
Bootstrap aggregating
Encyclopedia
Bootstrap aggregating is a machine learning ensemble
meta-algorithm to improve machine learning
of statistical classification and regression
models in terms of stability and classification accuracy. It also reduces variance
and helps to avoid overfitting
. Although it is usually applied to decision tree
models, it can be used with any type of model. Bagging is a special case of the model averaging approach.
D of size n, bagging generates m new training sets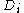 , each of size n ≤ n, by sampling
, each of size n ≤ n, by sampling
examples from D uniformly and with replacement. By sampling with replacement, it is likely that some examples will be repeated in
each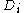 . If n=n, then for large n the set
. If n=n, then for large n the set 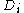 is expected to have 63.2% of the unique examples of D, the rest being duplicates. This kind of sample is known as a bootstrap sample. The m models are fitted using the above m bootstrap samples and combined by averaging the output (for regression) or voting (for classification).
is expected to have 63.2% of the unique examples of D, the rest being duplicates. This kind of sample is known as a bootstrap sample. The m models are fitted using the above m bootstrap samples and combined by averaging the output (for regression) or voting (for classification).
Since the method averages several predictors, it is not useful for improving linear models. Similarly, bagging does not improve very stable models like k nearest neighbors.
Rousseeuw and Leroy (1986) describe a data set concerning ozone
levels. The data are available via the classic data sets page. All computations were performed in R
.
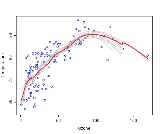
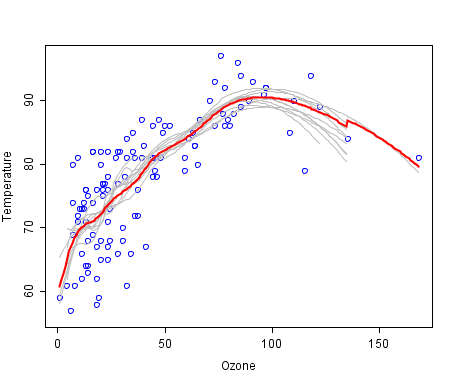
A scatter plot reveals an apparently non-linear relationship between temperature and ozone. One way to model the relationship is to use a loess
smoother. Such a smoother requires that a span parameter be chosen. In this example, a span of 0.5 was used.
One hundred bootstrap samples of the data were taken, and the LOESS smoother was fit to each sample. Predictions from these 100 smoothers were then made across the range of the data. The first 10 predicted smooth fits appear as grey lines in the figure below. The lines are clearly very wiggly and they overfit the data - a result of the span being too low.
The red line on the plot below represents the mean of the 100 smoothers. Clearly, the mean is more stable and there is less overfit
. This is the bagged predictor.
in 1994 to improve the classification by combining classifications of randomly generated training sets. See Breiman, 1994. Technical Report No. 421.
Ensemble learning
In statistics and machine learning, ensemble methods use multiple models to obtain better predictive performance than could be obtained from any of the constituent models....
meta-algorithm to improve machine learning
Machine learning
Machine learning, a branch of artificial intelligence, is a scientific discipline concerned with the design and development of algorithms that allow computers to evolve behaviors based on empirical data, such as from sensor data or databases...
of statistical classification and regression
Regression analysis
In statistics, regression analysis includes many techniques for modeling and analyzing several variables, when the focus is on the relationship between a dependent variable and one or more independent variables...
models in terms of stability and classification accuracy. It also reduces variance
Variance
In probability theory and statistics, the variance is a measure of how far a set of numbers is spread out. It is one of several descriptors of a probability distribution, describing how far the numbers lie from the mean . In particular, the variance is one of the moments of a distribution...
and helps to avoid overfitting
Overfitting
In statistics, overfitting occurs when a statistical model describes random error or noise instead of the underlying relationship. Overfitting generally occurs when a model is excessively complex, such as having too many parameters relative to the number of observations...
. Although it is usually applied to decision tree
Decision tree learning
Decision tree learning, used in statistics, data mining and machine learning, uses a decision tree as a predictive model which maps observations about an item to conclusions about the item's target value. More descriptive names for such tree models are classification trees or regression trees...
models, it can be used with any type of model. Bagging is a special case of the model averaging approach.
Description of the technique
Given a standard training setTraining set
A training set is a set of data used in various areas of information science to discover potentially predictive relationships. Training sets are used in artificial intelligence, machine learning, genetic programming, intelligent systems, and statistics...
D of size n, bagging generates m new training sets
, each of size n ≤ n, by samplingSampling (statistics)
In statistics and survey methodology, sampling is concerned with the selection of a subset of individuals from within a population to estimate characteristics of the whole population....
examples from D uniformly and with replacement. By sampling with replacement, it is likely that some examples will be repeated in
each
. If n=n, then for large n the set is expected to have 63.2% of the unique examples of D, the rest being duplicates. This kind of sample is known as a bootstrap sample. The m models are fitted using the above m bootstrap samples and combined by averaging the output (for regression) or voting (for classification).Since the method averages several predictors, it is not useful for improving linear models. Similarly, bagging does not improve very stable models like k nearest neighbors.
Example: Ozone data
This example is rather artificial, but illustrates the basic principles of bagging.Rousseeuw and Leroy (1986) describe a data set concerning ozone
Ozone
Ozone , or trioxygen, is a triatomic molecule, consisting of three oxygen atoms. It is an allotrope of oxygen that is much less stable than the diatomic allotrope...
levels. The data are available via the classic data sets page. All computations were performed in R
R (programming language)
R is a programming language and software environment for statistical computing and graphics. The R language is widely used among statisticians for developing statistical software, and R is widely used for statistical software development and data analysis....
.
A scatter plot reveals an apparently non-linear relationship between temperature and ozone. One way to model the relationship is to use a loess
Local regression
LOESS, or LOWESS , is one of many "modern" modeling methods that build on "classical" methods, such as linear and nonlinear least squares regression. Modern regression methods are designed to address situations in which the classical procedures do not perform well or cannot be effectively applied...
smoother. Such a smoother requires that a span parameter be chosen. In this example, a span of 0.5 was used.
One hundred bootstrap samples of the data were taken, and the LOESS smoother was fit to each sample. Predictions from these 100 smoothers were then made across the range of the data. The first 10 predicted smooth fits appear as grey lines in the figure below. The lines are clearly very wiggly and they overfit the data - a result of the span being too low.
The red line on the plot below represents the mean of the 100 smoothers. Clearly, the mean is more stable and there is less overfit
Overfitting
In statistics, overfitting occurs when a statistical model describes random error or noise instead of the underlying relationship. Overfitting generally occurs when a model is excessively complex, such as having too many parameters relative to the number of observations...
. This is the bagged predictor.
History
Bagging (Bootstrap aggregating) was proposed by Leo BreimanLeo Breiman
Leo Breiman was a distinguished statistician at the University of California, Berkeley. He was the recipient of numerous honors and awards, and was a member of the United States National Academy of Science....
in 1994 to improve the classification by combining classifications of randomly generated training sets. See Breiman, 1994. Technical Report No. 421.
See also
- BoostingBoostingBoosting is a machine learning meta-algorithm for performing supervised learning. Boosting is based on the question posed by Kearns: can a set of weak learners create a single strong learner? A weak learner is defined to be a classifier which is only slightly correlated with the true classification...
- Cross validation
- BootstrappingBootstrapping (statistics)In statistics, bootstrapping is a computer-based method for assigning measures of accuracy to sample estimates . This technique allows estimation of the sample distribution of almost any statistic using only very simple methods...
in statistics