

Pattern recognition
Encyclopedia
In machine learning
, pattern recognition is the assignment of some sort of output value (or label) to a given input value (or instance), according to some specific algorithm. An example of pattern recognition is classification, which attempts to assign each input value to one of a given set of classes (for example, determine whether a given email is "spam" or "non-spam"). However, pattern recognition is a more general problem that encompasses other types of output as well. Other examples are regression
, which assigns a real-valued output to each input; sequence labeling
, which assigns a class to each member of a sequence of values (for example, part of speech tagging, which assigns a part of speech to each word in an input sentence); and parsing
, which assigns a parse tree
to an input sentence, describing the syntactic structure of the sentence.
Pattern recognition algorithms generally aim to provide a reasonable answer for all possible inputs and to do "fuzzy" matching of inputs. This is opposed to pattern matching
algorithms, which look for exact matches in the input with pre-existing patterns. A common example of a pattern-matching algorithm is regular expression
matching, which looks for patterns of a given sort in textual data and is included in the search capabilities of many text editor
s and word processor
s. In contrast to pattern recognition, pattern matching is generally not considered a type of machine learning, although pattern-matching algorithms (especially with fairly general, carefully tailored patterns) can sometimes succeed in providing similar-quality output to the sort provided by pattern-recognition algorithms.
Pattern recognition is studied in many fields, including psychology
, psychiatry
, ethology
, cognitive science
, traffic flow and computer science
.
assumes that a set of training data (the training set
) has been provided, consisting of a set of instances that have been properly labeled by hand with the correct output. A learning procedure then generates a model that attempts to meet two sometimes conflicting objectives: Perform as well as possible on the training data, and generalize as well as possible to new data (usually, this means being as simple as possible, for some technical definition of "simple", in accordance with Occam's Razor
). Unsupervised learning
, on the other hand, assumes training data that has not been hand-labeled, and attempts to find inherent patterns in the data that can then be used to determine the correct output value for new data instances. A combination of the two that has recently been explored is semi-supervised learning
, which uses a combination of labeled and unlabeled data (typically a small set of labeled data combined with a large amount of unlabeled data). Note that in cases of unsupervised learning, there may be no training data at all to speak of; in other words, the data to be labeled is the training data.
Note that sometimes different terms are used to describe the corresponding supervised and unsupervised learning procedures for the same type of output. For example, the unsupervised equivalent of classification is normally known as clustering
, based on the common perception of the task as involving no training data to speak of, and of grouping the input data into clusters based on some inherent similarity measure (e.g. the distance
between instances, considered as vectors in a multi-dimensional vector space
), rather than assigning each input instance into one of a set of pre-defined classes. Note also that in some fields, the terminology is different: For example, in community ecology, the term "classification" is used to refer to what is commonly known as "clustering".
The piece of input data for which an output value is generated is formally termed an instance. The instance is formally described by a vector
of features, which together constitute a description of all known characteristics of the instance. (These feature vectors can be seen as defining points in an appropriate multidimensional space, and methods for manipulating vectors in vector space
s can be correspondingly applied to them, such as computing the dot product
or the angle between two vectors.) Typically, features are either categorical
(also known as nominal, i.e. consisting of one of a set of unordered items, such as a gender of "male" or "female", or a blood type of "A", "B", "AB" or "O"), ordinal (consisting of one of a set of ordered items, e.g. "large", "medium" or "small"), integer-valued
(e.g. a count of the number of occurrences of a particular word in an email) or real-valued
(e.g. a measurement of blood pressure). Often, categorical and ordinal data are grouped together; likewise for integer-valued and real-valued data. Furthermore, many algorithms work only in terms of categorical data and require that real-valued or integer-valued data be discretized into groups (e.g. less than 5, between 5 and 10, or greater than 10).
Many common pattern recognition algorithms are probabilistic in nature, in that they use statistical inference
to find the best label for a given instance. Unlike other algorithms, which simply output a "best" label, oftentimes probabilistic algorithms also output a probability
of the instance being described by the given label. In addition, many probabilistic algorithms output a list of the N-best labels with associated probabilities, for some value of N, instead of simply a single best label. When the number of possible labels is fairly small (e.g. in the case of classification), N may be set so that the probability of all possible labels is output. Probabilistic algorithms have many advantages over non-probabilistic algorithms:
Techniques to transform the raw feature vectors are sometimes used prior to application of the pattern-matching algorithm. For example, feature extraction
algorithms attempt to reduce a large-dimensionality feature vector into a smaller-dimensionality vector that is easier to work with and encodes less redundancy, using mathematical techniques such as principal components analysis
(PCA). Feature selection
algorithms, attempt to directly prune out redundant or irrelevant features. The distinction between the two is that the resulting features after feature extraction has taken place are of a different sort than the original features and may not easily be interpretable, while the features left after feature selection are simply a subset of the original features.
