equation using a partially swept matrix as follows:
-

We can understand the representation based on the fact that a linear equation contains two pieces of knowledge: (1) complete ignorance about all variables; and (2) a degenerate conditional distribution of dependent variables given independent variables. Since X is an independent vector in the equation, we are completely ignorant about it. Thus,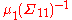 = 0 and
= 0 and 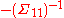 = 0. Given X = 0, Y is completely determined to be b. Thus, the conditional mean of Y is b and the conditional variance is 0. Also, the regression coefficient matrix is A.
= 0. Given X = 0, Y is completely determined to be b. Thus, the conditional mean of Y is b and the conditional variance is 0. Also, the regression coefficient matrix is A.
Note that the knowledge to be represented in linear equations is very close to that in a proper linear belief functions, except that the former assumes a perfect correlation between X and Y while the latter does not. This observation is interesting; it characterizes the difference between partial ignorance and linear equations in one parameter — correlation.
Linear Regression Models
A linear regression model is a more general and interesting case than previous ones. Suppose X and Y are two vectors and Y = XA + b + E, where A and b are the appropriate coefficient matrices and E is an independent white noise satisfying E ~ N(0, Σ). We represent the model as the following partially swept matrix:
-
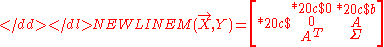
This linear regression model may be considered as the combination of two pieces of knowledge (see later), one is specified by the linear equation involving three variables X, Y, and E, and the other is a simple normal distribution of E, i.e., E ~ N(0, Σ). Alternatively, one may consider it similar to a linear equation, except that, given X = 0, Y is not completely determined to be b. Instead, the conditional mean of Y is b while the conditional variance is Σ. Note that, in this alternative interpretation, a linear regression model forms a basic building block for knowledge representation and is encoded as one moment matrix. Besides, the noise term E does not appear in the representation. Therefore, it makes the representation more efficient.
From representing the six special cases, we see a clear advantage of the moment matrix representation, i.e., it allows a unified representation for seemingly diverse types of knowledge, including linear equations, joint and conditional distributions, and ignorance. The unification is significant not only for knowledge representation in artificial intelligence but also for statistical analysis and engineering computation. For example, the representation treats the typical logical and probabilistic components in statistics — observations, distributions, improper priors (for Bayesian statistics), and linear equation models — not as separate concepts, but as manifestations of a single concept. It allows one to see the inner connections between these concepts or manifestations and to interplay them for computational purposes.
Knowledge Operations
There are two basic operations for making inferences in expert systems using linear belief functions: combination and marginalization. Combination corresponds to the integration of knowledge whereas marginalization corresponds to the coarsening of knowledge. Making an inference involves combining relevant knowledge into a full body of knowledge and then projecting the full body of knowledge to a partial domain, in which an inference question is to be answered.
Marginalization
Marginalization projects a linear belief function into one with fewer variables. Expressed as a moment matrix, it is simply the restriction of a nonswept moment matrix to a submatrix corresponding to the remaining variables. For example, for the joint distribution M(X, Y), its marginal to Y is:
-

When removing a variable, it is important that the variable has not been swept on in the corresponding moment matrix, i.e., it does not have an arrow sign above the variable. For example, projecting the matrix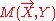 to Y produces:
to Y produces:
-
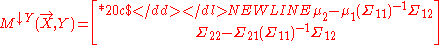
which is not the same linear belief function of Y. However, it is easy to see that removing any or all variables in Y from the partially swept matrix will still produce the correct result — a matrix representing the same function for the remaining variables.
To remove a variable that has been already swept on, we have to reverse the sweeping using partial or full reverse sweepings. Assume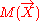 is a fully swept moment matrix,
is a fully swept moment matrix,
-

Then a full reverse sweeping of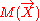 will recover the moment matrix M(X) as follows:
will recover the moment matrix M(X) as follows:
-

