

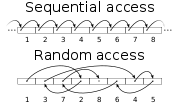
Random access
Encyclopedia
Computer science
Computer science or computing science is the study of the theoretical foundations of information and computation and of practical techniques for their implementation and application in computer systems...
, random access (sometimes called direct access) is the ability to access an element at an arbitrary position in a sequence in equal time, independent of sequence size. The position is arbitrary in the sense that it is unpredictable, thus the use of the term "random" in "random access". The opposite is sequential access
Sequential access
In computer science, sequential access means that a group of elements is accessed in a predetermined, ordered sequence. Sequential access is sometimes the only way of accessing the data, for example if it is on a tape...
, where a remote element takes longer time to access. A typical illustration of this distinction is to compare an ancient scroll
Scroll (parchment)
A scroll is a roll of papyrus, parchment, or paper which has been written, drawn or painted upon for the purpose of transmitting information or using as a decoration.-Structure:...
(sequential; all material prior to the data needed must be unrolled) and the book
Book
A book is a set or collection of written, printed, illustrated, or blank sheets, made of hot lava, paper, parchment, or other materials, usually fastened together to hinge at one side. A single sheet within a book is called a leaf or leaflet, and each side of a leaf is called a page...
(random: can be immediately flipped open to any random page
Page (paper)
A page is one side of a leaf of paper. It can be used as a measurement of documenting or recording quantity .-The page in typography:...
). A more modern example is a cassette tape (sequential—you have to fast-forward through earlier songs to get to later ones) and a CD (random access—you can skip to the track you want).
In data structure
Data structure
In computer science, a data structure is a particular way of storing and organizing data in a computer so that it can be used efficiently.Different kinds of data structures are suited to different kinds of applications, and some are highly specialized to specific tasks...
s, random access implies the ability to access any entry in a list of numbers in constant (i.e. independent of its position in the list and of list's size, i.e.
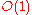
Big O notation
In mathematics, big O notation is used to describe the limiting behavior of a function when the argument tends towards a particular value or infinity, usually in terms of simpler functions. It is a member of a larger family of notations that is called Landau notation, Bachmann-Landau notation, or...
) time. Very few data structures can guarantee this, other than arrays (and related structures like dynamic array
Dynamic array
In computer science, a dynamic array, growable array, resizable array, dynamic table, or array list is a random access, variable-size list data structure that allows elements to be added or removed...
s). Random access is critical to many algorithms such as binary search, integer sorting
Integer sorting
In computer science, integer sorting is the algorithmic problem of sorting a collection of data values by numeric keys, each of which is an integer. Algorithms designed for integer sorting may also often be applied to sorting problems in which the keys are floating point numbers or text strings...
or sieve of Eratosthenes
Sieve of Eratosthenes
In mathematics, the sieve of Eratosthenes , one of a number of prime number sieves, is a simple, ancient algorithm for finding all prime numbers up to a specified integer....
. Other data structures, such as linked list
Linked list
In computer science, a linked list is a data structure consisting of a group of nodes which together represent a sequence. Under the simplest form, each node is composed of a datum and a reference to the next node in the sequence; more complex variants add additional links...
s, sacrifice random access to make for efficient inserts, deletes, or reordering of data. Self-balancing binary search tree
Self-balancing binary search tree
In computer science, a self-balancing binary search tree is any node based binary search tree that automatically keeps its height small in the face of arbitrary item insertions and deletions....
s may provide an acceptable compromise, where access time is equal for any member of a collection and only grows logarithmically with its size.