pattern recognition can be stated as follows: Given an unknown function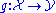 (the ground truth) that maps input instances
(the ground truth) that maps input instances 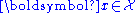 to output labels
to output labels 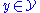 , along with training data
, along with training data  assumed to represent accurate examples of the mapping, produce a function
assumed to represent accurate examples of the mapping, produce a function 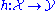 that approximates as closely as possible the correct mapping
that approximates as closely as possible the correct mapping  . (For example, if the problem is filtering spam, then
. (For example, if the problem is filtering spam, then  is some representation of an email and
is some representation of an email and 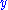 is either "spam" or "non-spam"). In order for this to be a well-defined problem, "approximates as closely as possible" needs to be defined rigorously. In decision theory
is either "spam" or "non-spam"). In order for this to be a well-defined problem, "approximates as closely as possible" needs to be defined rigorously. In decision theory
, this is defined by specifying a loss function
that assigns a specific value to "loss" resulting from producing an incorrect label. The goal then is to minimize the expected
loss, with the expectation taken over the probability distribution
of . In practice, neither the distribution of
. In practice, neither the distribution of  nor the ground truth function
nor the ground truth function 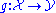 are known exactly, but can be computed only empirically by collecting a large number of samples of
are known exactly, but can be computed only empirically by collecting a large number of samples of  and hand-labeling them using the correct value of
and hand-labeling them using the correct value of 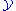 (a time-consuming process, which is typically the limiting factor in the amount of data of this sort that can be collected). The particular loss function depends on the type of label being predicted. For example, in the case of classification, the simple zero-one loss function is often sufficient. This corresponds simply to assigning a loss of 1 to any incorrect labeling and is equivalent to computing the accuracy of the classification procedure over the set of test data (i.e. counting up the fraction of instances that the learned function
(a time-consuming process, which is typically the limiting factor in the amount of data of this sort that can be collected). The particular loss function depends on the type of label being predicted. For example, in the case of classification, the simple zero-one loss function is often sufficient. This corresponds simply to assigning a loss of 1 to any incorrect labeling and is equivalent to computing the accuracy of the classification procedure over the set of test data (i.e. counting up the fraction of instances that the learned function 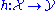 labels correctly. The goal of the learning procedure is to maximize this test accuracy on a "typical" test set.
labels correctly. The goal of the learning procedure is to maximize this test accuracy on a "typical" test set.
For a probabilistic pattern recognizer, the problem is instead to estimate the probability of each possible output label given a particular input instance, i.e. to estimate a function of the form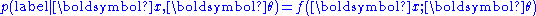
where the feature vector
input is , and the function f is typically parameterized by some parameters
, and the function f is typically parameterized by some parameters 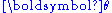 . In a discriminative
. In a discriminative
approach to the problem, f is estimated directly. In a generative
approach, however, the inverse probability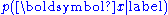 is instead estimated and combined with the prior probability
is instead estimated and combined with the prior probability
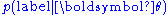 using Bayes' rule
using Bayes' rule
, as follows: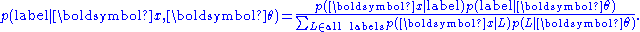
When the labels are continuously distributed (e.g. in regression analysis
), the denominator involves integration
rather than summation:
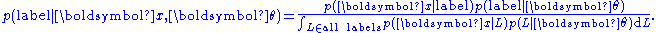
The value of is typically learned using maximum a posteriori
is typically learned using maximum a posteriori
(MAP) estimation. This finds the best value that simultaneously meets two conflicting objects: To perform as well as possible on the training data and to find the simplest possible model. Essentially, this combines maximum likelihood
estimation with a regularization
procedure that favors simpler models over more complex models. In a Bayesian
context, the regularization procedure can be viewed as placing a prior probability
 on different values of
on different values of  . Mathematically:
. Mathematically:
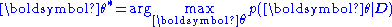
where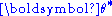 is the value used for
is the value used for 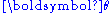 in the subsequent evaluation procedure, and
in the subsequent evaluation procedure, and  , the posterior probability
, the posterior probability
of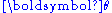 , is given by
, is given by
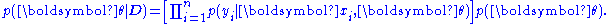
In the Bayesian
approach to this problem, instead of choosing a single parameter vector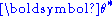 , the probability of a given label for a new instance
, the probability of a given label for a new instance  is computed by integrating over all possible values of
is computed by integrating over all possible values of  , weighted according to the posterior probability:
, weighted according to the posterior probability:
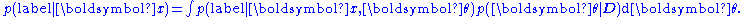
(CAD) systems. CAD describes a procedure that supports the doctor's interpretations and findings.
Typical applications are automatic speech recognition
, classification of text into several categories
(e.g. spam/non-spam email messages), the automatic recognition of handwritten postal codes
on postal envelopes, automatic recognition of images
of human faces, or handwriting image extraction from medical forms. The last two examples form the subtopic image analysis
of pattern recognition that deals with digital images as input to pattern recognition systems.
The method of signing one's name was captured with stylus and overlay starting 1990. The strokes, speed, relative min, relative max, acceleration and pressure is used to uniquely identify and confirm identity. Banks were first offered this technology, but were content to collect from the FDIC for any bank fraud and didn't want to inconvenience customers..
or discriminative
.
