Computer science or computing science is the study of the theoretical foundations of information and computation and of practical techniques for their implementation and application in computer systems...
, a binary search or half-interval searchalgorithm
Algorithm
In mathematics and computer science, an algorithm is an effective method expressed as a finite list of well-defined instructions for calculating a function. Algorithms are used for calculation, data processing, and automated reasoning...
In computer science, an index can be:# an integer that identifies an array element# a data structure that enables sublinear-time lookup -Array element identifier:...
of a specified value (the input "key") within a sorted array
Sorted array
A sorted array is an array data structure in which each element is sorted in numerical, alphabetical, or some other order, and placed at equally spaced addresses in computer memory. It is typically used in computer science to implement static lookup tables to hold multiple values which has the same...
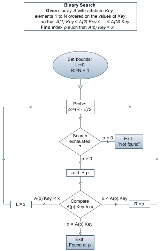
. At each stage, the algorithm compares the input key value with the key value of the middle element of the array. If the keys match, then a matching element has been found so its index, or position, is returned. Otherwise, if the sought key is less than the middle element's key, then the algorithm repeats its action on the sub-array to the left of the middle element or, if the input key is greater, on the sub-array to the right. If the remaining array to be searched is reduced to zero, then the key cannot be found in the array and a special "Not found" indication is returned.
A binary search halves the number of items to check with each iteration, so locating an item (or determining its absence) takes logarithmic time. A binary search is a dichotomic
Dichotomic search
In computer science, a dichotomic search is a search algorithm that operates by selecting between two distinct alternatives at each step. It is a specific type of divide and conquer algorithm...
In computer science, divide and conquer is an important algorithm design paradigm based on multi-branched recursion. A divide and conquer algorithm works by recursively breaking down a problem into two or more sub-problems of the same type, until these become simple enough to be solved directly...
In computer science, a search algorithm is an algorithm for finding an item with specified properties among a collection of items. The items may be stored individually as records in a database; or may be elements of a search space defined by a mathematical formula or procedure, such as the roots...
.
Overview
Searching a sorted collection is a common task. A dictionary is a sorted list of word definitions. Given a word, one can find its definition. A telephone book is a sorted list of people's names, addresses, and telephone numbers. Knowing someone's name allows one to quickly find their telephone number and address.
If the list to be searched contains more than a few items (a dozen, say) a binary search will require far fewer comparisons than a linear search
Linear search
In computer science, linear search or sequential search is a method for finding a particular value in a list, that consists of checking every one of its elements, one at a time and in sequence, until the desired one is found....
, but it imposes the requirement that the list be sorted. Similarly, a hash search
Hash table
In computer science, a hash table or hash map is a data structure that uses a hash function to map identifying values, known as keys , to their associated values . Thus, a hash table implements an associative array...
can be faster than a binary search but imposes still greater requirements. If the contents of the array are modified between searches, maintaining these requirements may take more time than the searches! And if it is known that some items will be searched for much more often than others, and it can be arranged that these items are at the start of the list, then a linear search may be the best.
Number guessing game
This rather simple game begins something like "I'm thinking of an integer between forty and sixty inclusive, and to your guesses I'll respond 'High', 'Low', or 'Yes!' as might be the case."
Supposing that N is the number of possible values (here, twenty-one as "inclusive" was stated), then at most questions are required to determine the number, since each question halves the search space. Note that one less question (iteration) is required than for the general algorithm, since the number is already constrained to be within a particular range.
Even if the number to guess can be arbitrarily large, in which case there is no upper bound N, The number can be found in at most steps (where k is the (unknown) selected number) by first finding an upper bound by repeated doubling. For example, if the number were 11, the following sequence of guesses could be used to find it: 1, 2, 4, 8, 16, 12, 10, 11
One could also extend the method to include negative numbers; for example the following guesses could be used to find −13: 0, −1, −2, −4, −8, −16, −12, −14, −13.
