

Prediction interval
Encyclopedia
In statistical inference
, specifically predictive inference
, a prediction interval is an estimate of an interval in which future observations will fall, with a certain probability, given what has already been observed. Prediction intervals are often used in regression analysis
.
Prediction intervals are used in both frequentist statistics and Bayesian statistics
: a prediction interval bears the same relationship to a future observation that a frequentist confidence interval
or Bayesian credible interval
bears to an unobservable population parameter: prediction intervals predict the distribution of individual future points, whereas confidence intervals and credible intervals of parameters predict the distribution of estimates of the true population mean or other quantity of interest that cannot be observed.
that the underlying distribution is a normal distribution, and has a sample set {X1, ..., Xn}, then confidence intervals and credible intervals may be used to estimate the population mean μ and population standard deviation σ of the underlying population, while prediction intervals may be used to estimate the value of the next sample variable, Xn+1.
Alternatively, in Bayesian terms, a prediction interval can be described as a credible interval for the variable itself, rather than for a parameter of the distribution thereof.
The concept of prediction intervals need not be restricted to inference just a single future sample value but can be extended to more complicated cases. For example, in the context of river flooding where analyses are often based on annual values of the largest flow within the year, there may be interest in making inferences about the largest flood likely to be experienced within the next 50 years.
Since prediction intervals are only concerned with past and future observations, rather than unobservable population parameters, they are advocated as a better method than confidence intervals by some statisticians, such as Seymour Geisser
, following the focus on observables by Bruno de Finetti
.
method.
Suppose one randomly draws a sample of two observations X1 and X2 from a population in which values are assumed to have a continuous probability distribution
The answer is exactly 50%, regardless of the underlying population – the probability of picking 3 and then 7 is the same as picking 7 and then 3, regardless of the particular probability of picking 3 or 7. Thus, if one picks a single sample X1, then 50% of the time the next sample will be greater, which yields (X1, +∞) as a 50% prediction interval for X2. Similarly, 50% of the time it will be smaller, which yields another 50% prediction interval for X2, namely (−∞, X1). Note that the assumption of a continuous distribution avoids the possibililty that values might be exactly equal; this would complicate matters.
Similarly, if one has a sample {X1, ..., Xn} then the probability that the next observation Xn+1 will be the largest is 1/(n + 1), since all observations have equal probability of being the maximum. In the same way, the probability that Xn+1 will be the smallest is 1/(n + 1). The other (n − 1)/(n + 1) of the time, Xn+1 falls between the sample maximum and sample minimum of the sample {X1, ..., Xn}. Thus, denoting the sample maximum and minimum by M and m, this yields an (n − 1)/(n + 1) prediction interval of [m, M].
For example, if n = 19, then [m, M] gives an 18/20 = 90% prediction interval – 90% of the time, the 20th observation falls between the smallest and largest observation seen heretofore. Likewise, n = 39 gives a 95% prediction interval, and n = 199 gives a 99% prediction interval.
One can visualize this by drawing the n samples on a line, which divides the line into n + 1 sections (n − 1 segments between samples, and 2 intervals going to infinity at both ends), and noting that Xn+1 has an equal chance of landing in any of these n + 1 sections. Thus one can also pick any k of these sections and give a k/(n + 1) prediction interval (or set, if the sections are not consecutive). For instance, if n = 2, then the probability that X3 will land between the existing 2 observations in 1/3.
Notice that while this gives the probability that a future observation will fall in a range, it does not give any estimate as to where in a segment it will fall – notably, if it falls outside the range of observed values, it may be far outside the range. See extreme value theory
for further discussion. Formally, this applies not just to sampling from a population, but to any exchangeable sequence of random variables, not necessarily independent or identically distributed.
s".
A general technique of frequentist prediction intervals is to find and compute a pivotal quantity
of the observables X1, ..., Xn, Xn+1 – meaning a function of observables and parameters whose probability distribution does not depend on the parameters – that can be inverted to give a probability of the future observation Xn+1 falling in some interval computed in terms of the observed values so far,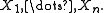 Such a pivotal quantity, depending only on observables, is called an ancillary statistic
Such a pivotal quantity, depending only on observables, is called an ancillary statistic
. The usual method of constructing pivotal quantities is to take the difference of two variables that depend on location, so that location cancels out, and then take the ratio of two variables that depend on scale, so that scale cancels out.