Classification algorithms (supervised
Clustering algorithms (unsupervised
Regression
Supervised:
Unsupervised:
Categorical sequence labeling
Supervised:
Unsupervised:
Real-valued sequence labeling
Supervised (?):
Unsupervised:
Parsing
Supervised and unsupervised:
Ensemble learning
Machine learning
Machine learning, a branch of artificial intelligence, is a scientific discipline concerned with the design and development of algorithms that allow computers to evolve behaviors based on empirical data, such as from sensor data or databases...
, pattern recognition is the assignment of some sort of output value (or label) to a given input value (or instance), according to some specific algorithm. An example of pattern recognition is classification, which attempts to assign each input value to one of a given set of classes (for example, determine whether a given email is "spam" or "non-spam"). However, pattern recognition is a more general problem that encompasses other types of output as well. Other examples are regression
Regression analysis
In statistics, regression analysis includes many techniques for modeling and analyzing several variables, when the focus is on the relationship between a dependent variable and one or more independent variables...
, which assigns a real-valued output to each input; sequence labeling
Sequence labeling
In machine learning, sequence labeling is a type of pattern recognition task that involves the algorithmic assignment of a categorical label to each member of a sequence of observed values. A common example of a sequence labeling task is part of speech tagging, which seeks to assign a part of...
, which assigns a class to each member of a sequence of values (for example, part of speech tagging, which assigns a part of speech to each word in an input sentence); and parsing
Parsing
In computer science and linguistics, parsing, or, more formally, syntactic analysis, is the process of analyzing a text, made of a sequence of tokens , to determine its grammatical structure with respect to a given formal grammar...
, which assigns a parse tree
Parse tree
A concrete syntax tree or parse tree or parsing treeis an ordered, rooted tree that represents the syntactic structure of a string according to some formal grammar. In a parse tree, the interior nodes are labeled by non-terminals of the grammar, while the leaf nodes are labeled by terminals of the...
to an input sentence, describing the syntactic structure of the sentence.
Pattern recognition algorithms generally aim to provide a reasonable answer for all possible inputs and to do "fuzzy" matching of inputs. This is opposed to pattern matching
Pattern matching
In computer science, pattern matching is the act of checking some sequence of tokens for the presence of the constituents of some pattern. In contrast to pattern recognition, the match usually has to be exact. The patterns generally have the form of either sequences or tree structures...
algorithms, which look for exact matches in the input with pre-existing patterns. A common example of a pattern-matching algorithm is regular expression
Regular expression
In computing, a regular expression provides a concise and flexible means for "matching" strings of text, such as particular characters, words, or patterns of characters. Abbreviations for "regular expression" include "regex" and "regexp"...
matching, which looks for patterns of a given sort in textual data and is included in the search capabilities of many text editor
Text editor
A text editor is a type of program used for editing plain text files.Text editors are often provided with operating systems or software development packages, and can be used to change configuration files and programming language source code....
s and word processor
Word processor
A word processor is a computer application used for the production of any sort of printable material....
s. In contrast to pattern recognition, pattern matching is generally not considered a type of machine learning, although pattern-matching algorithms (especially with fairly general, carefully tailored patterns) can sometimes succeed in providing similar-quality output to the sort provided by pattern-recognition algorithms.
Pattern recognition is studied in many fields, including psychology
Psychology
Psychology is the study of the mind and behavior. Its immediate goal is to understand individuals and groups by both establishing general principles and researching specific cases. For many, the ultimate goal of psychology is to benefit society...
, psychiatry
Psychiatry
Psychiatry is the medical specialty devoted to the study and treatment of mental disorders. These mental disorders include various affective, behavioural, cognitive and perceptual abnormalities...
, ethology
Ethology
Ethology is the scientific study of animal behavior, and a sub-topic of zoology....
, cognitive science
Cognitive science
Cognitive science is the interdisciplinary scientific study of mind and its processes. It examines what cognition is, what it does and how it works. It includes research on how information is processed , represented, and transformed in behaviour, nervous system or machine...
, traffic flow and computer science
Computer science
Computer science or computing science is the study of the theoretical foundations of information and computation and of practical techniques for their implementation and application in computer systems...
.
Overview
Pattern recognition is generally categorized according to the type of learning procedure used to generate the output value. Supervised learningSupervised learning
Supervised learning is the machine learning task of inferring a function from supervised training data. The training data consist of a set of training examples. In supervised learning, each example is a pair consisting of an input object and a desired output value...
assumes that a set of training data (the training set
Training set
A training set is a set of data used in various areas of information science to discover potentially predictive relationships. Training sets are used in artificial intelligence, machine learning, genetic programming, intelligent systems, and statistics...
) has been provided, consisting of a set of instances that have been properly labeled by hand with the correct output. A learning procedure then generates a model that attempts to meet two sometimes conflicting objectives: Perform as well as possible on the training data, and generalize as well as possible to new data (usually, this means being as simple as possible, for some technical definition of "simple", in accordance with Occam's Razor
Occam's razor
Occam's razor, also known as Ockham's razor, and sometimes expressed in Latin as lex parsimoniae , is a principle that generally recommends from among competing hypotheses selecting the one that makes the fewest new assumptions.-Overview:The principle is often summarized as "simpler explanations...
