In computer science, a binary search tree , which may sometimes also be called an ordered or sorted binary tree, is a node-based binary tree data structurewhich has the following properties:...
that is -competitive proposed by Erik D. Demaine, Dion Harmon, John Iacono, and Mihai Patrascu in 2004.
Overview
Tango trees were designed to surpass the usual binary search tree cost of operations. They perform basic operations such as searches in time. This optimization is achieved dynamically by adjusting the search tree structure after each search. They are similar in their dynamic behaviour to other types of structure like a Splay tree
Splay tree
A splay tree is a self-adjusting binary search tree with the additional property that recently accessed elements are quick to access again. It performs basic operations such as insertion, look-up and removal in O amortized time. For many sequences of nonrandom operations, splay trees perform...
however the competitive ratio is dramatically improved.
The approach is similar to the Greedy BST algorithm that while searching for an element rearranges the nodes on the search path to minimize the cost of future searches.
For Tango Trees the approach is a classic divide and conquer approach combined with a bring to top approach.
The main divide and conquer idea behind this data structure is to extract from the original tree a number of virtual smaller subtrees all with a normal O(log number of subtree elements) cost of access. These subtrees are dynamically balanced to offer the usual performance for data retrieval.
The bring to top approach is not done at the node level as much as at the subtree level which further improve competitiveness.
Once the original tree has been adjusted to include a collection of these subtrees, it is possible to greatly improve the cost of access of these subtrees. Both the Tango tree and these subtrees are a type of Self-balancing binary search tree
Self-balancing binary search tree
In computer science, a self-balancing binary search tree is any node based binary search tree that automatically keeps its height small in the face of arbitrary item insertions and deletions....
.
Tango tree achieves this outstanding competitive ratio by using a combination of augmentation of attributes in the data structure, a more elaborated algorithm and the use of other type of trees for some of its structure.
Similar Data Structures
Red Black tree, introduced by Bayer in 1972, having a competitive ratio
A splay tree is a self-adjusting binary search tree with the additional property that recently accessed elements are quick to access again. It performs basic operations such as insertion, look-up and removal in O amortized time. For many sequences of nonrandom operations, splay trees perform...
, introduced by Sleator and Tarjan in 1985, having a competitive ratio
In computer science, an AVL tree is a self-balancing binary search tree, and it was the first such data structure to be invented. In an AVL tree, the heights of the two child subtrees of any node differ by at most one. Lookup, insertion, and deletion all take O time in both the average and worst...
, introduced by Adelson and Landis in 1962, having a competitive ratio
Multi-splay tree, introduced by Sleator and Wang in 2006, having a competitive ratio
Advantages
Tango Trees offer unsurpassed competitive ratio retrieval for online data. Online data means that operations that are not known in advance before the data structure is created.
Outstanding search performance for a Tango tree relies on the fact that accessing nodes constantly updates the structure of the search trees. That way the searches are rerouted to searches in much shallower balanced trees.
Obviously, significantly faster access time constitutes an advantage for nearly all practical applications that offer searches as a use case. Dictionary searches like telephone directory search would be just one of the possible an examples.
Disadvantages
The Tango tree focuses on data searches on static data structures, and does not support deletions or insertions, so it might not be appropriate in every situation.
The Tango tree uses augmentation, meaning storing more data in a node than in a node of a plain binary search tree. Tango trees use bits. Although that is not a significant increase, it results in a bigger memory footprint.
It is a complex algorithm to implement like for instance splay tree
Splay tree
A splay tree is a self-adjusting binary search tree with the additional property that recently accessed elements are quick to access again. It performs basic operations such as insertion, look-up and removal in O amortized time. For many sequences of nonrandom operations, splay trees perform...
, and it also makes use of rarely used operations of Red-Black Tree
Red-black tree
A red–black tree is a type of self-balancing binary search tree, a data structure used in computer science, typically to implement associative arrays. The original structure was invented in 1972 by Rudolf Bayer and named "symmetric binary B-tree," but acquired its modern name in a paper in 1978 by...
.
Tango trees change when they are accessed in a 'read-only' manner (i.e. by find operations). This complicates the use of Tango trees in a multi-threaded environment.
It is believed that Tango Tree would work in a practical situation where a very large data set with strong spatial and temporal coherence fits in the memory.
Terminology and Concepts
There are several types of trees besides the Red-Black trees (RB) used as a base for all Tree structures:
Reference Trees
Example of reference tree:
Auxiliary Trees
Example of auxiliary tree:
As all trees are derived from RB trees so they are also [Binary Search Trees] with all their inherent behaviour.
Auxiliary trees can be considered sub-trees of the Tango Tree. Tango Trees are the actual employed trees while in production mode.
Reference Trees are used only initial set-up and for illustration of the concepts.
Any search in the Reference Tree creates a path from root to the searched node.
We call that a Preferred Path and the Preferred Child attribute specific to the Reference Tree indicates if the preferred path of a node goes to the left or right child if any. A Preferred Path is determined by the longest path formed by preferred children.
