
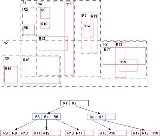
R-tree
Overview
Geographic coordinate system
A geographic coordinate system is a coordinate system that enables every location on the Earth to be specified by a set of numbers. The coordinates are often chosen such that one of the numbers represent vertical position, and two or three of the numbers represent horizontal position...
, rectangle
Rectangle
In Euclidean plane geometry, a rectangle is any quadrilateral with four right angles. The term "oblong" is occasionally used to refer to a non-square rectangle...
s or polygon
Polygon
In geometry a polygon is a flat shape consisting of straight lines that are joined to form a closed chain orcircuit.A polygon is traditionally a plane figure that is bounded by a closed path, composed of a finite sequence of straight line segments...
s. The R-tree was proposed by Antonin Guttman in 1984 and has found significant use in both research and real-world applications. A common real-world usage for an R-tree might be to store spatial objects such as restaurant locations or the polygons that typical maps are made of: streets, buildings, outlines of lakes, coastlines, etc.
Unanswered Questions