). Unsupervised learning
Unsupervised learning
In machine learning, unsupervised learning refers to the problem of trying to find hidden structure in unlabeled data. Since the examples given to the learner are unlabeled, there is no error or reward signal to evaluate a potential solution...
, on the other hand, assumes training data that has not been hand-labeled, and attempts to find inherent patterns in the data that can then be used to determine the correct output value for new data instances. A combination of the two that has recently been explored is semi-supervised learning
Semi-supervised learning
In computer science, semi-supervised learning is a class of machine learning techniques that make use of both labeled and unlabeled data for training - typically a small amount of labeled data with a large amount of unlabeled data...
, which uses a combination of labeled and unlabeled data (typically a small set of labeled data combined with a large amount of unlabeled data). Note that in cases of unsupervised learning, there may be no training data at all to speak of; in other words, the data to be labeled is the training data.
Note that sometimes different terms are used to describe the corresponding supervised and unsupervised learning procedures for the same type of output. For example, the unsupervised equivalent of classification is normally known as clustering
Data clustering
Cluster analysis or clustering is the task of assigning a set of objects into groups so that the objects in the same cluster are more similar to each other than to those in other clusters....
, based on the common perception of the task as involving no training data to speak of, and of grouping the input data into clusters based on some inherent similarity measure (e.g. the distance
Distance
Distance is a numerical description of how far apart objects are. In physics or everyday discussion, distance may refer to a physical length, or an estimation based on other criteria . In mathematics, a distance function or metric is a generalization of the concept of physical distance...
between instances, considered as vectors in a multi-dimensional vector space
Vector space
A vector space is a mathematical structure formed by a collection of vectors: objects that may be added together and multiplied by numbers, called scalars in this context. Scalars are often taken to be real numbers, but one may also consider vector spaces with scalar multiplication by complex...
), rather than assigning each input instance into one of a set of pre-defined classes. Note also that in some fields, the terminology is different: For example, in community ecology, the term "classification" is used to refer to what is commonly known as "clustering".
The piece of input data for which an output value is generated is formally termed an instance. The instance is formally described by a vector
Feature vector
In pattern recognition and machine learning, a feature vector is an n-dimensional vector of numerical features that represent some object. Many algorithms in machine learning require a numerical representation of objects, since such representations facilitate processing andstatistical analysis...
of features, which together constitute a description of all known characteristics of the instance. (These feature vectors can be seen as defining points in an appropriate multidimensional space, and methods for manipulating vectors in vector space
Vector space
A vector space is a mathematical structure formed by a collection of vectors: objects that may be added together and multiplied by numbers, called scalars in this context. Scalars are often taken to be real numbers, but one may also consider vector spaces with scalar multiplication by complex...
s can be correspondingly applied to them, such as computing the dot product
Dot product
In mathematics, the dot product or scalar product is an algebraic operation that takes two equal-length sequences of numbers and returns a single number obtained by multiplying corresponding entries and then summing those products...
or the angle between two vectors.) Typically, features are either categorical
Categorical data
In statistics, categorical data is that part of an observed dataset that consists of categorical variables, or for data that has been converted into that form, for example as grouped data...
(also known as nominal, i.e. consisting of one of a set of unordered items, such as a gender of "male" or "female", or a blood type of "A", "B", "AB" or "O"), ordinal (consisting of one of a set of ordered items, e.g. "large", "medium" or "small"), integer-valued
Integer
The integers are formed by the natural numbers together with the negatives of the non-zero natural numbers .They are known as Positive and Negative Integers respectively...
(e.g. a count of the number of occurrences of a particular word in an email) or real-valued
Real number
In mathematics, a real number is a value that represents a quantity along a continuum, such as -5 , 4/3 , 8.6 , √2 and π...
(e.g. a measurement of blood pressure). Often, categorical and ordinal data are grouped together; likewise for integer-valued and real-valued data. Furthermore, many algorithms work only in terms of categorical data and require that real-valued or integer-valued data be discretized into groups (e.g. less than 5, between 5 and 10, or greater than 10).
Many common pattern recognition algorithms are probabilistic in nature, in that they use statistical inference
Statistical inference
In statistics, statistical inference is the process of drawing conclusions from data that are subject to random variation, for example, observational errors or sampling variation...
to find the best label for a given instance. Unlike other algorithms, which simply output a "best" label, oftentimes probabilistic algorithms also output a probability
Probability
Probability is ordinarily used to describe an attitude of mind towards some proposition of whose truth we arenot certain. The proposition of interest is usually of the form "Will a specific event occur?" The attitude of mind is of the form "How certain are we that the event will occur?" The...
of the instance being described by the given label. In addition, many probabilistic algorithms output a list of the N-best labels with associated probabilities, for some value of N, instead of simply a single best label. When the number of possible labels is fairly small (e.g. in the case of classification), N may be set so that the probability of all possible labels is output. Probabilistic algorithms have many advantages over non-probabilistic algorithms:
- They output a confidence value associated with their choice. (Note that some other algorithms may also output confidence values, but in general, only for probabilistic algorithms is this value mathematically grounded in probability theoryProbability theoryProbability theory is the branch of mathematics concerned with analysis of random phenomena. The central objects of probability theory are random variables, stochastic processes, and events: mathematical abstractions of non-deterministic events or measured quantities that may either be single...