Any new search in the Reference Tree will carve new paths and modify the existing paths. Correspondingly, the preferred children change too.
Any switch from right to left or vice versa is called an Interleave. Interleaves changes are the basis for analysis of expected performance.
Operations
As we stated Tango Trees are static so they support only searches. That also means that there is a construction phase where the elements are inserted in the Tango Tree. That start-up cost and any search performance during the construction period is not considered part of the operational part of Tango trees therefor the performance is not competitive.
The outstanding idea behind Tango Trees is to collect the nodes belonging to a Preferred Path as a balanced tree of height O(log log n) called auxiliary tree and then assemble them in a tree of trees where higher trees contain the mostly accessed preferred paths elements.
Search
To search for a node x in a Tango tree, we search for the element in the collection of Auxiliary Trees that make up the Tango Tree like in any ordinary binary search tree. Simultaneously we adjust the corresponding affected Auxiliary Trees in the Tango Tree. This will preserve the ideal structure that will give us this unprecedented search performance.
We could achieve this ideal structure by updating the Reference Tree P after every search and recreating the Tango tree however this would be very expensive and nonperforming.
The reasons why such a structure is competitive is explained in the Analysis
There is a direct way to update the structure and that is shown in the [Algorithm]
Construction
First create the reference tree and insert the desired data in it. Update the attributes of depth for each node
After this phase the data and the value of the depth for the nodes will remain unchanged. Let's call that field d for further reference and understand that it always refers to the Reference tree not to the Tango tree as that can cause confusions. While in principle the reference tree can be any balanced tree that is augmented with the depth of each node in the tree the TODO [Demaine et al. 2004] uses [red-black tree].
Secondly we will perform some warm-up searches with the goal of creating a decent distribution of Preferred Paths in the Reference Tree. Remember there is no Tango tree yet and all this is done on line.
This means that performance is not critical at this point.
After this begins the phase of collecting the preferred paths.
Out of each Preferred Path we create a new Auxiliary Tree which is just an ordinary RedBlack Tree where the nodes inherit the value of field d. That value will stay unchanged forever because it stays with the node even if the node is moved in the trees. There is no Tango Tree at this point.
We add auxiliary trees in such a way that the largest one is the top of a tree and the rest 'hung' below it. This way we effectively create a forest where each tree is an Auxiliary tree.
See Fig. 1 where the roots of the composing auxiliary tree are depicted by magenta nodes. It's after this step that the Tango tree becomes operational. See [Construction Algorithms And Pseudo-code] for main algorithms and pseudo-code.
Operation
The operation phase is the main phase where we perform searches in the Tango tree. See [Operation Algorithms And Pseudo-code] for main algorithms And pseudo-code.
Reference Tree augmentation
Besides the regular RB Tree fields we introduce two more fields:
isPreferredChild representing the direction the last search traversing the node took. It could be either Boolean or a pointer to another node. In the figures it is represented by a red line between a node and its preferred child.
d representing the depth of the node in the Reference Tree. (See value of d in Fig 3.)
Tango Tree Augmentation
For each nodes in Tango or Auxiliary Tree we also introduce several new fields:
isRoot that will be false for all nodes except for the root. This is depicted in magenta for nodes where isRoot is true.
maxD that is the Maximum value of d for all the children of the node. This is depicted as MD in the figures. For some nodes this value is undefined and the field is not depicted in the figure
minD that is the Minimum value of d for all the children of the node. This is depicted as mD in the figures. For some nodes this value is undefined and the field is not depicted in the figure
isRoot, maxD and minD will change in time when nodes are moved around in the structure.
Algorithms
The main task in a Tango Tree is to maintain an 'ideal' structure mirroring changes that occur in the reference tree. As recreating the Tango tree form the reference tree would not be performing the algorithms will have only use and modify the Tango tree. That means that after the construction phase the reference tree could and should be destroyed. After this we would refer to it as virtual meaning 'as if it existed'. As described in [Demaine et al. 2004], the main goal is to maintain the ideal Tango structure that would mimic preferred paths changes on the virtual reference tree. So the purpose of the Tango algorithm is the constructing of a new state Ti of the Tango Tree based on the previous state Ti-1 or the Tango Tree and the new search of xi.
Tango Search
During the search for xi, one or many auxiliary trees could to be traversed. During this Tango walk phase of the Tango search every time when we are crossing from an auxiliary tree in a new auxiliary tree we perform exactly one cut operation on the tree just traversed.
