
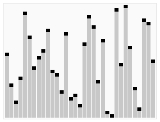
Quicksort
Overview
Sorting algorithm
In computer science, a sorting algorithm is an algorithm that puts elements of a list in a certain order. The most-used orders are numerical order and lexicographical order...
developed by Tony Hoare that, on average
Best, worst and average case
In computer science, best, worst and average cases of a given algorithm express what the resource usage is at least, at most and on average, respectively...
, makes
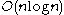 (big O notation
(big O notationBig O notation
In mathematics, big O notation is used to describe the limiting behavior of a function when the argument tends towards a particular value or infinity, usually in terms of simpler functions. It is a member of a larger family of notations that is called Landau notation, Bachmann-Landau notation, or...
) comparisons to sort n items. In the worst case
Best, worst and average case
In computer science, best, worst and average cases of a given algorithm express what the resource usage is at least, at most and on average, respectively...
, it makes
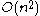 comparisons, though this behavior is rare. Quicksort is often faster in practice than other
comparisons, though this behavior is rare. Quicksort is often faster in practice than other 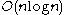 algorithms. Additionally, quicksort's sequential and localized memory references work well with a cache
algorithms. Additionally, quicksort's sequential and localized memory references work well with a cacheCache
In computer engineering, a cache is a component that transparently stores data so that future requests for that data can be served faster. The data that is stored within a cache might be values that have been computed earlier or duplicates of original values that are stored elsewhere...
.
Unanswered Questions