. Non-probabilistic confidence values can in general not be given any specific meaning, and only used to compare against other confidence values output by the same algorithm.) - Correspondingly, they can abstain when the confidence of choosing any particular output is too low.
- Because of the probabilities output, probabilistic pattern-recognition algorithms can be more effectively incorporated into larger machine-learning tasks, in a way that partially or completely avoids the problem of error propagation.
Techniques to transform the raw feature vectors are sometimes used prior to application of the pattern-matching algorithm. For example, feature extraction
Feature extraction
In pattern recognition and in image processing, feature extraction is a special form of dimensionality reduction.When the input data to an algorithm is too large to be processed and it is suspected to be notoriously redundant then the input data will be transformed into a reduced representation...
algorithms attempt to reduce a large-dimensionality feature vector into a smaller-dimensionality vector that is easier to work with and encodes less redundancy, using mathematical techniques such as principal components analysis
Principal components analysis
Principal component analysis is a mathematical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of uncorrelated variables called principal components. The number of principal components is less than or equal to...
(PCA). Feature selection
Feature selection
In machine learning and statistics, feature selection, also known as variable selection, feature reduction, attribute selection or variable subset selection, is the technique of selecting a subset of relevant features for building robust learning models...
algorithms, attempt to directly prune out redundant or irrelevant features. The distinction between the two is that the resulting features after feature extraction has taken place are of a different sort than the original features and may not easily be interpretable, while the features left after feature selection are simply a subset of the original features.
Problem statement (supervised version)
Formally, the problem of supervisedSupervised learning
Supervised learning is the machine learning task of inferring a function from supervised training data. The training data consist of a set of training examples. In supervised learning, each example is a pair consisting of an input object and a desired output value...
pattern recognition can be stated as follows: Given an unknown function
(the ground truth) that maps input instances to output labels , along with training data assumed to represent accurate examples of the mapping, produce a function that approximates as closely as possible the correct mapping . (For example, if the problem is filtering spam, then is some representation of an email and is either "spam" or "non-spam"). In order for this to be a well-defined problem, "approximates as closely as possible" needs to be defined rigorously. In decision theoryDecision theory
Decision theory in economics, psychology, philosophy, mathematics, and statistics is concerned with identifying the values, uncertainties and other issues relevant in a given decision, its rationality, and the resulting optimal decision...
, this is defined by specifying a loss function
Loss function
In statistics and decision theory a loss function is a function that maps an event onto a real number intuitively representing some "cost" associated with the event. Typically it is used for parameter estimation, and the event in question is some function of the difference between estimated and...
that assigns a specific value to "loss" resulting from producing an incorrect label. The goal then is to minimize the expected
Expected value
In probability theory, the expected value of a random variable is the weighted average of all possible values that this random variable can take on...
loss, with the expectation taken over the probability distribution
Probability distribution
In probability theory, a probability mass, probability density, or probability distribution is a function that describes the probability of a random variable taking certain values....
of
. In practice, neither the distribution of nor the ground truth function are known exactly, but can be computed only empirically by collecting a large number of samples of and hand-labeling them using the correct value of (a time-consuming process, which is typically the limiting factor in the amount of data of this sort that can be collected). The particular loss function depends on the type of label being predicted. For example, in the case of classification, the simple zero-one loss function is often sufficient. This corresponds simply to assigning a loss of 1 to any incorrect labeling and is equivalent to computing the accuracy of the classification procedure over the set of test data (i.e. counting up the fraction of instances that the learned function labels correctly. The goal of the learning procedure is to maximize this test accuracy on a "typical" test set.For a probabilistic pattern recognizer, the problem is instead to estimate the probability of each possible output label given a particular input instance, i.e. to estimate a function of the form
where the feature vector
Feature vector
In pattern recognition and machine learning, a feature vector is an n-dimensional vector of numerical features that represent some object. Many algorithms in machine learning require a numerical representation of objects, since such representations facilitate processing andstatistical analysis...
input is
, and the function f is typically parameterized by some parameters . In a discriminativeDiscriminative model
Discriminative models are a class of models used in machine learning for modeling the dependence of an unobserved variable y on an observed variable x...
approach to the problem, f is estimated directly. In a generative
Generative model
In probability and statistics, a generative model is a model for randomly generating observable data, typically given some hidden parameters. It specifies a joint probability distribution over observation and label sequences...
approach, however, the inverse probability
is instead estimated and combined with the prior probabilityPrior probability
In Bayesian statistical inference, a prior probability distribution, often called simply the prior, of an uncertain quantity p is the probability distribution that would express one's uncertainty about p before the "data"...
using Bayes' ruleBayes' rule
In probability theory and applications, Bayes' rule relates the odds of event A_1 to event A_2, before and after conditioning on event B. The relationship is expressed in terms of the Bayes factor, \Lambda. Bayes' rule is derived from and closely related to Bayes' theorem...
, as follows:
When the labels are continuously distributed (e.g. in regression analysis
Regression analysis
In statistics, regression analysis includes many techniques for modeling and analyzing several variables, when the focus is on the relationship between a dependent variable and one or more independent variables...