The result of the Cut is then Joined with the newly entered auxiliary tree set of data and repeats for each new auxiliary tree encountered creating a snowball effect. Note that in this analogy, the snowball casts off some nodes and collects other nodes in its trajectory towards the final auxiliary tree that contains the searched element. Before performing a cut, the new auxiliary tree is queried to obtain a cut depth which is used in processing the previous auxiliary tree. Starting from a Reference tree in Fig. 7 obtained after performing searches on 17, 7, 1, 18, 23, 31, 27, 13, 9, 20, we see the corresponding Tango Tree as in Fig. 8. On this tree during a walk towards element xi =23 we would have traversed the top auxiliary tree 20 and entered auxiliary tree 22. Note that preferred paths are marked in red and auxiliary tree roots in magenta. Remember that all auxiliary trees are actually RB trees so the red shadows on some nodes represent the red nodes in the RB trees.
In case we would have searched for element 7 during the Tango Walk we would have crossed the top auxiliary tree rooted at 20, the auxiliary tree rooted at 10, auxiliary tree rooted at 2 and auxiliary tree rooted at 6. That means that we would have to perform the Tango Cut-And-Join several times.
For each entrance to a new auxiliary tree, the tree that was just crossed is processed by a Tango cut algorithm. In order to perform the Tango cut we need to determine the cut range. A specific d value is the input data in the algorithm to determine the cut range.
Determining d
This specific d value is determined every time when we cross the boundary to a new auxiliary tree and it is determined from the soon-to-be-traversed auxiliary tree. We know when we cross the boundary by looking at the isRoot attribute of each node en route to xi. We ignore the isRoot attribute of the root of Tango tree. To simplify the code we don’t even set it on Tango root and that is why top nodes are not colored in magenta in any of the figures.
The value of d is determined by subtracting 1 from the minimum between the root of the new auxiliary tree minD value and its current d value.
So in search for 23 we reach auxiliary tree rooted at 22 we calculate minimum between its minD value and its d value and we subtract 1 and we get this special value of d =2. Please observe by looking in the reference tree in fig. 7 that, that is exactly the depth value where the new search will change the value of a preferred child and create a new interleave. See node 20 on the reference tree in fig 7.
There are some particular cases when either minD or d are out of range or unknown. In the implementation that is represented by a -1, a value which denotes + or -infinity if the value denotes the right side of the range or left side of the range. In all the figures the nodes where the value of minD or maxD is -1 do not show the corresponding value(s) for brevity reasons.
The value of -1 is screened out during the determination of a minimum so it does not mask legitimate d values. This is not the case for maxD.
Determining the cutting range
Considering the auxiliary tree A in Fig 9, we need to determine nodes l and r. According to [Demaine et al. 2004] The node l is the node with the minimum key value (1) and the depth greater than d (2) and can be found in O(log k) time where k is the number of nodes in A.
We observe by looking at the virtual reference tree that all nodes to be cut are actually under the interleave created by the search at the node corresponding to the auxiliary tree the tango search is about to enter. In Fig. 9 we show the reference tree at state ti after a search for 9 and in Fig. 10 we show the reference tree at state ti+1 after a search for 15. The interleave appears at node 12 and we want to ‘cut’ all the nodes in the original path that are below 12. We observe their keys are all in a range of values and their d values are higher than the cutting d which is the depth of the interleave node (d=2).
Of course we need to find the nodes to be cut not in the reference tree but in the corresponding auxiliary tree. We use the value of depth obtained during the Tango search as input to calculate the cut range.
We need to determine the minimum key of a node l that has the depth greater than d. This node can be found in O(log k) time and is the left boundary of our interval. In the same way, a node r with the maximum key value and the depth greater than d can also be found in O(log k), where k is the number of nodes in A.
We already observed that the keys of the nodes to cut are in a key range so instead to take all the nodes in the corresponding auxiliary tree and check if their d is greater than the input d we can just find the left side of the range and the right side of the range.
Finding l
We first find l which is the leftmost element to be cut (using getL). We determine it by walking to the leftmost child whose sub-tree has either its d value or maximum depth greater than d.
No nodes meeting this criteria result in l being -infinity (or NIL in the implementation). This means that the cut interval extends all the way to the left so during the cut or the join less split and concatenate operations have to be performed.
Finding r
For finding r we walk right to the rightmost node whose d value is greater than d. No nodes meeting this criteria result in r being +infinity (or NIL in the implementation). This means that the cut interval extends all the way to the left so during the cut or the join less split and concatenate operations have to be performed.
Algorithms 7 and 8 describe the implementation of getL and getR.
Finding l’ and r’
Following the determination of l and r, the predecessor l’ of the node l and the successor r’ of r are found. These new nodes are the first nodes that ‘survive’ the cut. A NIL in l will also result in a NIL l’ and a NIL in r will result in a NIL in r’.
Both nodes being NIL take a new meaning signifying that all the nodes will survive the cut so practically we can skip the Tango cut and takes the set of nodes directly to Tango join.
During the Tango Search when we finally reached the searched node the tango cut algorithm is run once more however its input provided by Tango search is changed. The input value of d is now the d of the searched node and the tree to be cut is the auxiliary tree that contains the searched node.
