

Scott's Pi
Encyclopedia
Scott's pi is a statistic for measuring inter-rater reliability
for nominal data in communication studies
. Textual entities are annotated with categories by different annotators, and various measures are used to assess the extent of agreement between the annotators, one of which is Scott's pi. Since automatically annotating text is a popular problem in natural language processing
, and goal is to get the computer program that is being developed to agree with the humans in the annotations it creates, assessing the extent to which humans agree with each other is important for establishing a reasonable upper limit on computer performance.
Scott's pi is similar to Cohen's kappa
in that they improve on simple observed agreement by factoring in the extent of agreement that might be expected by chance. However, in each statistic, the expected agreement is calculated slightly differently. Scott's pi makes the assumption that annotators have the same distribution of responses, which makes Cohen's kappa
slightly more informative. Scott's pi is extended to more than two annotators in the form of Fleiss' kappa
.
The equation for Scott's pi, as in Cohen's kappa
, is:
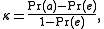
However, Pr(e) is calculated using joint proportions. A worked example is given below:
Confusion matrix for two annotators, three categories {Yes, No, Maybe} and 45 ratings per annotator:
To calculate the expected agreement, sum marginals across annotators and divide by the total number of items multiplied by the number of annotators, to obtain joint proportions. Square and total these:
To calculate observed agreement, divide the number of items on which annotators agreed by the total number of items. In this case;
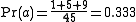
So,
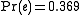
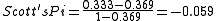
Inter-rater reliability
In statistics, inter-rater reliability, inter-rater agreement, or concordance is the degree of agreement among raters. It gives a score of how much homogeneity, or consensus, there is in the ratings given by judges. It is useful in refining the tools given to human judges, for example by...
for nominal data in communication studies
Communication studies
Communication Studies is an academic field that deals with processes of communication, commonly defined as the sharing of symbols over distances in space and time. Hence, communication studies encompasses a wide range of topics and contexts ranging from face-to-face conversation to speeches to mass...
. Textual entities are annotated with categories by different annotators, and various measures are used to assess the extent of agreement between the annotators, one of which is Scott's pi. Since automatically annotating text is a popular problem in natural language processing
Natural language processing
Natural language processing is a field of computer science and linguistics concerned with the interactions between computers and human languages; it began as a branch of artificial intelligence....
, and goal is to get the computer program that is being developed to agree with the humans in the annotations it creates, assessing the extent to which humans agree with each other is important for establishing a reasonable upper limit on computer performance.
Scott's pi is similar to Cohen's kappa
Cohen's kappa
Cohen's kappa coefficient is a statistical measure of inter-rater agreement or inter-annotator agreement for qualitative items. It is generally thought to be a more robust measure than simple percent agreement calculation since κ takes into account the agreement occurring by chance. Some...
in that they improve on simple observed agreement by factoring in the extent of agreement that might be expected by chance. However, in each statistic, the expected agreement is calculated slightly differently. Scott's pi makes the assumption that annotators have the same distribution of responses, which makes Cohen's kappa
Cohen's kappa
Cohen's kappa coefficient is a statistical measure of inter-rater agreement or inter-annotator agreement for qualitative items. It is generally thought to be a more robust measure than simple percent agreement calculation since κ takes into account the agreement occurring by chance. Some...
slightly more informative. Scott's pi is extended to more than two annotators in the form of Fleiss' kappa
Fleiss' kappa
Fleiss' kappa is a statistical measure for assessing the reliability of agreement between a fixed number of raters when assigning categorical ratings to a number of items or classifying items. This contrasts with other kappas such as Cohen's kappa, which only work when assessing the agreement...
.
The equation for Scott's pi, as in Cohen's kappa
Cohen's kappa
Cohen's kappa coefficient is a statistical measure of inter-rater agreement or inter-annotator agreement for qualitative items. It is generally thought to be a more robust measure than simple percent agreement calculation since κ takes into account the agreement occurring by chance. Some...
, is:
However, Pr(e) is calculated using joint proportions. A worked example is given below:
Confusion matrix for two annotators, three categories {Yes, No, Maybe} and 45 ratings per annotator:
| Yes | No | Maybe | Marginal Sum | |
| Yes | 1 | 2 | 3 | 6 |
| No | 4 | 5 | 6 | 15 |
| Maybe | 7 | 8 | 9 | 24 |
| Marginal Sum | 12 | 15 | 18 | 45 |
To calculate the expected agreement, sum marginals across annotators and divide by the total number of items multiplied by the number of annotators, to obtain joint proportions. Square and total these:
| Ann1 | Ann2 | Joint Proportion | JP Squared | |
| Yes | 12 | 6 | (12 + 6)/90 = 0.2 | 0.04 |
| No | 15 | 15 | (15 + 15)/90 = 0.332 | 0.111 |
| Maybe | 18 | 24 | (18 + 24)/90 = 0.467 | 0.218 |
| Total | 0.369 |
To calculate observed agreement, divide the number of items on which annotators agreed by the total number of items. In this case;
So,