), the denominator involves integration
Integral
Integration is an important concept in mathematics and, together with its inverse, differentiation, is one of the two main operations in calculus...
rather than summation:
The value of
is typically learned using maximum a posterioriMaximum a posteriori
In Bayesian statistics, a maximum a posteriori probability estimate is a mode of the posterior distribution. The MAP can be used to obtain a point estimate of an unobserved quantity on the basis of empirical data...
(MAP) estimation. This finds the best value that simultaneously meets two conflicting objects: To perform as well as possible on the training data and to find the simplest possible model. Essentially, this combines maximum likelihood
Maximum likelihood
In statistics, maximum-likelihood estimation is a method of estimating the parameters of a statistical model. When applied to a data set and given a statistical model, maximum-likelihood estimation provides estimates for the model's parameters....
estimation with a regularization
Regularization (mathematics)
In mathematics and statistics, particularly in the fields of machine learning and inverse problems, regularization involves introducing additional information in order to solve an ill-posed problem or to prevent overfitting...
procedure that favors simpler models over more complex models. In a Bayesian
Bayesian inference
In statistics, Bayesian inference is a method of statistical inference. It is often used in science and engineering to determine model parameters, make predictions about unknown variables, and to perform model selection...
context, the regularization procedure can be viewed as placing a prior probability
Prior probability
In Bayesian statistical inference, a prior probability distribution, often called simply the prior, of an uncertain quantity p is the probability distribution that would express one's uncertainty about p before the "data"...
on different values of . Mathematically:where
is the value used for in the subsequent evaluation procedure, and , the posterior probabilityPosterior probability
In Bayesian statistics, the posterior probability of a random event or an uncertain proposition is the conditional probability that is assigned after the relevant evidence is taken into account...
of
, is given byIn the Bayesian
Bayesian statistics
Bayesian statistics is that subset of the entire field of statistics in which the evidence about the true state of the world is expressed in terms of degrees of belief or, more specifically, Bayesian probabilities...
approach to this problem, instead of choosing a single parameter vector
, the probability of a given label for a new instance is computed by integrating over all possible values of , weighted according to the posterior probability:Uses
Within medical science, pattern recognition is the basis for computer-aided diagnosisComputer-aided diagnosis
Computer-aided detection and computer-aided diagnosis are procedures in medicine that assist doctors in the interpretation of medical images. Imaging techniques in X-ray, MRI, and Ultrasound diagnostics yield a great deal of information, which the radiologist has to analyze and evaluate...
(CAD) systems. CAD describes a procedure that supports the doctor's interpretations and findings.
Typical applications are automatic speech recognition
Speech recognition
Speech recognition converts spoken words to text. The term "voice recognition" is sometimes used to refer to recognition systems that must be trained to a particular speaker—as is the case for most desktop recognition software...
, classification of text into several categories
Document classification
Document classification or document categorization is a problem in both library science, information science and computer science. The task is to assign a document to one or more classes or categories. This may be done "manually" or algorithmically...
(e.g. spam/non-spam email messages), the automatic recognition of handwritten postal codes
Handwriting recognition
Handwriting recognition is the ability of a computer to receive and interpret intelligible handwritten input from sources such as paper documents, photographs, touch-screens and other devices. The image of the written text may be sensed "off line" from a piece of paper by optical scanning or...
on postal envelopes, automatic recognition of images
Facial recognition system
A facial recognition system is a computer application for automatically identifying or verifying a person from a digital image or a video frame from a video source...
of human faces, or handwriting image extraction from medical forms. The last two examples form the subtopic image analysis
Image analysis
Image analysis is the extraction of meaningful information from images; mainly from digital images by means of digital image processing techniques...
of pattern recognition that deals with digital images as input to pattern recognition systems.
The method of signing one's name was captured with stylus and overlay starting 1990. The strokes, speed, relative min, relative max, acceleration and pressure is used to uniquely identify and confirm identity. Banks were first offered this technology, but were content to collect from the FDIC for any bank fraud and didn't want to inconvenience customers..
Algorithms
Algorithms for pattern recognition depend on the type of label output, on whether learning is supervised or unsupervised, and on whether the algorithm is statistical or non-statistical in nature. Statistical algorithms can further be categorized as generativeGenerative model
In probability and statistics, a generative model is a model for randomly generating observable data, typically given some hidden parameters. It specifies a joint probability distribution over observation and label sequences...
or discriminative
Discriminative model
Discriminative models are a class of models used in machine learning for modeling the dependence of an unobserved variable y on an observed variable x...
.
Classification algorithms (supervisedSupervised learningSupervised learning is the machine learning task of inferring a function from supervised training data. The training data consist of a set of training examples. In supervised learning, each example is a pair consisting of an input object and a desired output value...
algorithms predicting categoricalCategorical dataIn statistics, categorical data is that part of an observed dataset that consists of categorical variables, or for data that has been converted into that form, for example as grouped data...
labels)
- Maximum entropy classifier (aka logistic regressionLogistic regressionIn statistics, logistic regression is used for prediction of the probability of occurrence of an event by fitting data to a logit function logistic curve. It is a generalized linear model used for binomial regression...