During the Tango Search after encountering any new auxiliary tree (NAT) the Tango cut is normally applied on the tree above (except for final cut as described above) and results in a new structure of auxiliary trees. Let's call this result of the cut A.
The Join operation will join a set of nodes with the nodes in the NAT. There is an exception that applies when we reached the searched node, in which case we join A with the auxiliary tree rooted at the preceding marked node of the searched node.
The Tango cut algorithm consists of a sequence of tree split, mark and concatenate algorithms. The Tango join algorithm consists of a different sequence of tree split, un-mark and concatenate algorithms. Marking a node is just setting the isRoot attribute to true and un-marking setting the same attribute to false.
RB Split and RB Concatenate
Red-black trees support search, split and concatenate in O(log n) time. The split and concatenate operations are the following:
Split: A red-black tree is split by rearranging the tree so that x is at the root, the left sub-tree of x is a red-black tree on the nodes with keys less than x, and the right sub-tree of x is a red-black tree on the nodes with keys greater than x.
Concatenate: A red-black tree is concatenated by rearranging x's sub-tree to form a red-black tree on x and the nodes in its sub-tree. As condition for this operation all the nodes in one of the trees have to have lower values than the nodes in the other tree.
Note that the behavior for split and concatenate in [Demaine et al. 2004] differs slightly from the standard functionality of these operations as the signature of the operations differ in terms of number and type of input and output parameters.
The two operations describe above apply only to an auxiliary tree and do not cross into other auxiliary trees. We use the isRoot information for each node to avoid wandering in other trees.
Tango Cut algorithm
The main purpose of the cut is to separate a tree in two sets of nodes. Nodes need to be pushed to the top because the search path in the virtual reference tree traversed them and nodes that become less important (cut nodes) and are pushed downwards to the next auxiliary tree.
We already determined the values of l’ and r’ and we want to cut the input auxiliary tree (A in Fig. 11) in the range l’ to r’. We need to split A in three trees and then cut the middle tree and re- assemble the remaining parts. We start with a split at l’ that creates tree B and tree C. Tree B will be free of nodes to cut but tree C will contain nodes to cut and nodes to keep. We do a second split at r’ and obtain trees D and E. D contains all nodes to be cut and E contains all the nodes to keep. We then mark the root of D as isRoot therefore logically pushing it to a lower level. We then concatenate at r’. Note: this is not really a standard RB concatenate but rather a merge between a node and a tree. As a result we obtained C. The last operation is to concatenate C tree, B tree and node l’ obtaining the nodes we want to keep in the new tree A. Note: this is not really a standard RB concatenate but rather a merge between a node and a tree and then a standard two tree concatenation.
The resulting new node A is actually composed of two auxiliary trees: the top one that contains nodes we want to favor and the lower ‘hung’ D which contains nodes that get pushed downwards via this operation. The nodes being pushed downwards are exactly the nodes that were on the old preferred path corresponding to the auxiliary tree being processed but not in the new preferred path. The nodes being pushed upwards (now in A) are exactly the nodes that were became part of the new preferred path due to the performed search. Fig. 11 shows this flow of operations.
The following special cases may occur:
l’ and r’ are NIL so cut is performed.
r’ is NIL we just do a split at l’ and C becomes the result while we hang B under C via a mark operation.
l’ is NIL we just do a split at r’ and E becomes the result and we hang the left resulting tree under E.
The result will be then joined with the content of the next auxiliary tree via the Tango Join algorithm.
Tango Join algorithm
During the Tango Search after encountering any new auxiliary tree (NAT) the Tango Cut being applied on the tree above the NAT results in a new structure of auxiliary trees. We can think of that as a Tango sub tree. It will normally contain at least two connected auxiliary trees. The top tree A containing the nodes we want to keep close to the surface of the Tango Tree (so we can achieve the ‘bring to top’ approach) and ‘hang’ to it is auxiliary tree D which was pushed downwards. In case of search for 23 all of the nodes from previous auxiliary tree should be kept close to surface and the set of nodes destined to be moved in D is empty so we have no D. Regardless of the situation the result of the Tango cut will contain at least one node (the Tango root) in Tree A. Let's call this result of the cut A.
The Join will join A set of nodes with the nodes in the NAT. That is done via two splits, an un-mark and two concatenates.
Fig. 12 shows the high level sequence where A is coming from the previous cut tree and B is the NAT. We observe that NAT is actually hung under the tree that was just cut therefore the values of its keys are all in a range of two adjacent keys (a key and its successor) in the tree that was just cut. That is normal for any BST. If the NAT is hanging as a left tree the parent node marks the right side of the range while its predecessor (in the tree that was just cut universe) marks the left side of the range. So in order to join the two trees we just have to wedge B under to the left of its parent in A. Similarly for the case where B happens to hang to the right of its parent where we wedge the content of B to the right of its parent. In order to find the wedge insertion point we can just search in the A for the root of NAT. Of course that value is not in NAT but it will find a close value and by taking its predecessor or successor (depending on the search algorithm and if the close value was before or after the value) we find the two nodes between where B should be wedged. Let's call these values lPrime and rPrime. Next is to split A first at lPrime and then at rPrime therefore creating three trees, a First part (FP), middle part (MP) and last part (LP). While these operations where done in the A universe they also need to carry all the other auxiliary trees as in the Tango universe. In the Tango (forest) universe we discover that MD is actually is B however is severed logically from rPrime because its root is marked as isRoot and it appears like a hung auxiliary tree. Since we want that wedged, we "un-mark" it) by resetting its isRoot attribute and making it logically part of rPrime. Now we have the final structure in place but we still need to concatenate it first at rPrime and then at lPrime to absorb all the nodes under the same Joined resulting tree.