Interpolation search is an algorithm for searching for a given key value in an indexed array that has been ordered by the values of the key. It parallels how humans search through a telephone book for a particular name, the key value by which the book's entries are ordered...
algorithms when searching a telephone book, after the initial guess we exploit the fact that the entries are sorted and can rapidly find the required entry. For example when searching for Smith, if Rogers and Thomas have been found, one can flip to a page about halfway between the previous guesses. If this shows Samson, it can be concluded that Smith is somewhere between the Samson and Thomas pages so these can be divided.
Applications to complexity theory
Even if we do not know a fixed range the number k falls in, we can still determine its value by asking simple yes/no questions of the form "Is k greater than x?" for some number x. As a simple consequence of this, if you can answer the question "Is this integer property k greater than a given value?" in some amount of time then you can find the value of that property in the same amount of time with an added factor of . This is called a reduction
Reduction (complexity)
In computability theory and computational complexity theory, a reduction is a transformation of one problem into another problem. Depending on the transformation used this can be used to define complexity classes on a set of problems....
, and it is because of this kind of reduction that most complexity theorists concentrate on decision problem
Decision problem
In computability theory and computational complexity theory, a decision problem is a question in some formal system with a yes-or-no answer, depending on the values of some input parameters. For example, the problem "given two numbers x and y, does x evenly divide y?" is a decision problem...
s, algorithms that produce a simple yes/no answer.
For example, suppose we could answer "Does this n x n matrix have determinant
Determinant
In linear algebra, the determinant is a value associated with a square matrix. It can be computed from the entries of the matrix by a specific arithmetic expression, while other ways to determine its value exist as well...
larger than k?" in O(n2) time. Then, by using binary search, we could find the (ceiling of the) determinant itself in O(n2log d) time, where d is the determinant; notice that d is not the size of the input, but the size of the output.
Performance
With each test that fails to find a match at the probed position, the search is continued with one or other of the two sub-intervals, each at most half the size. More precisely, if the number of items, N, is odd then both sub-intervals will contain (N - 1)/2 elements, while if N is even then the two sub-intervals contain N/2 - 1 and N/2 elements.
If the original number of items is N then after the first iteration there will be at most N/2 items remaining, then at most N/4 items, at most N/8 items, and so on. In the worst case, when the value is not in the list, the algorithm must continue iterating until the span has been made empty; this will have taken at most ⌊log2
Binary logarithm
In mathematics, the binary logarithm is the logarithm to the base 2. It is the inverse function of n ↦ 2n. The binary logarithm of n is the power to which the number 2 must be raised to obtain the value n. This makes the binary logarithm useful for anything involving powers of 2,...
(N) + 1⌋ iterations, where the ⌊ ⌋ notation denotes the floor function
Floor function
In mathematics and computer science, the floor and ceiling functions map a real number to the largest previous or the smallest following integer, respectively...
that rounds its argument down to an integer. This worst case analysis is tight: for any N there exists a query that takes exactly ⌊log2
Binary logarithm
In mathematics, the binary logarithm is the logarithm to the base 2. It is the inverse function of n ↦ 2n. The binary logarithm of n is the power to which the number 2 must be raised to obtain the value n. This makes the binary logarithm useful for anything involving powers of 2,...
In computer science, linear search or sequential search is a method for finding a particular value in a list, that consists of checking every one of its elements, one at a time and in sequence, until the desired one is found....
, whose worst-case behaviour is N iterations, we see that binary search is substantially faster as N grows large. For example, to search a list of one million items takes as many as one million iterations with linear search, but never more than twenty iterations with binary search. However, a binary search can only be performed if the list is in sorted order.
Average performance
is the expected number of probes in an average successful search, and the worst case is , just one more probe. If the list is empty, no probes at all are made.
Thus binary search is a logarithmic algorithm and executes in O()
Big O notation
In mathematics, big O notation is used to describe the limiting behavior of a function when the argument tends towards a particular value or infinity, usually in terms of simpler functions. It is a member of a larger family of notations that is called Landau notation, Bachmann-Landau notation, or...
time. In most cases it is considerably faster than a linear search
Linear search
In computer science, linear search or sequential search is a method for finding a particular value in a list, that consists of checking every one of its elements, one at a time and in sequence, until the desired one is found....