, multinomial logistic regression): Note that logistic regression is an algorithm for classification, despite its name. (The name comes from the fact that logistic regression uses an extension of a linear regression model to model the probability of an input being in a particular class.) - Naive Bayes classifierNaive Bayes classifierA naive Bayes classifier is a simple probabilistic classifier based on applying Bayes' theorem with strong independence assumptions...
- Decision treeDecision treeA decision tree is a decision support tool that uses a tree-like graph or model of decisions and their possible consequences, including chance event outcomes, resource costs, and utility. It is one way to display an algorithm. Decision trees are commonly used in operations research, specifically...
s, decision lists - Support vector machineSupport vector machineA support vector machine is a concept in statistics and computer science for a set of related supervised learning methods that analyze data and recognize patterns, used for classification and regression analysis...
s - Kernel estimation and K-nearest-neighbor algorithms
- PerceptronPerceptronThe perceptron is a type of artificial neural network invented in 1957 at the Cornell Aeronautical Laboratory by Frank Rosenblatt. It can be seen as the simplest kind of feedforward neural network: a linear classifier.- Definition :...
s - Neural networkNeural networkThe term neural network was traditionally used to refer to a network or circuit of biological neurons. The modern usage of the term often refers to artificial neural networks, which are composed of artificial neurons or nodes...
s (multi-level perceptrons)
Clustering algorithms (unsupervisedUnsupervised learningIn machine learning, unsupervised learning refers to the problem of trying to find hidden structure in unlabeled data. Since the examples given to the learner are unlabeled, there is no error or reward signal to evaluate a potential solution...
algorithms predicting categoricalCategorical dataIn statistics, categorical data is that part of an observed dataset that consists of categorical variables, or for data that has been converted into that form, for example as grouped data...
labels)
- Categorical mixture modelMixture modelIn statistics, a mixture model is a probabilistic model for representing the presence of sub-populations within an overall population, without requiring that an observed data-set should identify the sub-population to which an individual observation belongs...
s - K-means clustering
- Hierarchical clusteringHierarchical clusteringIn statistics, hierarchical clustering is a method of cluster analysis which seeks to build a hierarchy of clusters. Strategies for hierarchical clustering generally fall into two types:...
(agglomerative or divisive) - Kernel principal component analysis (Kernel PCA)
RegressionRegression analysisIn statistics, regression analysis includes many techniques for modeling and analyzing several variables, when the focus is on the relationship between a dependent variable and one or more independent variables...
algorithms (predicting real-valuedReal numberIn mathematics, a real number is a value that represents a quantity along a continuum, such as -5 , 4/3 , 8.6 , √2 and π...
labels)
Supervised:
- Linear regressionLinear regressionIn statistics, linear regression is an approach to modeling the relationship between a scalar variable y and one or more explanatory variables denoted X. The case of one explanatory variable is called simple regression...
and extensions - Neural networkNeural networkThe term neural network was traditionally used to refer to a network or circuit of biological neurons. The modern usage of the term often refers to artificial neural networks, which are composed of artificial neurons or nodes...
s - Gaussian process regression (kriging)
Unsupervised:
- Principal components analysisPrincipal components analysisPrincipal component analysis is a mathematical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of uncorrelated variables called principal components. The number of principal components is less than or equal to...
(PCA) - Independent component analysisIndependent component analysisIndependent component analysis is a computational method for separating a multivariate signal into additive subcomponents supposing the mutual statistical independence of the non-Gaussian source signals...
(ICA)
Categorical sequence labelingSequence labelingIn machine learning, sequence labeling is a type of pattern recognition task that involves the algorithmic assignment of a categorical label to each member of a sequence of observed values. A common example of a sequence labeling task is part of speech tagging, which seeks to assign a part of...
algorithms (predicting sequences of categoricalCategorical dataIn statistics, categorical data is that part of an observed dataset that consists of categorical variables, or for data that has been converted into that form, for example as grouped data...
labels)
Supervised:
- Hidden Markov modelHidden Markov modelA hidden Markov model is a statistical Markov model in which the system being modeled is assumed to be a Markov process with unobserved states. An HMM can be considered as the simplest dynamic Bayesian network. The mathematics behind the HMM was developed by L. E...
s (HMMs) - Maximum entropy Markov modelMaximum entropy Markov modelIn machine learning, a maximum-entropy Markov model , or conditional Markov model , is a graphical model for sequence labeling that combines features of hidden Markov models and maximum entropy models...
s (MEMMs) - Conditional random fieldConditional random fieldA conditional random field is a statistical modelling method often applied in pattern recognition.More specifically it is a type of discriminative undirected probabilistic graphical model. It is used to encode known relationships between observations and construct consistent interpretations...
s (CRFs)
Unsupervised:
- Hidden Markov modelHidden Markov modelA hidden Markov model is a statistical Markov model in which the system being modeled is assumed to be a Markov process with unobserved states. An HMM can be considered as the simplest dynamic Bayesian network. The mathematics behind the HMM was developed by L. E...