The difficulty in doing this is the fact that the standard concatenates do not take nodes but just trees. A two tree and a node operation could be constructed and then repeated to obtain a Tango concatenate; however, it is hard to preserve the RB integrity and is dependant on the order of operations so the resulting structure is different even if it contains the same node. That is an issue because we can not control the exact reproduction of the ideal structure as if generated from the reference tree. It can be done in such a way to contain all nodes and preserve the correct RB tree structure however the geometry is dictated by the RB concatenates and is not necessarily the ideal geometry mirroring perfectly the reference tree.
So for example let's say search for 23. We obtain A as the result on the first Tango cut on the top auxiliary tree. See Fig. 13 where 22 is the root of NAT.
We use the value of NAT (22) to search in the tree above and we obtain 20 and 24 as the lPrime and rPrime nodes.
We split at lPrime (20) and we obtain FP as in Fig. 14 and LP as in Fig. 15.
We then split for the second time at rPrime (24) to get the last tree LT as in Fig. 15.
Next we unmark B which is rooted at 22 and we obtain the result in Fig 16. As you can see 22 now is part of the top of the structure. That makes sense if you look at Fig. 10 representing the ‘virtual’ reference tree. To reach 23 which is our target we would have had to go through 22.
We then concatenate with rPrime and obtain the result in presented in Fig. 17:
Second concatenation takes place and it this particular example will not result in rearranging of the nodes so Fig. 17 is the final result of the Join operation.
Construction Algorithms And Pseudo-code
Construct the reference tree and perform warm-up searches.
Function: constructReferenceTree
Input: None
Output: ReferenceTree p
ReferenceTree p = new ReferenceTree
insertDataInReferenceTree
p.setAllDepths
p.warmUpSearches
ArrayList paths = p.collectAndSortPreferredPaths
assert paths.size > 0
PreferredPath top = p.collectTopNodePath(p.root)
TangoTree tangoTree = new TangoTree(top)
tangoTree.updateMinMaxD
while (takeNext PreferredPath path in paths) do
if (path.top = p.root) then
continue; // skip the top path as it was already added
else
RBTree auxTree = new RBTree(path)
auxTree.updateMinMaxD
auxTree.root.isRoot = true
tangoTree.hang(auxTree)
return p
Construct an Auxiliary tree out of a Preferred Path. Used in the construction phase.
Function: constructAuxiliaryTree
Input: Preferred Path path
Output: AuxiliaryTree this
RBTree(PreferredPath path)
this
RefTreeNode refNode = path.top
while (Next PreferredPath path in paths exists) do
RBNode n = new RBNode(refNode.value, RedBlackColor.RED, null, null)
n.d = refNode.d
this.insert(n)
refNode = refNode.getPreferredChild
Construct a Tango tree from the Reference tree.
Function: constructTangoTree
Input: ReferenceTree p
Output: TangoTree tangoTree
ArrayList paths = p.collectAndSortPreferredPaths
assert paths.size > 0
PreferredPath top = p.collectTopNodePath(p.root)
TangoTree tangoTree = new TangoTree(top)
tangoTree.updateMinMaxD
while (Next PreferredPath path in paths exists) do
if (path.top = p.root) then
continue; // skip the top path as it was already added
else
RBTree auxTree = new RBTree(path)
auxTree.updateMinMaxD
auxTree.root.isRoot = true
return tangoTree
Set the depths of all nodded in the tree. Used only once for setting the depths of all nodes in the reference tree.
Function: setAllDepths
Input: None
setAllDepthsHelper(root)
Algorithm 14. Set the depths of all nodded in the tree.
Function: setAllDepthsHelper
Input: RefTreeNode n
if (n NILL) then
return
n.setD(getDepth(n))
if (n.right != null)
setAllDepthsHelper(((RefTreeNode) n.right))
if (n.left != null) then
setAllDepthsHelper((RefTreeNode) (n.left))
Operation Algorithms And Pseudo-code
There is just one operation: search that calls a number of algorithms to rearrange the data structure.
Tango search pseudocode. Used by the main operation on a Tango tree.