Iteration means the act of repeating a process usually with the aim of approaching a desired goal or target or result. Each repetition of the process is also called an "iteration," and the results of one iteration are used as the starting point for the next iteration.-Mathematics:Iteration in...
Recursion is the process of repeating items in a self-similar way. For instance, when the surfaces of two mirrors are exactly parallel with each other the nested images that occur are a form of infinite recursion. The term has a variety of meanings specific to a variety of disciplines ranging from...
. In some languages it is more elegantly expressed recursively; however, in some C-based languages tail recursion is not eliminated and the recursive version requires more stack space.
Binary search can interact poorly with the memory hierarchy (i.e. caching
Cache
In computer engineering, a cache is a component that transparently stores data so that future requests for that data can be served faster. The data that is stored within a cache might be values that have been computed earlier or duplicates of original values that are stored elsewhere...
), because of its random-access nature. For in-memory searching, if the span to be searched is small, a linear search may have superior performance simply because it exhibits better locality of reference. For external searching, care must be taken or each of the first several probes will lead to a disk seek. A common method is to abandon binary searching for linear searching as soon as the size of the remaining span falls below a small value such as 8 or 16 or even more in recent computers. The exact value depends entirely on the machine running the algorithm.
Notice that for multiple searches with a fixed value for N, then (with the appropriate regard for integer division), the first iteration always selects the middle element at N/2, and the second always selects either N/4 or 3N/4, and so on. Thus if the array's key values are in some sort of slow storage (on a disc file, in virtual memory, not in the cpu's on-chip memory), keeping those three keys in a local array for a special preliminary search will avoid accessing widely separated memory. Escalating to seven or fifteen such values will allow further levels at not much cost in storage. On the other hand, if the searches are frequent and not separated by much other activity, the computer's various storage control features will more or less automatically promote frequently-accessed elements into faster storage.
When multiple binary searches are to be performed for the same key in related lists, fractional cascading
Fractional cascading
In computer science, fractional cascading is a technique to speed up a sequence of binary searches for the same value in a sequence of related data structures. The first binary search in the sequence takes a logarithmic amount of time, as is standard for binary searches, but successive searches in...
can be used to speed up successive searches after the first one.
Extensions
There is no particular requirement that the array being searched has the bounds 1 to N. It is possible to search a specified range, elements first to last instead of 1 to N. All that is necessary is that the initialisation of the bounds be L:=first − 1 and R:=last + 1, then all proceeds as before.
The elements of the list are not necessarily all unique. If one searches for a value that occurs multiple times in the list, the index returned will be of the first-encountered equal element, and this will not necessarily be that of the first, last, or middle element of the run of equal-key elements but will depend on the positions of the values. Modifying the list even in seemingly unrelated ways such as adding elements elsewhere in the list may change the result.
To find all equal elements an upward and downward linear search can be carried out from the initial result, stopping each search when the element is no longer equal. Thus, e.g. in a table of cities sorted by country, we can find all cities in a given country.
Several algorithms closely related to or extending binary search exist. For instance, noisy binary search solves the same class of projects as regular binary search, with the added complexity that any given test can return a false value at random. (Usually, the number of such erroneous results are bounded in some way, either in the form of an average error rate, or in the total number of errors allowed per element in the search space.) Optimal algorithms for several classes of noisy binary search problems have been known since the late seventies, and more recently, optimal algorithms for noisy binary search in quantum computers (where several elements can be tested at the same time) have been discovered.
Variations
There are many, and they are easily confused. Also, using a binary search within a sorting method is debatable.
Exclusive or inclusive bounds
The most significant differences are between the "exclusive" and "inclusive" forms of the bounds. In the "exclusive" bound form the span to be searched is (L + 1) to (R − 1), and this may seem clumsy when the span to be searched could be described in the "inclusive" form, as L to R. Although the details differ the two forms are equivalent as can be seen by transforming one version into the other. The inclusive bound form may be attained by replacing all appearances of "L" by "(L − 1)" and "R" by "(R + 1)" then rearranging. Thus, the initialisation of L:=0 becomes (L − 1):=0 or L:=1, and R:=N + 1 becomes (R + 1):=N + 1 or R:=N. So far so good, but note now that the changes to L and R are no longer simply transferring the value of p to L or R as appropriate but now must be (R + 1):=p or R:=p − 1, and (L − 1):=p or L:=p + 1.
