

Ridit scoring
Encyclopedia
In econometrics
, ridit scoring is a statistical method used to analyze ordered qualitative measurements.
The tools of ridit analysis were developed and first applied by Bross, who coined the term "ridit" by analogy with other statistical transformations such as probit
and logit
.

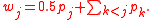
Each of the categories of the reference data set are then associated with a ridit score.
More formally, for each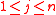 , the value wj is the ridit score of the choice xj.
, the value wj is the ridit score of the choice xj.
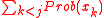
is very small, which is to say that very few respondents have chosen a category "lower" than xj.
) and econometric preference studies.
Econometrics
Econometrics has been defined as "the application of mathematics and statistical methods to economic data" and described as the branch of economics "that aims to give empirical content to economic relations." More precisely, it is "the quantitative analysis of actual economic phenomena based on...
, ridit scoring is a statistical method used to analyze ordered qualitative measurements.
The tools of ridit analysis were developed and first applied by Bross, who coined the term "ridit" by analogy with other statistical transformations such as probit
Probit
In probability theory and statistics, the probit function is the inverse cumulative distribution function , or quantile function associated with the standard normal distribution...
and logit
Logit
The logit function is the inverse of the sigmoidal "logistic" function used in mathematics, especially in statistics.Log-odds and logit are synonyms.-Definition:The logit of a number p between 0 and 1 is given by the formula:...
.
Choosing a reference data set
Since ridit scoring is used to compare two or more sets of ordered qualitative data, one set is designated as a reference against which other sets can be compared. In econometric studies, for example, the ridit scores measuring taste survey answers of a competing or historically important product are often used as the reference data set against which taste surveys of new products are compared. Absent a convenient reference data set, an accumulation of pooled data from several sets or even an artificial or hypothetical set can be used.Determining the probability function
After a reference data set has been chosen, the reference data set must be converted to a probability function. To do this, let x1, x2, xn denote the ordered categories of the preference scale. For each j, xj represents a choice or judgment. Then, let the probability function p be defined with respect to the reference data set asDetermining ridits
The ridit scores, or simply ridits, of the reference data set are then easily calculated asEach of the categories of the reference data set are then associated with a ridit score.
More formally, for each
, the value wj is the ridit score of the choice xj.Interpretation and examples
Intuitively, ridit scoring can be understood as a modified notion of percentile. For any j, if xj has a low (close to 0) ridit score, one can conclude thatis very small, which is to say that very few respondents have chosen a category "lower" than xj.
Applications
Ridit scoring has found use primarily in the health sciences (including nursing and epidemiologyEpidemiology
Epidemiology is the study of health-event, health-characteristic, or health-determinant patterns in a population. It is the cornerstone method of public health research, and helps inform policy decisions and evidence-based medicine by identifying risk factors for disease and targets for preventive...
) and econometric preference studies.