The most familiar pivotal quantity is the Student's t-statistic
, which can be derived by this method and is used in the sequel.
,σ2
) with known mean and variance, then one can compute prediction intervals either by standard score or by the quantile function:
Standard score
With known mean and known variance, prediction intervals can be calculated by subtracting from or adding to the mean (µ) with the standard deviation (σ) multiplied by a factor - the standard score
(z), that is specific for what prediction intervals are desired:
This is conventionally written as: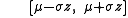
The corresponding standard scores to common prediction intervals are given in table at right.
For example, to calculate the 95% prediction interval for a normal distribution with a mean (µ) of 5 and a standard deviation (σ) of 1, then the, the lower limit of the prediction interval is approximately 5 ‒ (1·2) = 3, and the upper limit is approximately 7, thus giving a prediction interval of approximately 3 to 7.
Quantile function
An alternative method of calculating prediction intervals with known mean and variance is in terms of the quantile function
,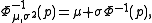 where
where 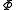 is the cumulative distribution function
is the cumulative distribution function
for the standard normal distribution. For instance, a symmetric 95% prediction interval is given by
Statistical inference
In statistics, statistical inference is the process of drawing conclusions from data that are subject to random variation, for example, observational errors or sampling variation...
, specifically predictive inference
Predictive inference
Predictive inference is an approach to statistical inference that emphasizes the prediction of future observations based on past observations.Initially, predictive inference was based on observable parameters and it was the main purpose of studying probability, but it fell out of favor in the 20th...
, a prediction interval is an estimate of an interval in which future observations will fall, with a certain probability, given what has already been observed. Prediction intervals are often used in regression analysis
Regression analysis
In statistics, regression analysis includes many techniques for modeling and analyzing several variables, when the focus is on the relationship between a dependent variable and one or more independent variables...
.
Prediction intervals are used in both frequentist statistics and Bayesian statistics
Bayesian statistics
Bayesian statistics is that subset of the entire field of statistics in which the evidence about the true state of the world is expressed in terms of degrees of belief or, more specifically, Bayesian probabilities...
: a prediction interval bears the same relationship to a future observation that a frequentist confidence interval
Confidence interval
In statistics, a confidence interval is a particular kind of interval estimate of a population parameter and is used to indicate the reliability of an estimate. It is an observed interval , in principle different from sample to sample, that frequently includes the parameter of interest, if the...
or Bayesian credible interval
Credible interval
In Bayesian statistics, a credible interval is an interval in the domain of a posterior probability distribution used for interval estimation. The generalisation to multivariate problems is the credible region...
bears to an unobservable population parameter: prediction intervals predict the distribution of individual future points, whereas confidence intervals and credible intervals of parameters predict the distribution of estimates of the true population mean or other quantity of interest that cannot be observed.
Introduction
For example, if one makes the parametric assumptionParametric statistics
Parametric statistics is a branch of statistics that assumes that the data has come from a type of probability distribution and makes inferences about the parameters of the distribution. Most well-known elementary statistical methods are parametric....
that the underlying distribution is a normal distribution, and has a sample set {X1, ..., Xn}, then confidence intervals and credible intervals may be used to estimate the population mean μ and population standard deviation σ of the underlying population, while prediction intervals may be used to estimate the value of the next sample variable, Xn+1.
Alternatively, in Bayesian terms, a prediction interval can be described as a credible interval for the variable itself, rather than for a parameter of the distribution thereof.
The concept of prediction intervals need not be restricted to inference just a single future sample value but can be extended to more complicated cases. For example, in the context of river flooding where analyses are often based on annual values of the largest flow within the year, there may be interest in making inferences about the largest flood likely to be experienced within the next 50 years.
Since prediction intervals are only concerned with past and future observations, rather than unobservable population parameters, they are advocated as a better method than confidence intervals by some statisticians, such as Seymour Geisser
Seymour Geisser
Seymour Geisser was a statistician noted for emphasizing the role of prediction in statistical inference – see predictive inference. In his book , he held that conventional statistical inference about unobservable population parameters amounts to inference about things that do not exist,...
, following the focus on observables by Bruno de Finetti
Bruno de Finetti
Bruno de Finetti was an Italian probabilist, statistician and actuary, noted for the "operational subjective" conception of probability...
.