Thus, the gain of a simpler initialisation, done once, is lost by a more complex calculation, and which is done for every iteration. If that is not enough, the test for an empty span is more complex also, as compared to the simplicity of checking that the value of p is zero. Nevertheless, the inclusive bound form is found in many publications, such as Donald Knuth
Donald Knuth
Donald Ervin Knuth is a computer scientist and Professor Emeritus at Stanford University.He is the author of the seminal multi-volume work The Art of Computer Programming. Knuth has been called the "father" of the analysis of algorithms...
. The Art of Computer Programming, Volume 3: Sorting and Searching, Third Edition.
Deferred detection of equality
Because of the syntax difficulties discussed below, so that distinguishing the three states <, =, and > would have to be done with two comparisons, it is possible to use just one comparison and at the end when the span is reduced to zero, equality can be tested for. The solution distinguishes only < from >=.
Midpoint and width
An entirely different variation involves abandoning the L and R pointers in favour of a current position p and a width w where at each iteration, p is adjusted by + or − w and w is halved. Professor Knuth remarks "It is possible to do this, but only if extreme care is paid to the details" – Section 6.2.1, page 414 of The Art of Computer Programming, Volume 3: Sorting and Searching, Third Edition, outlines an algorithm, with the further remark "Simpler approaches are doomed to failure!"
The algorithm
Although the basic idea of binary search is comparatively straightforward, the details can be surprisingly tricky… — Professor Donald Knuth
Donald Knuth
Donald Ervin Knuth is a computer scientist and Professor Emeritus at Stanford University.He is the author of the seminal multi-volume work The Art of Computer Programming. Knuth has been called the "father" of the analysis of algorithms...
Jon Louis Bentley is a researcher in the field of computer science. He is credited with the invention of the k-d tree....
assigned it as a problem in a course for professional programmers, he found that an astounding ninety percent failed to code a binary search correctly after several hours of working on it, and another study shows that accurate code for it is only found in five out of twenty textbooks. Furthermore, Bentley's own implementation of binary search, published in his 1986 book Programming Pearls, contains an error that remained undetected for over twenty years.
Numerical difficulties
In a practical implementation, the variables used to represent the indices will be of finite size, hence only capable of representing a finite range of values. For example, 32-bit unsigned integers
Signedness
In computing, signedness is a property of data types representing numbers in computer programs. A numeric variable is signed if it can represent both positive and negative numbers, and unsigned if it can only represent non-negative numbers .As signed numbers can represent negative numbers, they...
can only hold values from 0 to 4294967295. Most binary search algorithms use 32-bit signed integers, which can only hold values from -2147483648 to 2147483647. If the binary search algorithm is to operate on large arrays, this has two implications:
The values first − 1 and last + 1 must both be representable within the finite bounds of the chosen integer type . Therefore, continuing the 32-bit unsigned example, the largest value that last may take is +4294967294, not +4294967295. A problem exists even for the "inclusive" form of the method, as if x > A(4294967295).Key, then on the final iteration the algorithm will attempt to store 4294967296 into L and fail. Equivalent issues apply to the lower limit, where first − 1 could become negative as when the first element of the array is at index zero.
If the midpoint of the span is calculated as p := (L + R)/2, then the value (L + R) will exceed the number range if last is greater than (for unsigned) 4294967295/2 or (for signed) 2147483647/2 and the search wanders toward the upper end of the search space. This can be avoided by performing the calculation as p := (R - L)/2 + L. When the problem arises for signed integers, a more efficient alternative is by performing the calculation as p := (R + L) >>> 1, where >>> denotes the right logical shift
Logical shift
In computer science, a logical shift is a bitwise operation that shifts all the bits of its operand. Unlike an arithmetic shift, a logical shift does not preserve a number's sign bit or distinguish a number's exponent from its mantissa; every bit in the operand is simply moved a given number of bit...
operator. For example, this bug existed in Java SDK at Arrays.binarySearch from 1.2 to 5.0 and fixed in 6.0.