Function: tangoSearch
Input: int vKey
Node currentRoot = root
Node currentNode = root
Boolean found = false
while (true) do
if (currentNode NILL) then
found = false
break
if (currentNode.isRoot && currentNode != root) then
cutAndJoin(minIgnoreMinusOne(currentNode.minD, currentNode.d) - 1, currentRoot, currentNode)
currentRoot = currentNode
if (currentNode.value vKey) then
found = true
if (currentNode != currentRoot) then
cutAndJoin(currentNode.d, currentRoot, currentRoot)
break
if (currentNode.value < vKey) then
currentNode = (RBNode) currentNode.right
else
currentNode = (RBNode) currentNode.left
if (found) then
return currentNode
else
return NILL
Tango Cut and Join used by Tango Search
Function: cutAntJoin
Input: int d, Node currentRoot, Node newlyFoundRoot
RBNode n = currentRoot
RBNode l = NILL// l is the last node that gets cut
RBNode lPrime = NILL// l' is the first node that escapes from cutting
RBNode r = NILL
RBNode rPrime = NILL
if (currentRoot.maxD <= d) // no nodes to be cut besides maybe the root
if (currentRoot.d > d)
l = currentRoot
r = currentRoot
lPrime = getPredecessor(l, currentRoot)
rPrime = getSuccessor(r, currentRoot)
else // there are nodes to be cut underneath
l = getL(d, n, currentRoot)
// determine lPrime as predecessor of l or NILL if it is the last
if (l != NILL)
lPrime = getPredecessor(l, currentRoot)
else
lPrime = NILL// - infinity maybe redundant
// end calculating l and l prime
// find r the right side node of the cutting range based on value
n = currentRoot
r = getR(d, n, currentRoot)
if (r != NILL) // the root is not to be cut
rPrime = getSuccessor(r, currentRoot)
checkLandR(d, l, r, currentRoot)
RBTree aTree = NILL
if (lPrime NILL && rPrime NILL) // nothing to cut therefore so aTree is the whole
aTree = new RBTree
aTree.root = currentRoot
else
RBTreesPair aAndDtreePair = new RBTreesPair
aTree = tangoCut(lPrime, rPrime, currentRoot)
RBTree afterCutAndJoin = tangoJoin(aTree, newlyFoundRootOrCurrentIfWeFound)
Tango Cut used by Tango cut And Join to separate nodes that need to be pushed to top from the rest of nodes.
Function: tangoCut
Input: RBNode lPrime, RBNode rPrime, RBNode aRoot
Output: RBTree
saveShadowAuxTrees(aRoot)
if (lPrime null || rPrime null) {// just one splitAnd COncatenate
return simplifiedTangoCut(lPrime, rPrime, aRoot)
}
RBTree a = new RBTree
a.root = aRoot
RBTreesPair firstPartAndLastPart = new RBTreesPair
split(lPrime, a, firstPartAndLastPart)
RBTree b = firstPartAndLastPart.firstPart
RBTree c = firstPartAndLastPart.lastPart
firstPartAndLastPart.firstPart.verifyProperties
firstPartAndLastPart.lastPart.verifyProperties
firstPartAndLastPart = new RBTreesPair
split(rPrime, c, firstPartAndLastPart)// problem
firstPartAndLastPart.firstPart.verifyProperties
firstPartAndLastPart.lastPart.verifyProperties
RBTree d = firstPartAndLastPart.firstPart
RBTree e = firstPartAndLastPart.lastPart
// disconnect d
rPrime.left = NILL
d.root.parent = NILL
Tango Join used by Tango Cut and Join to join the result of Tango cut to auxiliary trees.
Function: tangoJoin
Input: RBTree a, RBNode newlyFoundRoot
Output: RBTree finalJoinResult
RBTree bPrevOp = new RBTree
RBTree d = new RBTree
order(bPrevOp,d, a, newlyFoundRoot)
RBNodePair lAndR = bPrevOp.searchBoundedLPrimeAndRPrime(d.root.value)
if (lPrime null || rPrime null) // just one split and one concatenate
return simplifiedTangoJoin(lPrime, rPrime, bPrevOp, d.root)
RBNode lPrime = lAndR.lPrime
RBNode rPrime = lAndR.rPrime
RBTreesPair firstPartAndLastPart = new RBTreesPair
split(lPrime, bPrevOp, firstPartAndLastPart)
RBTree b = firstPartAndLastPart.firstPart
RBTree c = firstPartAndLastPart.lastPart
firstPartAndLastPart.firstPart.verifyProperties
firstPartAndLastPart.lastPart.verifyProperties
firstPartAndLastPart = new RBTreesPair
split(rPrime, c, firstPartAndLastPart)//
firstPartAndLastPart.firstPart.verifyProperties
firstPartAndLastPart.lastPart.verifyProperties
RBTree e = firstPartAndLastPart.lastPart
// reconnect d which is normally newlyFoundRoot
d.root.isRoot = false// un-mark, a difference from tangoCut
// concatenate part
rPrime.parent = NILL// avoid side effects
RBTree res1 = concatenate(rPrime, d, e)
lPrime.parent = NILL// avoid side effects
RBTree res2 = concatenate(lPrime, b, res1)
return res2
Check if a node n is in an auxiliary tree defined by currentRoot. Used to verify wandering.