If a moment matrix is in a partially swept form, say
-
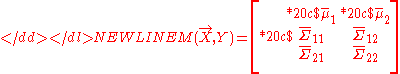
its partially reverse sweeping on X is defined as follows:
-
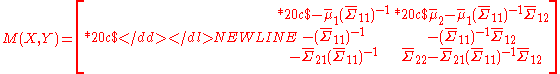
Reverse sweepings are similar to those of forward ones, except for a sign difference for some multiplications. However, forward and reverse sweepings are opposite operations. It can be easily shown that applying the fully reverse sweeping to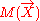 will recover the initial moment matrix M(X). It can also be proved that applying a partial reverse sweeping on X to the matrix
will recover the initial moment matrix M(X). It can also be proved that applying a partial reverse sweeping on X to the matrix 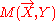 will recover the moment matrix M(X,Y). As a matter of fact, Liu proves that a moment matrix will be recovered through a reverse sweeping after a forward sweeping on the same set of variables. It can be also recovered through a forward sweeping after a reverse sweeping. Intuitively, a partial forward sweeping factorizes a joint into a marginal and a conditional, whereas a partial reverse sweeping multiplies them into a joint.
will recover the moment matrix M(X,Y). As a matter of fact, Liu proves that a moment matrix will be recovered through a reverse sweeping after a forward sweeping on the same set of variables. It can be also recovered through a forward sweeping after a reverse sweeping. Intuitively, a partial forward sweeping factorizes a joint into a marginal and a conditional, whereas a partial reverse sweeping multiplies them into a joint.
Combination
According to Dempster’s rule, the combination of belief functions may be expressed as the intersection of focal elements and the multiplication of probability density functions. Liping Liu applies the rule to linear belief functions in particular and obtains a formula of combination in terms of density functions. Later he proves a claim by Arthur P. DempsterArthur P. DempsterArthur Pentland Dempster is a Professor Emeritus in the Harvard University Department of Statistics. He was one of four faculty when the department was founded in 1957.He was a Putnam Fellow in 1951. He obtained his Ph.D. from Princeton University in 1956...
and reexpresses the formula as the sum of two fully swept matrices. Mathematically, assume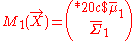 and
and 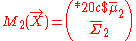 are two LBFs for the same vector of variables X. Then their combination is a fully swept matrix:
are two LBFs for the same vector of variables X. Then their combination is a fully swept matrix:
-
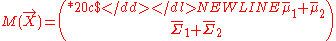
This above equation is often used for multiplying two normal distributions. Here we use it to define the combination of two linear belief functions, which include normal distributions as a special case. Also, note that a vacuous linear belief function (0 swept matrix) is the neutral element for combination. When applying the equation, we need to consider two special cases. First, if two matrices to be combined have different dimensions, then one or both matrices must be vacuously extended, i.e., assuming ignorance on the variables that are no present in each matrix. For example, if M1(X,Y) and M2(X,Z) are to be combined, we will first extend them into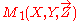 and
and 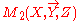 respectively such that
respectively such that 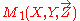 is ignorant about Z and
is ignorant about Z and 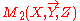 is ignorant about Y. The vacuous extension was initially proposed by Kong for discrete belief functions. Second, if a variable has zero variance, it will not permit a sweeping operation. In this case, we can pretend the variance to be an extremely small number, say ε, and perform the desired sweeping and combination. We can then apply a reverse sweeping to the combined matrix on the same variable and let ε approaches 0. Since zero variance means complete certainty about a variable, this ε-procedure will vanish ε terms in the final result.
is ignorant about Y. The vacuous extension was initially proposed by Kong for discrete belief functions. Second, if a variable has zero variance, it will not permit a sweeping operation. In this case, we can pretend the variance to be an extremely small number, say ε, and perform the desired sweeping and combination. We can then apply a reverse sweeping to the combined matrix on the same variable and let ε approaches 0. Since zero variance means complete certainty about a variable, this ε-procedure will vanish ε terms in the final result.
In general, to combine two linear belief functions, their moment matrices must be fully swept. However, one may combine a fully swept matrix with a partially swept one directly if the variables of the former matrix have been all swept on in the later. We can use the linear regression model — Y = XA + b + E — to illustrate the property. As we mentioned, the regression model may be considered as the combination of two pieces of knowledge: one is specified by the linear equation involving three variables X, Y, and E, and the other is a simple normal distribution of E, i.e., E ~ N(0, Σ). Let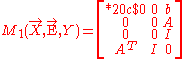 and
and 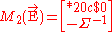 be their moment matrices respectively. Then the two matrices can be combined directly without sweeping
be their moment matrices respectively. Then the two matrices can be combined directly without sweeping 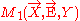 on Y first. The result of the combination is a partially swept matrix as follows:
on Y first. The result of the combination is a partially swept matrix as follows:
-
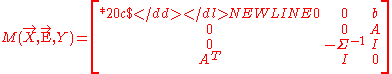
If we apply a reverse sweeping on E and then remove E from the matrix, we will obtain the same representation of the regression model.
Applications
We may use an audit problem to illustrate the three types of variables as follows. Suppose we want to audit the ending balance of accounts receivable (E). As we saw earlier, E is equal to the beginning balance (B) plus the sales (S) for the period minus the cash receipts (C) on the sales plus a residual (R) that represents insignificant sales returns and cash discounts. Thus, we can represent the logical relation as a linear equation:
Furthermore, if the auditor believes E and B are 100 thousand dollars on the average with a standard deviation 5 and the covariance 15, we can represent the belief as a multivariate normal distribution. If historical data indicate that the residual R is zero on the average with a standard deviation of 0.5 thousand dollars, we can summarize the historical data by normal distribution R ~ N(0, 0.52). If there is a direct observation on cash receipts, we can represent the evidence as an equation say, C = 50 (thousand dollars). If the auditor knows nothing about the beginning balance of accounts receivable, we can represent his or her ignorance by a vacuous LBF. Finally, if historical data suggests that, given cash receipts C, the sales S is on the average 8C + 4 and has a standard deviation 4 thousand dollars, we can represent the knowledge as a linear regression model S ~ N(4 + 8C, 16). -
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-