

Fuzzy retrieval
Encyclopedia
Fuzzy retrieval techniques are based on the Extended Boolean model
and the Fuzzy set
theory. There are two classical fuzzy retrieval models: Mixed Min and Max (MMM) and the Paice model. Both models do not provide a way of evaluating query weights, however this is considered by the P-norms
algorithm.
In MMM each index term has a fuzzy set associated with it. A document's weight with respect to an index term A is considered to be the degree of membership of the document in the fuzzy set associated with A. The degree of membership for union and intersection are defined as follows in Fuzzy set theory:
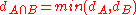
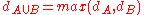
According to this, documents that should be retrieved for a query of the form A or B, should be in the fuzzy set associated with the union of the two sets A and B. Similarly, the documents that should be retrieved for a query of the form A and B, should be in the fuzzy set associated with the intersection of the two sets. Hence, it is possible to define the similarity of a document to the or query to be max(dA, dB) and the similarity of the document to the and query to be min(dA, dB). The MMM model tries to soften the Boolean operators by considering the query-document similarity to be a linear combination of the min and max document weights.
Given a document D with index-term weights dA1, dA2, ..., dAn for terms A1, A2, ..., An, and the queries:
Qor = (A1 or A2 or ... or An)
Qand = (A1 and A2 and ... and An)
the query-document similarity in the MMM model is computed as follows:
SlM(Qor, D) = Cor1 * max(dA1, dA2, ..., dAn) + Cor2 * min(dA1, dA2, ..., dAn)
SlM(Qand, D) = Cand1 * min(dA1, dA2, ..., dAn) + Cand2 * max(dA1, dA2 ..., dAn)
where Cor1, Cor2 are "softness" coefficients for the or operator, and Cand1, Cand2 are softness coefficients for the and operator. Since we would like to give the maximum of the document weights more importance while considering an or query and the minimum more importance while considering an and query, generally we have Cor1 > Cor2 and Cand1 > Cand2. For simplicity it is generally assumed that Cor1 = 1 - Cor2 and Cand1 = 1 - Cand2.
Lee and Fox experiments indicate that the best performance usually occurs with Cand1 in the range [0.5, 0.8] and with Cor1 > 0.2. In general, the computational cost of MMM is low, and retrieval effectiveness is much better than with the Standard Boolean model
.
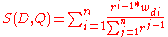
where r is a constant coefficient and wdi is arranged in ascending order for and queries and descending order for or queries. When n = 2 the Paice model shows the same behavior as the MMM model.
The experiments of Lee and Fox have shown that setting the r to 1.0 for and queries and 0.7 for or queries gives good retrieval effectiveness. The computational cost for this model is higher than that for the MMM model. This is because the MMM model only requires the determination of min or max of a set of term weights each time an and or or clause is considered, which can be done in O(n). The Paice model requires the term weights to be sorted in ascending or descending order, depending on whether an and clause or an or clause is being considered. This requires at least an 0(n log n) sorting algorithm. A good deal of floating point calculation is needed too.
These are very good improvements over the Standard model. MMM is very close to Paice and P-norm results which indicates that it can be a very good technique, and is the most efficient of the three.
If we look at documents on a pure Tf-idf approach, even eliminating stop words, there will be words more relevant to the topic of the document than others and they will have the same weight because they have the same term frequency. If we take into account the user intent on a query we can better weight the terms of a document. Each term can be identified as a concept in a certain lexical chain that translates the importance of that concept for that document.
They report improvements over Paice and P-norm on the average precision and recall for the Top-5 retrieved documents.
Zadrozny revisited the fuzzy information retrieval model. He further extends the fuzzy extended Boolean model by:
The proposed model makes it possible to grasp both imprecision and uncertainty concerning the textual information representation and retrieval.
Extended Boolean model
The Extended Boolean Model was described in a Communications of the ACM article appearing in 1983, by Gerard Salton, Edward A. Fox, and Harry Wu. The goal of the Extended Boolean Model is to overcome the drawbacks of the Boolean model that has been used in information retrieval...
and the Fuzzy set
Fuzzy set
Fuzzy sets are sets whose elements have degrees of membership. Fuzzy sets were introduced simultaneously by Lotfi A. Zadeh and Dieter Klaua in 1965 as an extension of the classical notion of set. In classical set theory, the membership of elements in a set is assessed in binary terms according to...
theory. There are two classical fuzzy retrieval models: Mixed Min and Max (MMM) and the Paice model. Both models do not provide a way of evaluating query weights, however this is considered by the P-norms
Extended Boolean model
The Extended Boolean Model was described in a Communications of the ACM article appearing in 1983, by Gerard Salton, Edward A. Fox, and Harry Wu. The goal of the Extended Boolean Model is to overcome the drawbacks of the Boolean model that has been used in information retrieval...
algorithm.
