

Generalized vector space model
Encyclopedia
The Generalized vector space model is a generalization of the vector space model
used in information retrieval
. Wong et al. presented an analysis of the problems that the pairwise orthogonality assumption of the Vector space model
(VSM) creates. From here they extended the VSM to the generalized vector space model (GVSM).
For a document dk and a query q the similarity function now becomes:

where ti and tj are now vectors of a 2n dimensional space.
Term correlation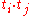 can be implemented in several ways. As an example Wong et al. use as input to their algorithm the term occurrence frequency matrix obtained from automatic indexing and the output is term correlation between any pair of index terms.
can be implemented in several ways. As an example Wong et al. use as input to their algorithm the term occurrence frequency matrix obtained from automatic indexing and the output is term correlation between any pair of index terms.
Recently Tsatsaronis focused on the first approach.
They measure semantic relatedness (SR) using a thesaurus (O) like WordNet
. It considers the path length, captured by compactness (SCM), and the path depth, captured by semantic path elaboration (SPE).
They estimate the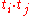 inner product by:
inner product by:
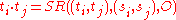
where si and sj are senses of terms ti and tj respectively, maximizing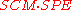 .
.
Vector space model
Vector space model is an algebraic model for representing text documents as vectors of identifiers, such as, for example, index terms. It is used in information filtering, information retrieval, indexing and relevancy rankings...
used in information retrieval
Information retrieval
Information retrieval is the area of study concerned with searching for documents, for information within documents, and for metadata about documents, as well as that of searching structured storage, relational databases, and the World Wide Web...
. Wong et al. presented an analysis of the problems that the pairwise orthogonality assumption of the Vector space model
Vector space model
Vector space model is an algebraic model for representing text documents as vectors of identifiers, such as, for example, index terms. It is used in information filtering, information retrieval, indexing and relevancy rankings...
(VSM) creates. From here they extended the VSM to the generalized vector space model (GVSM).
Definitions
GVSM introduces term to term correlations, which deprecate the pairwise orthogonality assumption. More specifically, they considered a new space, where each term vector ti was expressed as a linear combination of 2n vectors mr where r = 1...2n.For a document dk and a query q the similarity function now becomes:
where ti and tj are now vectors of a 2n dimensional space.
Term correlation
can be implemented in several ways. As an example Wong et al. use as input to their algorithm the term occurrence frequency matrix obtained from automatic indexing and the output is term correlation between any pair of index terms.Semantic information on GVSM
There are at least two basic directions for embedding term to term relatedness, other than exact keyword matching, into a retrieval model:- compute semantic correlations between terms
- compute frequency co-occurrence statistics from large corpora
Recently Tsatsaronis focused on the first approach.
They measure semantic relatedness (SR) using a thesaurus (O) like WordNet
WordNet
WordNet is a lexical database for the English language. It groups English words into sets of synonyms called synsets, provides short, general definitions, and records the various semantic relations between these synonym sets...
. It considers the path length, captured by compactness (SCM), and the path depth, captured by semantic path elaboration (SPE).
They estimate the
inner product by:where si and sj are senses of terms ti and tj respectively, maximizing
.