Iterative
The following incorrect (see notes below) algorithm is slightly modified (to avoid overflow) from Niklaus Wirth
Niklaus Wirth
Niklaus Emil Wirth is a Swiss computer scientist, best known for designing several programming languages, including Pascal, and for pioneering several classic topics in software engineering. In 1984 he won the Turing Award for developing a sequence of innovative computer languages.-Biography:Wirth...
Pascal is an influential imperative and procedural programming language, designed in 1968/9 and published in 1970 by Niklaus Wirth as a small and efficient language intended to encourage good programming practices using structured programming and data structuring.A derivative known as Object Pascal...
:
min := 1;
max := N; {array size: var A : array [1..N] of integer}
repeat
mid := (min+max) div 2;
if x > A[mid] then
min := mid + 1;
else
max := mid - 1;
until (A[mid] = x) or (min > max);
Note: This code assumes 1-based array indexing. For languages that use 0-based indexing (most modern languages), min and max should be initialized to 0 and N-1.
Note 2: The code above does not return a result, nor indicates whether the element was found or not.
Note 3: The code above will not work correctly for empty arrays, because it attempts to access an element before checking to see if min > max.
Note 4: After exiting the loop, the value of mid does not properly indicate whether the desired value was found in the array. One would need to perform one more comparison to determine if the value A[mid] is equal to x.
This code uses inclusive bounds and a three-way test (for early loop termination in case of equality), but with two separate comparisons per iteration. It is not the most efficient solution.
Recursive
A simple, straightforward implementation is tail recursive; it recursively searches the subrange dictated by the comparison:
binary_search(Array[0..N-1], value, low, high):
if (high < low):
return -1 // not found
mid = (low + high) / 2
if (A[mid] > value):
return binary_search(A, value, low, mid-1)
else if (A[mid] < value):
return binary_search(A, value, mid+1, high)
else:
return mid // found
It is invoked with initial low and high values of 0 and N-1.
Language support
Many standard libraries provide a way to do a binary search:
C is a general-purpose computer programming language developed between 1969 and 1973 by Dennis Ritchie at the Bell Telephone Laboratories for use with the Unix operating system....
provides algorithm function bsearch in its standard library.
C++ is a statically typed, free-form, multi-paradigm, compiled, general-purpose programming language. It is regarded as an intermediate-level language, as it comprises a combination of both high-level and low-level language features. It was developed by Bjarne Stroustrup starting in 1979 at Bell...
The Standard Template Library is a C++ software library which later evolved into the C++ Standard Library. It provides four components called algorithms, containers, functors, and iterators. More specifically, the C++ Standard Library is based on the STL published by SGI. Both include some...
provides algorithm functions binary_search, lower_bound and upper_bound.
Java is a programming language originally developed by James Gosling at Sun Microsystems and released in 1995 as a core component of Sun Microsystems' Java platform. The language derives much of its syntax from C and C++ but has a simpler object model and fewer low-level facilities...
offers a set of overloaded binarySearch static methods in the classes and in the standard java.util package for performing binary searches on Java arrays and on Lists, respectively. They must be arrays of primitives, or the arrays or Lists must be of a type that implements the Comparable interface, or you must specify a custom Comparator object.
Microsoft Corporation is an American public multinational corporation headquartered in Redmond, Washington, USA that develops, manufactures, licenses, and supports a wide range of products and services predominantly related to computing through its various product divisions...
The .NET Framework is a software framework that runs primarily on Microsoft Windows. It includes a large library and supports several programming languages which allows language interoperability...
In a broad definition, generic programming is a style of computer programming in which algorithms are written in terms of to-be-specified-later types that are then instantiated when needed for specific types provided as parameters...
versions of the binary search algorithm in its collection base classes. An example would be System.Array's method BinarySearch(T[] array, T value).
Python is a general-purpose, high-level programming language whose design philosophy emphasizes code readability. Python claims to "[combine] remarkable power with very clear syntax", and its standard library is large and comprehensive...