s (HMMs)
Real-valued sequence labelingSequence labelingIn machine learning, sequence labeling is a type of pattern recognition task that involves the algorithmic assignment of a categorical label to each member of a sequence of observed values. A common example of a sequence labeling task is part of speech tagging, which seeks to assign a part of...
algorithms (predicting sequences of real-valuedReal numberIn mathematics, a real number is a value that represents a quantity along a continuum, such as -5 , 4/3 , 8.6 , √2 and π...
labels)
Supervised (?):
- Kalman filterKalman filterIn statistics, the Kalman filter is a mathematical method named after Rudolf E. Kálmán. Its purpose is to use measurements observed over time, containing noise and other inaccuracies, and produce values that tend to be closer to the true values of the measurements and their associated calculated...
s - Particle filterParticle filterIn statistics, particle filters, also known as Sequential Monte Carlo methods , are sophisticated model estimation techniques based on simulation...
s
Unsupervised:
ParsingParsingIn computer science and linguistics, parsing, or, more formally, syntactic analysis, is the process of analyzing a text, made of a sequence of tokens , to determine its grammatical structure with respect to a given formal grammar...
algorithms (predicting tree structureTree structureA tree structure is a way of representing the hierarchical nature of a structure in a graphical form. It is named a "tree structure" because the classic representation resembles a tree, even though the chart is generally upside down compared to an actual tree, with the "root" at the top and the...
d labels)
Supervised and unsupervised:
- Probabilistic context free grammars (PCFGs)
General algorithms for predicting arbitrarily-structured labels
- Bayesian networkBayesian networkA Bayesian network, Bayes network, belief network or directed acyclic graphical model is a probabilistic graphical model that represents a set of random variables and their conditional dependencies via a directed acyclic graph . For example, a Bayesian network could represent the probabilistic...
s - Markov random fields
Ensemble learningEnsemble learningIn statistics and machine learning, ensemble methods use multiple models to obtain better predictive performance than could be obtained from any of the constituent models....
algorithms (supervised meta-algorithms for combining multiple learning algorithms together)
- Bootstrap aggregatingBootstrap aggregatingBootstrap aggregating is a machine learning ensemble meta-algorithm to improve machine learning of statistical classification and regression models in terms of stability and classification accuracy. It also reduces variance and helps to avoid overfitting. Although it is usually applied to decision...
("bagging") - BoostingBoostingBoosting is a machine learning meta-algorithm for performing supervised learning. Boosting is based on the question posed by Kearns: can a set of weak learners create a single strong learner? A weak learner is defined to be a classifier which is only slightly correlated with the true classification...
- Ensemble averagingEnsemble AveragingIn machine learning, particularly in the creation of artificial neural networks, ensemble averaging is the process of creating multiple models and combining them to produce a desired output, as opposed to creating just one model...
- Mixture of experts, hierarchical mixture of experts
See also
- Cache language modelCache language modelA cache language model is a type of statistical language model. These occur in the natural language processing subfield of computer science and assign probabilities to given sequences of words by means of a probability distribution...
- Compound term processingCompound term processingCompound term processing is the name that is used for a category of techniques in Information retrieval applications that performs matching on the basis of compound terms...
- Computer-aided diagnosisComputer-aided diagnosisComputer-aided detection and computer-aided diagnosis are procedures in medicine that assist doctors in the interpretation of medical images. Imaging techniques in X-ray, MRI, and Ultrasound diagnostics yield a great deal of information, which the radiologist has to analyze and evaluate...
- Data miningData miningData mining , a relatively young and interdisciplinary field of computer science is the process of discovering new patterns from large data sets involving methods at the intersection of artificial intelligence, machine learning, statistics and database systems...
- List of numerical analysis software
- List of numerical libraries
- Machine learningMachine learningMachine learning, a branch of artificial intelligence, is a scientific discipline concerned with the design and development of algorithms that allow computers to evolve behaviors based on empirical data, such as from sensor data or databases...
- NeocognitronNeocognitronThe neocognitron is a hierarchical multilayered neural network proposed by Professor Kunihiko Fukushima. It has been used for handwritten character recognition and other pattern recognition tasks....
- Predictive analyticsPredictive analyticsPredictive analytics encompasses a variety of statistical techniques from modeling, machine learning, data mining and game theory that analyze current and historical facts to make predictions about future events....
- Prior knowledge for pattern recognitionPrior knowledge for pattern recognitionPattern recognition is a very active field of research intimately bound to machine learning. Also known as classification or statistical classification, pattern recognition aims at building a classifier that can determine the class of an input pattern...
- Template matchingTemplate matchingTemplate matching is a technique in digital image processing for finding small parts of an image which match a template image. It can be used in manufacturing as a part of quality control, a way to navigate a mobile robot, or as a way to detect edges in images....
- Thin-slicingThin-slicingThin-slicing is a term used in psychology and philosophy to describe the ability to find patterns in events based only on "thin slices," or narrow windows, of experience...
- PerceptionPerceptionPerception is the process of attaining awareness or understanding of the environment by organizing and interpreting sensory information. All perception involves signals in the nervous system, which in turn result from physical stimulation of the sense organs...