Non-parametric
One can compute prediction intervals without any assumptions on the population; formally, this is a non-parametricNon-parametric statistics
In statistics, the term non-parametric statistics has at least two different meanings:The first meaning of non-parametric covers techniques that do not rely on data belonging to any particular distribution. These include, among others:...
method.
Suppose one randomly draws a sample of two observations X1 and X2 from a population in which values are assumed to have a continuous probability distribution
- What is the probability that X2 > X1?
The answer is exactly 50%, regardless of the underlying population – the probability of picking 3 and then 7 is the same as picking 7 and then 3, regardless of the particular probability of picking 3 or 7. Thus, if one picks a single sample X1, then 50% of the time the next sample will be greater, which yields (X1, +∞) as a 50% prediction interval for X2. Similarly, 50% of the time it will be smaller, which yields another 50% prediction interval for X2, namely (−∞, X1). Note that the assumption of a continuous distribution avoids the possibililty that values might be exactly equal; this would complicate matters.
Similarly, if one has a sample {X1, ..., Xn} then the probability that the next observation Xn+1 will be the largest is 1/(n + 1), since all observations have equal probability of being the maximum. In the same way, the probability that Xn+1 will be the smallest is 1/(n + 1). The other (n − 1)/(n + 1) of the time, Xn+1 falls between the sample maximum and sample minimum of the sample {X1, ..., Xn}. Thus, denoting the sample maximum and minimum by M and m, this yields an (n − 1)/(n + 1) prediction interval of [m, M].
For example, if n = 19, then [m, M] gives an 18/20 = 90% prediction interval – 90% of the time, the 20th observation falls between the smallest and largest observation seen heretofore. Likewise, n = 39 gives a 95% prediction interval, and n = 199 gives a 99% prediction interval.
One can visualize this by drawing the n samples on a line, which divides the line into n + 1 sections (n − 1 segments between samples, and 2 intervals going to infinity at both ends), and noting that Xn+1 has an equal chance of landing in any of these n + 1 sections. Thus one can also pick any k of these sections and give a k/(n + 1) prediction interval (or set, if the sections are not consecutive). For instance, if n = 2, then the probability that X3 will land between the existing 2 observations in 1/3.
Notice that while this gives the probability that a future observation will fall in a range, it does not give any estimate as to where in a segment it will fall – notably, if it falls outside the range of observed values, it may be far outside the range. See extreme value theory
Extreme value theory
Extreme value theory is a branch of statistics dealing with the extreme deviations from the median of probability distributions. The general theory sets out to assess the type of probability distributions generated by processes...
for further discussion. Formally, this applies not just to sampling from a population, but to any exchangeable sequence of random variables, not necessarily independent or identically distributed.
Normal distribution
Given a sample from a normal distribution, whose parameters are unknown, it is possible to given prediction intervals in the frequentist sense, i.e., an interval [a, b] based on statistics of the sample such that on repeated experiments, Xn+1 falls in the interval the desired percentage of the time; one may call these "predictive confidence intervalConfidence interval
In statistics, a confidence interval is a particular kind of interval estimate of a population parameter and is used to indicate the reliability of an estimate. It is an observed interval , in principle different from sample to sample, that frequently includes the parameter of interest, if the...
s".
A general technique of frequentist prediction intervals is to find and compute a pivotal quantity
Pivotal quantity
In statistics, a pivotal quantity or pivot is a function of observations and unobservable parameters whose probability distribution does not depend on unknown parameters....
of the observables X1, ..., Xn, Xn+1 – meaning a function of observables and parameters whose probability distribution does not depend on the parameters – that can be inverted to give a probability of the future observation Xn+1 falling in some interval computed in terms of the observed values so far,
Such a pivotal quantity, depending only on observables, is called an ancillary statisticAncillary statistic
In statistics, an ancillary statistic is a statistic whose sampling distribution does not depend on which of the probability distributions among those being considered is the distribution of the statistical population from which the data were taken...
. The usual method of constructing pivotal quantities is to take the difference of two variables that depend on location, so that location cancels out, and then take the ratio of two variables that depend on scale, so that scale cancels out.
The most familiar pivotal quantity is the Student's t-statistic
Student's t-statistic
In statistics, the t-statistic is a ratio of the departure of an estimated parameter from its notional value and its standard error. It is used in hypothesis testing, for example in the Student's t-test, in the augmented Dickey–Fuller test, and in bootstrapping.-Definition:Let \scriptstyle\hat\beta...