COBOL is one of the oldest programming languages. Its name is an acronym for COmmon Business-Oriented Language, defining its primary domain in business, finance, and administrative systems for companies and governments....
can perform binary search on internal tables using the SEARCH ALL statement.
Perl is a high-level, general-purpose, interpreted, dynamic programming language. Perl was originally developed by Larry Wall in 1987 as a general-purpose Unix scripting language to make report processing easier. Since then, it has undergone many changes and revisions and become widely popular...
can perform a generic binary search using the CPAN
CPAN
CPAN, the Comprehensive Perl Archive Network, is an archive of nearly 100,000 modules of software written in Perl, as well as documentation for it. It has a presence on the World Wide Web at and is mirrored worldwide at more than 200 locations...
Go is a compiled, garbage-collected, concurrent programming language developed by Google Inc.The initial design of Go was started in September 2007 by Robert Griesemer, Rob Pike, and Ken Thompson. Go was officially announced in November 2009. In May 2010, Rob Pike publicly stated that Go was being...
's sort standard library package contains functions Search, SearchInts, SearchFloat64s, and SearchStrings, which implement general binary search, as well as specific implementations for searching slices of integers, floating-point numbers, and strings, respectively.http://golang.org/pkg/sort/
Objective-C is a reflective, object-oriented programming language that adds Smalltalk-style messaging to the C programming language.Today, it is used primarily on Apple's Mac OS X and iOS: two environments derived from the OpenStep standard, though not compliant with it...
Cocoa is Apple's native object-oriented application programming interface for the Mac OS X operating system and—along with the Cocoa Touch extension for gesture recognition and animation—for applications for the iOS operating system, used on Apple devices such as the iPhone, the iPod Touch, and...
Interpolation search is an algorithm for searching for a given key value in an indexed array that has been ordered by the values of the key. It parallels how humans search through a telephone book for a particular name, the key value by which the book's entries are ordered...
In computer science, an index can be:# an integer that identifies an array element# a data structure that enables sublinear-time lookup -Array element identifier:...
, very fast 'lookup' using an index to directly select an entry
In computer programming, a branch table is a term used to describe an efficient method of transferring program control to another part of a program using a table of branch instructions. It is a form of multiway branch...
, alternative indexed 'lookup' method for decision making
In computer science, a self-balancing binary search tree is any node based binary search tree that automatically keeps its height small in the face of arbitrary item insertions and deletions....
Run-time analysis, illustrating binary search method on machines of differing speeds
The bisection method in mathematics is a root-finding method which repeatedly bisects an interval and then selects a subinterval in which a root must lie for further processing. It is a very simple and robust method, but it is also relatively slow...
, the same idea used to solve equations in the real numbers

 questions are required to determine the number, since each question halves the search space. Note that one less question (iteration) is required than for the general algorithm, since the number is already constrained to be within a particular range.
questions are required to determine the number, since each question halves the search space. Note that one less question (iteration) is required than for the general algorithm, since the number is already constrained to be within a particular range.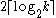 steps (where k is the (unknown) selected number) by first finding an upper bound by repeated doubling. For example, if the number were 11, the following sequence of guesses could be used to find it: 1, 2, 4, 8, 16, 12, 10, 11
steps (where k is the (unknown) selected number) by first finding an upper bound by repeated doubling. For example, if the number were 11, the following sequence of guesses could be used to find it: 1, 2, 4, 8, 16, 12, 10, 11 simple yes/no questions of the form "Is k greater than x?" for some number x. As a simple consequence of this, if you can answer the question "Is this integer property k greater than a given value?" in some amount of time then you can find the value of that property in the same amount of time with an added factor of
simple yes/no questions of the form "Is k greater than x?" for some number x. As a simple consequence of this, if you can answer the question "Is this integer property k greater than a given value?" in some amount of time then you can find the value of that property in the same amount of time with an added factor of 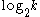 . This is called a reduction
. This is called a reduction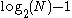 is the expected number of probes in an average successful search, and the worst case is
is the expected number of probes in an average successful search, and the worst case is 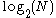 , just one more probe. If the list is empty, no probes at all are made.
, just one more probe. If the list is empty, no probes at all are made. )
)