

Sliding window based part-of-speech tagging
Encyclopedia
Sliding window based part-of-speech tagging is used to part-of-speech tag
a text.
A high percentage of words in a natural language
are words which out of context can be assigned more than one part of speech. The percentage of these ambiguous words is typically around 30%, although it depends greatly on the language. Solving this problem is very important in many areas of natural language processing
. For example in machine translation
changing the part-of-speech of a word can dramatically change its translation.
Sliding window based part-of-speech taggers are programs which assign a single part-of-speech to a given lexical form of a word, by looking at a fixed sized "window" of words around the word to be disambiguated.
The two main advantages of this approach are:
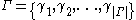
be the set of grammatical tags of the application, that is, the set of all possible tags which may be assigned to a word, and let
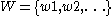
be the vocabulary of the application. Let
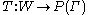
be a function for morphological analysis which assigns each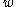 its set of possible tags,
its set of possible tags, 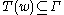 , that can be implemented by a full-form lexicon, or a morphological analyser. Let
, that can be implemented by a full-form lexicon, or a morphological analyser. Let
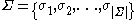
be the set of word classes, that in general will be a partition
of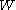 with the restriction that for each
with the restriction that for each 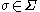 all of the words
all of the words 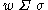 will receive the same set of tags, that is, all of the words in each word class (
will receive the same set of tags, that is, all of the words in each word class ( ) belong to the same ambiguity class.
) belong to the same ambiguity class.
Normally,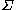 is constructed in a way that for high frequency words, each word class contains a single word, while for low frequency words, each word class corresponds to a single ambiguity class. This allows good performance for high frequency ambiguous words, and doesn't require too many parameters for the tagger.
is constructed in a way that for high frequency words, each word class contains a single word, while for low frequency words, each word class corresponds to a single ambiguity class. This allows good performance for high frequency ambiguous words, and doesn't require too many parameters for the tagger.
With these definitions it is possible to state problem in the following way: Given a text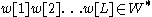 each word
each word 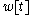 is assigned a word class
is assigned a word class 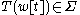 (either by using the lexicon or morphological analyser) in order to get an ambiguously tagged text
(either by using the lexicon or morphological analyser) in order to get an ambiguously tagged text 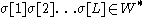 . The job of the tagger is to get a tagged text
. The job of the tagger is to get a tagged text 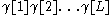 (with
(with 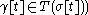 as correct as possible.
as correct as possible.
A statistical tagger looks for the most probable tag for an ambiguously tagged text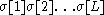 :
:
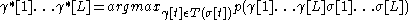
Using Bayes formula, this is converted into:
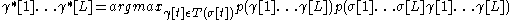
where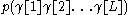 is the probability that a particular tag (syntactic probability) and
is the probability that a particular tag (syntactic probability) and 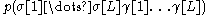 is the probability that this tag corresponds to the text
is the probability that this tag corresponds to the text 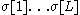 (lexical probability).
(lexical probability).
In a Markov model
, these probabilities are approximated as products. The syntactic probabilities are modelled by a first order Markov process:
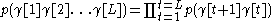
where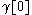 and
and 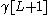 are delimiter symbols.
are delimiter symbols.
Lexical probabilities are independent of context:
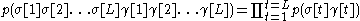
One form of tagging is to approximate the first probability formula:
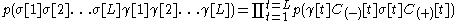
where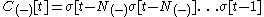 is the right context of the size
is the right context of the size 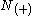 .
.
In this way the sliding window algorithm only has to take into account a context of size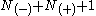 . For most applications
. For most applications 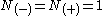 . For example to tag the ambiguous word "run" in the sentence "He runs from danger", only the tags of the words 'He' and 'from' are needed to be taken into account.
. For example to tag the ambiguous word "run" in the sentence "He runs from danger", only the tags of the words 'He' and 'from' are needed to be taken into account.
Part-of-speech tagging
In corpus linguistics, part-of-speech tagging , also called grammatical tagging or word-category disambiguation, is the process of marking up a word in a text as corresponding to a particular part of speech, based on both its definition, as well as its context—i.e...
a text.
A high percentage of words in a natural language
Natural language
In the philosophy of language, a natural language is any language which arises in an unpremeditated fashion as the result of the innate facility for language possessed by the human intellect. A natural language is typically used for communication, and may be spoken, signed, or written...
are words which out of context can be assigned more than one part of speech. The percentage of these ambiguous words is typically around 30%, although it depends greatly on the language. Solving this problem is very important in many areas of natural language processing
Natural language processing
Natural language processing is a field of computer science and linguistics concerned with the interactions between computers and human languages; it began as a branch of artificial intelligence....
. For example in machine translation
Machine translation
Machine translation, sometimes referred to by the abbreviation MT is a sub-field of computational linguistics that investigates the use of computer software to translate text or speech from one natural language to another.On a basic...
changing the part-of-speech of a word can dramatically change its translation.
Sliding window based part-of-speech taggers are programs which assign a single part-of-speech to a given lexical form of a word, by looking at a fixed sized "window" of words around the word to be disambiguated.
The two main advantages of this approach are:
- It is possible to automatically train the tagger, getting rid of the need of manually tagging a corpus.
- The tagger can be implemented as a finite state automaton (Mealy machineMealy machineIn the theory of computation, a Mealy machine is a finite-state machine whose output values are determined both by its current state and the current inputs. The outputs change asynchronously with respect to the clock, meaning that the outputs change at unpredictable times, making timing analysis...
)
Formal definition
Letbe the set of grammatical tags of the application, that is, the set of all possible tags which may be assigned to a word, and let
be the vocabulary of the application. Let
be a function for morphological analysis which assigns each
its set of possible tags, , that can be implemented by a full-form lexicon, or a morphological analyser. Letbe the set of word classes, that in general will be a partition
Partition of a set
In mathematics, a partition of a set X is a division of X into non-overlapping and non-empty "parts" or "blocks" or "cells" that cover all of X...
of
with the restriction that for each all of the words will receive the same set of tags, that is, all of the words in each word class () belong to the same ambiguity class.Normally,
is constructed in a way that for high frequency words, each word class contains a single word, while for low frequency words, each word class corresponds to a single ambiguity class. This allows good performance for high frequency ambiguous words, and doesn't require too many parameters for the tagger.With these definitions it is possible to state problem in the following way: Given a text
each word is assigned a word class (either by using the lexicon or morphological analyser) in order to get an ambiguously tagged text . The job of the tagger is to get a tagged text (with as correct as possible.A statistical tagger looks for the most probable tag for an ambiguously tagged text
:Using Bayes formula, this is converted into:
where
is the probability that a particular tag (syntactic probability) and is the probability that this tag corresponds to the text (lexical probability).In a Markov model
Markov model
In probability theory, a Markov model is a stochastic model that assumes the Markov property. Generally, this assumption enables reasoning and computation with the model that would otherwise be intractable.-Introduction:...
, these probabilities are approximated as products. The syntactic probabilities are modelled by a first order Markov process:
where
and are delimiter symbols.Lexical probabilities are independent of context:
One form of tagging is to approximate the first probability formula:
where
is the right context of the size .In this way the sliding window algorithm only has to take into account a context of size
. For most applications . For example to tag the ambiguous word "run" in the sentence "He runs from danger", only the tags of the words 'He' and 'from' are needed to be taken into account.Further reading
- Sanchez-Villamil, E., Forcada, M. L., and Carrasco, R. C. (2005). "Unsupervised training of a finite-state sliding-window part-of-speech tagger". Lecture Notes in Computer Science / Lecture Notes in Artificial Intelligence, vol. 3230, p. 454-463