, which can be derived by this method and is used in the sequel.
Known mean, known variance
To begin, if one has a normal distribution N(µMean
In statistics, mean has two related meanings:* the arithmetic mean .* the expected value of a random variable, which is also called the population mean....
,σ2
Variance
In probability theory and statistics, the variance is a measure of how far a set of numbers is spread out. It is one of several descriptors of a probability distribution, describing how far the numbers lie from the mean . In particular, the variance is one of the moments of a distribution...
) with known mean and variance, then one can compute prediction intervals either by standard score or by the quantile function:
Standard score
With known mean and known variance, prediction intervals can be calculated by subtracting from or adding to the mean (µ) with the standard deviation (σ) multiplied by a factor - the standard score
Standard score
In statistics, a standard score indicates how many standard deviations an observation or datum is above or below the mean. It is a dimensionless quantity derived by subtracting the population mean from an individual raw score and then dividing the difference by the population standard deviation...
(z), that is specific for what prediction intervals are desired:
| Prediction interval | Standard score (z) |
|---|---|
| 50% | 0.67 |
| 90% | 1.64 |
| 95% | 1.96 |
| 99% | 2.58 |
- Lower limit of prediction interval = µ − σz
- Upper limit of prediction interval = µ + σz
This is conventionally written as:
The corresponding standard scores to common prediction intervals are given in table at right.
For example, to calculate the 95% prediction interval for a normal distribution with a mean (µ) of 5 and a standard deviation (σ) of 1, then the, the lower limit of the prediction interval is approximately 5 ‒ (1·2) = 3, and the upper limit is approximately 7, thus giving a prediction interval of approximately 3 to 7.
Quantile function
An alternative method of calculating prediction intervals with known mean and variance is in terms of the quantile function
Quantile function
In probability and statistics, the quantile function of the probability distribution of a random variable specifies, for a given probability, the value which the random variable will be at, or below, with that probability...
,
where is the cumulative distribution functionCumulative distribution function
In probability theory and statistics, the cumulative distribution function , or just distribution function, describes the probability that a real-valued random variable X with a given probability distribution will be found at a value less than or equal to x. Intuitively, it is the "area so far"...
for the standard normal distribution. For instance, a symmetric 95% prediction interval is given by
-
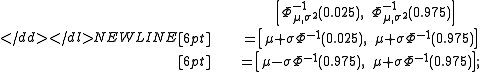
2.5% of the time a sample will fall to the left of this interval, 2.5% of the time it will fall to the right, and the rest of the time it will fall in the interval.
Estimation of parameters
For a distribution with unknown parameters,
a direct approach to prediction is to estimate the parameters and then use the associated quantile function – for example, one could use the sample mean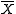 as estimate for μ and the sample variance s2 as an estimate for σ2. Note that there are two natural choices for s2 here – dividing by
as estimate for μ and the sample variance s2 as an estimate for σ2. Note that there are two natural choices for s2 here – dividing by  yields an unbiased estimate, while dividing by n yields the maximum likelihood estimator, and either might be used. One then uses the quantile function with these estimated parameters
yields an unbiased estimate, while dividing by n yields the maximum likelihood estimator, and either might be used. One then uses the quantile function with these estimated parameters 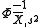 to give a prediction interval.
to give a prediction interval.
This approach is usable, but the resulting interval will not have the repeated sampling interpretation – it is not a predictive confidence interval.
For the sequel, use the sample mean:
and the (unbiased) sample variance:
Unknown mean, known variance
Given a normal distribution with unknown mean μ but known variance 1, the sample mean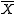 of the observations
of the observations  has distribution
has distribution  while the future observation
while the future observation  has distribution
has distribution 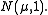 Taking the difference of these cancels the μ and yields a normal distribution of variance
Taking the difference of these cancels the μ and yields a normal distribution of variance 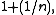 thus
thus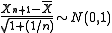
Solving for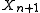 gives the prediction distribution
gives the prediction distribution  from which one can compute intervals as before. This is a predictive confidence interval in the sense that if one uses a quantile range of 100p%, then on repeated applications of this computation, the future observation
from which one can compute intervals as before. This is a predictive confidence interval in the sense that if one uses a quantile range of 100p%, then on repeated applications of this computation, the future observation  will fall in the predicted interval 100p% of the time.
will fall in the predicted interval 100p% of the time.