Function: isInThisTree
Input: RBNode n, RBNode currentRoot
Output: Boolean v
if (n.isRoot and n != currentRoot) then
return false
else
return true
Find node l as left of range used by Tango Cut, different from the [Demaine et al. 2004] paper.
Function: getL
Input: int d, Node n, Node currentRoot
Output: Node l
Node l = n
if (left[n] != NIL) and (not(isRoot(n) or n currentRoot) and ((left(n).maxD > d) or (left(n).d > d)) then
l=getL(d, left(n), currentRoot)
else
if (n.d > d)
l = n
else
l=getL(d, right(n), currentRoot)
return l
Find node r as the right limit of the range used by Tango Cut.
Function: getR
Input: int d, Node n, Node currentRoot
Output: Node r
Node r = n
if (right[n] != NIL) and (not(isRoot(n) or n currentRoot) and ((right(n).maxD > d) or (right(n).d > d)) then
r=getR(d, left(n), currentRoot)
else
if (n.d > d)
r = n
else
r=getR(d, right(n), currentRoot)
return r
Return Sibiling. Within enclosing auxiliary tree boundary
Function: siblingBound
Input: RBNode n, RBNode boundingRoot
Output: Node p
if (n left[parent[n]] && isInThisTreeAcceptsNull(left[parent[n]]), boundingRoot)) then
if (isInThisTreeAcceptsNull(right[parent[n]], boundingRoot) then
return right[parent[n]]
else
return NILL
else
if (isInThisTreeAcceptsNull(left[parent[n]], boundingRoot)) then
return left[parent[n]]
else
return NILL
Return Uncle. Within enclosing auxiliary tree boundary
Function: uncleBound
Input: RBNode n, RBNode boundingRoot
Output: Node p
if (isInThisTreeAcceptsNull(parent[n], boundingRoot)) then
return siblingBound(boundingRoot)
else
return NILL
Update Min Max D values in red black tree augmented node. Used to update Tango Tree node attributes.
Function: updateMinMaxD
Input: RBNode n
int minCandidate
if (n.left != NILL) then
updateMinMaxD(n.left)
if (n.right != NILL) {
updateMinMaxD(n.right)
if (n.left != NILL) then
int maxFromLeft = max(n.left.d, n.left.maxD)
n.maxD = maxFromLeft > n.maxD ? maxFromLeft : n.maxD
if (n.left.minD != -1) {
minCandidate = min(n.left.d, n.left.minD)
else
minCandidate = n.left.d
if (n.minD != -1) then
n.minD = min(n.minD, minCandidate)
else
n.minD = minCandidate
if (n.right != NILL) then
int maxFromRight = max(n.right.d, n.right.maxD)
n.maxD = maxFromRight > n.maxD ? maxFromRight : n.maxD
if (n.right.minD != -1) then
minCandidate = min(n.right.d, n.right.minD)
else
minCandidate = n.right.d
if (n.minD != -1) then
n.minD = min(n.minD, minCandidate)
else
n.minD = minCandidate
Search Bounded lPrime and rPrime used by Tango Join.
Function: searchBoundedLPrimeAndRPrime
Input: RBTree rbTree, int value
Output: NodePair p
RBNode n = root
RBNode prevPrevN = NILL
RBNode prevN = NILL
RBNodePair lAndR
while (n != NILL && isInThisTree(n, rbTree.root)) do
int compResult = value.compareTo(n.value)
if (key(n) value) then
lAndR = new RBNodePair(n, n)
return lAndR
else
if (key(n) < value) then
prevPrevN = prevN
prevN = n
if (isInThisTree(n.left, rbTree.root) then
n = n.left
else
n = NILL
else
prevPrevN = prevN
prevN = n
if (isInThisTree(n.right, rbTree.root) then
n = n.right
else
n = NILL
lAndR = new RBNodePair(prevPrevN, prevN)
return lAndR
The minimum in a binary search tree is always located if the left side path is traversed down to the leaf in O(log n) time:
Minimum Value Tree pseudocode. Used by successor.
Function: min_val_tree
Input: Node x
Output: Node x
while left(x) != NIL do
x = left(x)
return x
Maximum Value Tree pseudocode used by predecessor.
Function: max_val_tree
Input: Node x
Output: Node x
while right(x) != NIL do
x = right(x)
return x
The next two algorithms describe how to compute the predecessor and successor of a node. The predecessor of a node x is a node with the greatest value smaller the key[x].
Predecessor computing pseudocode used to find lPrime.