Mixed Min and Max model (MMM)
In fuzzy-set theory, an element has a varying degree of membership, say dA, to a given set A instead of the traditional membership choice (is an element/is not an element).In MMM each index term has a fuzzy set associated with it. A document's weight with respect to an index term A is considered to be the degree of membership of the document in the fuzzy set associated with A. The degree of membership for union and intersection are defined as follows in Fuzzy set theory:
According to this, documents that should be retrieved for a query of the form A or B, should be in the fuzzy set associated with the union of the two sets A and B. Similarly, the documents that should be retrieved for a query of the form A and B, should be in the fuzzy set associated with the intersection of the two sets. Hence, it is possible to define the similarity of a document to the or query to be max(dA, dB) and the similarity of the document to the and query to be min(dA, dB). The MMM model tries to soften the Boolean operators by considering the query-document similarity to be a linear combination of the min and max document weights.
Given a document D with index-term weights dA1, dA2, ..., dAn for terms A1, A2, ..., An, and the queries:
Qor = (A1 or A2 or ... or An)
Qand = (A1 and A2 and ... and An)
the query-document similarity in the MMM model is computed as follows:
SlM(Qor, D) = Cor1 * max(dA1, dA2, ..., dAn) + Cor2 * min(dA1, dA2, ..., dAn)
SlM(Qand, D) = Cand1 * min(dA1, dA2, ..., dAn) + Cand2 * max(dA1, dA2 ..., dAn)
where Cor1, Cor2 are "softness" coefficients for the or operator, and Cand1, Cand2 are softness coefficients for the and operator. Since we would like to give the maximum of the document weights more importance while considering an or query and the minimum more importance while considering an and query, generally we have Cor1 > Cor2 and Cand1 > Cand2. For simplicity it is generally assumed that Cor1 = 1 - Cor2 and Cand1 = 1 - Cand2.
Lee and Fox experiments indicate that the best performance usually occurs with Cand1 in the range [0.5, 0.8] and with Cor1 > 0.2. In general, the computational cost of MMM is low, and retrieval effectiveness is much better than with the Standard Boolean model
Standard Boolean model
The Boolean model of information retrieval is a classical information retrieval model and, at the same time, the first and most adopted one. It is used by virtually all commercial IR systems today.-Definitions:...
.
Paice model
The Paice model is a general extension to the MMM model. In comparison to the MMM model that considers only the minimum and maximum weights for the index terms, the Paice model incorporates all of the term weights when calculating the similarity:where r is a constant coefficient and wdi is arranged in ascending order for and queries and descending order for or queries. When n = 2 the Paice model shows the same behavior as the MMM model.
The experiments of Lee and Fox have shown that setting the r to 1.0 for and queries and 0.7 for or queries gives good retrieval effectiveness. The computational cost for this model is higher than that for the MMM model. This is because the MMM model only requires the determination of min or max of a set of term weights each time an and or or clause is considered, which can be done in O(n). The Paice model requires the term weights to be sorted in ascending or descending order, depending on whether an and clause or an or clause is being considered. This requires at least an 0(n log n) sorting algorithm. A good deal of floating point calculation is needed too.
Improvements over the Standard Boolean model
Lee and Fox compared the Standard Boolean model with MMM and Paice models with three test collections, CISI, CACM and INSPEC. These are the reported results for average mean precision improvement:| CISI | CACM | INSPEC | |
|---|---|---|---|
| MMM | 68% | 109% | 195% |
| Paice | 77% | 104% | 206% |
These are very good improvements over the Standard model. MMM is very close to Paice and P-norm results which indicates that it can be a very good technique, and is the most efficient of the three.
Recent work
Recently Kang et al.. have devised a fuzzy retrieval system indexed by concept identification.If we look at documents on a pure Tf-idf approach, even eliminating stop words, there will be words more relevant to the topic of the document than others and they will have the same weight because they have the same term frequency. If we take into account the user intent on a query we can better weight the terms of a document. Each term can be identified as a concept in a certain lexical chain that translates the importance of that concept for that document.
They report improvements over Paice and P-norm on the average precision and recall for the Top-5 retrieved documents.
Zadrozny revisited the fuzzy information retrieval model. He further extends the fuzzy extended Boolean model by:
- assuming linguistic terms as importance weights of keywords also in documents
- taking into account the uncertainty concerning the representation of documents and queries
- interpreting the linguistic terms in the representation of documents and queries as well as their matching in terms of the Zadeh’s fuzzy logic (calculus of linguistic statements)
- addressing some pragmatic aspects of the proposed model, notably the techniques of indexing documents and queries
The proposed model makes it possible to grasp both imprecision and uncertainty concerning the textual information representation and retrieval.