Notice that this prediction distribution is more conservative than using the estimated mean and known variance 1, as this uses variance
and known variance 1, as this uses variance  , hence yields wider intervals. This is necessary for the desired confidence interval property to hold.
, hence yields wider intervals. This is necessary for the desired confidence interval property to hold.
Known mean, unknown variance
Conversely, given a normal distribution with known mean 0 but unknown variance ,
,
the sample variance of the observations
of the observations 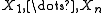 has, up to scale, a
has, up to scale, a  distribution; more precisely:
distribution; more precisely:
while the future observation has distribution
has distribution 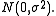
Taking the ratio of the future observation and the sample standard deviation cancels the σ, yielding a Student's t-distribution with n–1 degrees of freedomDegrees of freedom (statistics)In statistics, the number of degrees of freedom is the number of values in the final calculation of a statistic that are free to vary.Estimates of statistical parameters can be based upon different amounts of information or data. The number of independent pieces of information that go into the...
: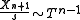
Solving for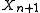 gives the prediction distribution
gives the prediction distribution 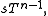 from which one can compute intervals as before.
from which one can compute intervals as before.
Notice that this prediction distribution is more conservative than using a normal distribution with the estimated standard deviation and known mean 0, as it uses the t-distribution instead of the normal distribution, hence yields wider intervals. This is necessary for the desired confidence interval property to hold.
and known mean 0, as it uses the t-distribution instead of the normal distribution, hence yields wider intervals. This is necessary for the desired confidence interval property to hold.
Unknown mean, unknown variance
Combining the above for a normal distribution with both μ and σ2 unknown yields the following ancillary statistic:
with both μ and σ2 unknown yields the following ancillary statistic:
This simple combination is possible because the sample mean and sample variance of the normal distribution are independent statistics; this is only true for the normal distribution, and in fact characterizes the normal distribution.
Solving for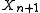 yields the prediction distribution
yields the prediction distribution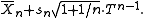
The probability of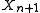 falling in a given interval is then:
falling in a given interval is then: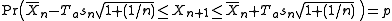
where Ta is the 100((1 + p)/2)th percentilePercentileIn statistics, a percentile is the value of a variable below which a certain percent of observations fall. For example, the 20th percentile is the value below which 20 percent of the observations may be found...
of Student's t-distribution with n − 1 degrees of freedom. Therefore the numbers

are the endpoints of a 100p% prediction interval for Xn + 1.
Contrast with parametric confidence intervals
Note that in the formula for the predictive confidence interval no mention is made of the unobservable parameters μ and σ of population mean and standard deviation – the observed sample statistics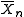 and
and 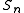 of sample mean and standard deviation are used, and what is estimated is the outcome of future samples.
of sample mean and standard deviation are used, and what is estimated is the outcome of future samples.
Rather than using sample statistics as estimators of population parameters and applying confidence intervals to these estimates, one considers "the next sample"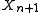 as itself a statistic, and computes its sampling distributionSampling distributionIn statistics, a sampling distribution or finite-sample distribution is the probability distribution of a given statistic based on a random sample. Sampling distributions are important in statistics because they provide a major simplification on the route to statistical inference...
as itself a statistic, and computes its sampling distributionSampling distributionIn statistics, a sampling distribution or finite-sample distribution is the probability distribution of a given statistic based on a random sample. Sampling distributions are important in statistics because they provide a major simplification on the route to statistical inference...
.
In parametric confidence intervals, one estimates population parameters;
if one wishes to interpret this as prediction of the next sample, one models "the next sample" as a draw from this estimated population, using the (estimated) population distribution. By contrast, in predictive confidence intervals, one uses the sampling distribution of (a statistic of) n or n+1 samples from such a population, and the population distribution is not directly used, though the assumption about its form (though not the values of its parameters) is used in computing the sampling distribution.
Regression analysis
A common application of prediction intervals is to regression analysisRegression analysisIn statistics, regression analysis includes many techniques for modeling and analyzing several variables, when the focus is on the relationship between a dependent variable and one or more independent variables...
.
Suppose the data is being modeled by a straight line regression:
where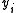 is the response variable,
is the response variable, 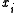 is the explanatory variable, εi is a random error term, and
is the explanatory variable, εi is a random error term, and  and
and 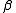 are parameters.
are parameters.