Function: predecessor
Input: RBNode x
Output: RBNode y
RBNode y = null
if (n.left != null && isInThisTree(((RBNode) (n.left)), root))
return getMaximum((RBNode) (n.left), root)
y = (RBNode) (n.parent)
if (y currentRoot) // don't let it escape above its own root
return NILL// --------------------------------------------------------------------->
while (y != NILL && (y != currentRoot) && n ((RBNode) (y.left))) do
n = y
if (isInThisTree(((RBNode) (y.parent)), root))
y = (RBNode) (y.parent)
else
y = null
return (RBNode) y
Successor computing algorithm used to find rPrime.
Function: successor
Input: Node x
Output: Node y
RBNode y = NILL
if (n.right != NILL && isInThisTree(((RBNode) (n.right)), currentRoot))
return getMinimum((RBNode) (n.right), currentRoot)
y = (RBNode) (n.parent)
if (y currentRoot) // don't let it escape above its own root
return NILL// --------------------------------------------------------------------->
while (y != NILL && isInThisTree(y, currentRoot) && n ((RBNode) (y.right))) do
n = y
y = (RBNode) (y.parent)
return (RBNode) y
Traverse Tree pseudocode used by Tango Search.
Function: traverse_tree
Input: Node x
Output: None
if x != NIL and InTheAuxiliaryTree(x) then
traverse_tree (left(x))
traverse_tree (right(x))
Search Tree algorithm used to find lPrime and rPrime for Tango Join.
Function: search_tree
Input: Node x, value
Output: Node x
if x = NIL or k = key[x] then
return x
if k < key[x] then
return search_tree(left[x]; value)
else
return search_tree(right[x]; value)
Find minimum by ignoring specific values used for the calculation of d.
Function: minIgnoreMinusOne
Input: int minD, int d
Output: int d
if (minD -1) then
return d
if (d
-1) then
return minD
return min(minD, d)
RedBlack split and Red Black concatenate algorithms are described in the RON WEIN, 2005, Efficient Implementation of Red-Black Trees with Split and Catenate Operations, http://www.cs.tau.ac.il/~wein/publications/pdfs/rb_tree.pdf
Analysis
Here are some elements necessary to understand why the Tango Tree achieve such an amazing performance and become competitive.
Wilber's 1st Lower Bound [Wil89]
Fix an arbitrary static lower bound tree P with no relation to the actual BST T, but over the same keys. In the application that we consider, P is a perfect binary tree. For each node y in P, we label each access X1 L if key X1 is in y's left subtree in P,
R if key X1 is in y's right subtree in P, or leave it blank if otherwise. For each y, we count the number of interleaves (the number of alterations)
between accesses to the left and right subtrees: interleave(y)= ? of alternations L ? R.
Wilber's 1st Lower Bound [Wil89] states that the total number of interleaves is a lower bound for
all BST data structures serving the access sequence x. The lower bound tree P must remain static.
Proof.
We define the transition point of y in P to be the highest node z in the BST T such that the root-to-z path in T includes a node from the left and right subtrees if y in P. Observe that the transition point is well defined, and does not change until we touch z. In addition, the transition point is unique for every node y.
Lemma 1
The running time of an access xi is , where k is the number of nodes whose preferred child changes during access xi.
Lemma 2
The number of nodes whose preferred child changes from left to right or from right to left during an access xi is equal to the interleave bound of access xi.
Theorem 1
The running time of the Tango BST on an sequence X of m accesses over the universe is where is the cost of the offline optimal BST servicing X.
Corollary 1.1
When m = (n), the running time of the Tango BST is ;
External links


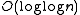 -competitive proposed by Erik D. Demaine, Dion Harmon, John Iacono, and Mihai Patrascu in 2004.
-competitive proposed by Erik D. Demaine, Dion Harmon, John Iacono, and Mihai Patrascu in 2004.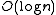 binary search tree cost of operations. They perform basic operations such as searches in
binary search tree cost of operations. They perform basic operations such as searches in 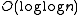 time. This optimization is achieved dynamically by adjusting the search tree structure after each search. They are similar in their dynamic behaviour to other types of structure like a Splay tree
time. This optimization is achieved dynamically by adjusting the search tree structure after each search. They are similar in their dynamic behaviour to other types of structure like a Splay tree performance for data retrieval.
performance for data retrieval.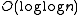 bits. Although that is not a significant increase, it results in a bigger memory footprint.
bits. Although that is not a significant increase, it results in a bigger memory footprint. competitive.
competitive.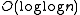 competitive is explained in the Analysis
competitive is explained in the Analysis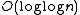 competitive.
competitive.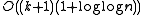 , where k is the number of nodes whose preferred child changes during access xi.
, where k is the number of nodes whose preferred child changes during access xi.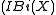 of access xi.
of access xi.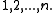 is
is 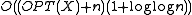 where
where  is the cost of the offline optimal BST servicing X.
is the cost of the offline optimal BST servicing X.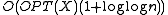
 competitive ratio
competitive ratio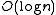 competitive ratio
competitive ratio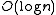 competitive ratio
competitive ratio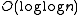 competitive ratio
competitive ratio