Given estimates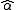 and
and  for the parameters, such as from a simple linear regressionSimple linear regressionIn statistics, simple linear regression is the least squares estimator of a linear regression model with a single explanatory variable. In other words, simple linear regression fits a straight line through the set of n points in such a way that makes the sum of squared residuals of the model as...
for the parameters, such as from a simple linear regressionSimple linear regressionIn statistics, simple linear regression is the least squares estimator of a linear regression model with a single explanatory variable. In other words, simple linear regression fits a straight line through the set of n points in such a way that makes the sum of squared residuals of the model as...
, the predicted response value yd for a given explanatory value xd is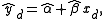
(the point on the regression line), while the actual response would be
The point estimate is called the mean response, and is an estimate of the expected valueExpected valueIn probability theory, the expected value of a random variable is the weighted average of all possible values that this random variable can take on...
is called the mean response, and is an estimate of the expected valueExpected valueIn probability theory, the expected value of a random variable is the weighted average of all possible values that this random variable can take on...
of yd,
A prediction interval instead gives an interval in which one expects yd to fall; this is not necessary if the actual parameters α and β are known (together with the error term εi), but if one is estimating from a sampleSampling (statistics)In statistics and survey methodology, sampling is concerned with the selection of a subset of individuals from within a population to estimate characteristics of the whole population....
, then one may use the standard errorStandard errorStandard error can refer to:* Standard error , the estimated standard deviation or error of a series of measurements* Standard error stream, one of the standard streams in Unix-like operating systems...
of the estimates for the intercept and slope ( and
and 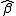 ) to compute a prediction interval.
) to compute a prediction interval.
Bayesian statistics
Seymour GeisserSeymour GeisserSeymour Geisser was a statistician noted for emphasizing the role of prediction in statistical inference – see predictive inference. In his book , he held that conventional statistical inference about unobservable population parameters amounts to inference about things that do not exist,...
, a proponent of predictive inference, gives predictive applications of Bayesian statisticsBayesian statisticsBayesian statistics is that subset of the entire field of statistics in which the evidence about the true state of the world is expressed in terms of degrees of belief or, more specifically, Bayesian probabilities...
.
In Bayesian statistics, one can compute (Bayesian) prediction intervals from the posterior probabilityPosterior probabilityIn Bayesian statistics, the posterior probability of a random event or an uncertain proposition is the conditional probability that is assigned after the relevant evidence is taken into account...
of the random variable, as a credible intervalCredible intervalIn Bayesian statistics, a credible interval is an interval in the domain of a posterior probability distribution used for interval estimation. The generalisation to multivariate problems is the credible region...
. In theoretical work, credible intervals are not often calculated for the prediction of future events, but for inference of parameters – i.e., credible intervals of a parameter, not for the outcomes of the variable itself. However, particularly where applications are concerned with possible extreme values of yet to be observed cases, credible intervals for such values can be of practical importance.
See also
- Confidence intervalConfidence intervalIn statistics, a confidence interval is a particular kind of interval estimate of a population parameter and is used to indicate the reliability of an estimate. It is an observed interval , in principle different from sample to sample, that frequently includes the parameter of interest, if the...
- ExtrapolationExtrapolationIn mathematics, extrapolation is the process of constructing new data points. It is similar to the process of interpolation, which constructs new points between known points, but the results of extrapolations are often less meaningful, and are subject to greater uncertainty. It may also mean...
- Posterior probabilityPosterior probabilityIn Bayesian statistics, the posterior probability of a random event or an uncertain proposition is the conditional probability that is assigned after the relevant evidence is taken into account...
- PredictionPredictionA prediction or forecast is a statement about the way things will happen in the future, often but not always based on experience or knowledge...
- Regression analysisRegression analysisIn statistics, regression analysis includes many techniques for modeling and analyzing several variables, when the focus is on the relationship between a dependent variable and one or more independent variables...
- Seymour GeisserSeymour GeisserSeymour Geisser was a statistician noted for emphasizing the role of prediction in statistical inference – see predictive inference. In his book , he held that conventional statistical inference about unobservable population parameters amounts to inference about things that do not exist,...
- Trend estimationTrend estimationTrend estimation is a statistical technique to aid interpretation of data. When a series of measurements of a process are treated as a time series, trend estimation can be used to make and justify statements about tendencies in the data...
Further reading
}}- ISO 16269-8 Standard Interpretation of Data, Part 8, Determination of Prediction Intervals
- Confidence interval